知识蒸馏IRG算法实战:使用ResNet50蒸馏ResNet18
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识蒸馏IRG算法实战:使用ResNet50蒸馏ResNet18相关的知识,希望对你有一定的参考价值。
摘要
复杂度的检测模型虽然可以取得SOTA的精度,但它们往往难以直接落地应用。模型压缩方法帮助模型在效率和精度之间进行折中。知识蒸馏是模型压缩的一种有效手段,它的核心思想是迫使轻量级的学生模型去学习教师模型提取到的知识,从而提高学生模型的性能。已有的知识蒸馏方法可以分别为三大类:
- 基于特征的(feature-based,例如VID、NST、FitNets、fine-grained feature imitation)
- 基于关系的(relation-based,例如IRG、Relational KD、CRD、similarity-preserving knowledge distillation)
- 基于响应的(response-based,例如Hinton的知识蒸馏开山之作。

今天我们就尝试用基于关系的IRG知识蒸馏算法完成这篇实战。IRG蒸馏是对模型里面的的Block和展平层做蒸馏,所以需要返回每个block层的值和展平层的值。所以我们对模型要做修改来适应IRG算法,并且为了使Teacher和Student的网络层之间的参数一致,我们这次选用ResNet50作为Teacher模型,选择ResNet18作为Student。
最终结论
先把结论说了吧! Teacher网络使用ResNet50 ,Student网络使用ResNet18。如下表
| 网络 | epochs | ACC |
|---|---|---|
| ResNet50 | 100 | 86% |
| ResNet18 | 100 | 89% |
| ResNet18 +IRG | 100 | 89% |
这个结论有点意外,ResNet50 和ResNet18 模型都是我自己写的。我尝试了ResNet151和ResNet102,这两个模型的结果和ResNet50差不多,都是86%左右,相反,ResNet18 却有89%的准确率。ResNet18 +IRG的准确率也是89%。
模型
模型没有用pytorch官方自带的,而是参照以前总结的ResNet模型修改的。ResNet模型结构如下图:
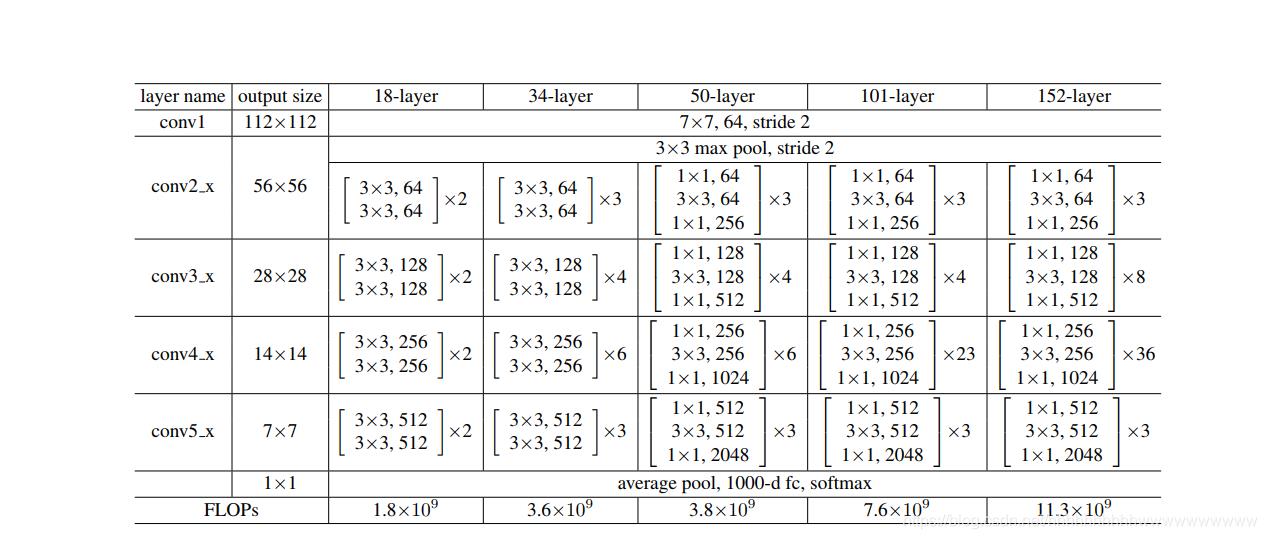
ResNet18, ResNet34
ResNet18, ResNet34模型的残差结构是一致的,结构如下:
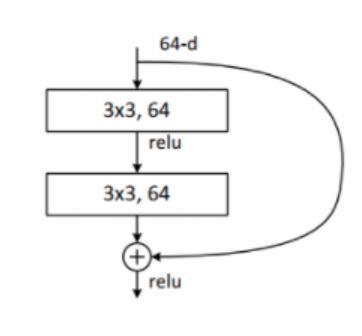
代码如下:
resnet.py
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
# from torchsummary import summary
class ResidualBlock(nn.Module):
"""
实现子module: Residual Block
"""
def __init__(self, inchannel, outchannel, stride=1, shortcut=None):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, 3, stride, 1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, 3, 1, 1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.right = shortcut
def forward(self, x):
out = self.left(x)
residual = x if self.right is None else self.right(x)
out += residual
return F.relu(out)
class ResNet(nn.Module):
"""
实现主module:ResNet34
ResNet34包含多个layer,每个layer又包含多个Residual block
用子module来实现Residual block,用_make_layer函数来实现layer
"""
def __init__(self, blocks, num_classes=1000):
super(ResNet, self).__init__()
self.model_name = 'resnet34'
# 前几层: 图像转换
self.pre = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 1))
# 重复的layer,分别有3,4,6,3个residual block
self.layer1 = self._make_layer(64, 64, blocks[0])
self.layer2 = self._make_layer(64, 128, blocks[1], stride=2)
self.layer3 = self._make_layer(128, 256, blocks[2], stride=2)
self.layer4 = self._make_layer(256, 512, blocks[3], stride=2)
# 分类用的全连接
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, inchannel, outchannel, block_num, stride=1):
"""
构建layer,包含多个residual block
"""
shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, 1, stride, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU()
)
layers = []
layers.append(ResidualBlock(inchannel, outchannel, stride, shortcut))
for i in range(1, block_num):
layers.append(ResidualBlock(outchannel, outchannel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.pre(x)
l1_out = self.layer1(x)
l2_out = self.layer2(l1_out)
l3_out = self.layer3(l2_out)
l4_out = self.layer4(l3_out)
p_out = F.avg_pool2d(l4_out, 7)
fea = p_out.view(p_out.size(0), -1)
out=self.fc(fea)
return l1_out,l2_out,l3_out,l4_out,fea,out
def ResNet18():
return ResNet([2, 2, 2, 2])
def ResNet34():
return ResNet([3, 4, 6, 3])
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = ResNet34()
model.to(device)
# summary(model, (3, 224, 224))
主要修改了输出结果,将每个block的结果输出出来。
RseNet50、 RseNet101、 RseNet152
这个三个模型的block是一致的,结构如下:
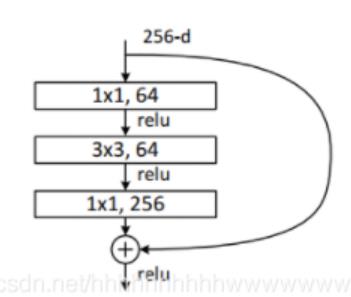
代码:
resnet_l.py
import torch
import torch.nn as nn
import torchvision
import numpy as np
print("PyTorch Version: ", torch.__version__)
print("Torchvision Version: ", torchvision.__version__)
__all__ = ['ResNet50', 'ResNet101', 'ResNet152']
def Conv1(in_planes, places, stride=2):
return nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=places, kernel_size=7, stride=stride, padding=3, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
class Bottleneck(nn.Module):
def __init__(self, in_places, places, stride=1, downsampling=False, expansion=4):
super(Bottleneck, self).__init__()
self.expansion = expansion
self.downsampling = downsampling
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels=in_places, out_channels=places, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=places, out_channels=places, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=places, out_channels=places * self.expansion, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(places * self.expansion),
)
if self.downsampling:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=in_places, out_channels=places * self.expansion, kernel_size=1, stride=stride,
bias=False),
nn.BatchNorm2d(places * self.expansion)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
out = self.bottleneck(x)
if self.downsampling:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, blocks, num_classes=1000, expansion=4):
super(ResNet, self).__init__()
self.expansion = expansion
self.conv1 = Conv1(in_planes=3, places=64)
self.layer1 = self.make_layer(in_places=64, places=64, block=blocks[0], stride=1)
self.layer2 = self.make_layer(in_places=256, places=128, block=blocks[1], stride=2)
self.layer3 = self.make_layer(in_places=512, places=256, block=blocks[2], stride=2)
self.layer4 = self.make_layer(in_places=1024, places=512, block=blocks[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(2048, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def make_layer(self, in_places, places, block, stride):
layers = []
layers.append(Bottleneck(in_places, places, stride, downsampling=True))
for i in range(1, block):
layers.append(Bottleneck(places * self.expansion, places))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
l1_out = self.layer1(x)
l2_out = self.layer2(l1_out)
l3_out = self.layer3(l2_out)
l4_out = self.layer4(l3_out)
p_out = self.avgpool(l4_out)
fea = p_out.view(p_out.size(0), -1)
out = self.fc(fea)
return l1_out, l2_out, l3_out, l4_out, fea, out
def ResNet50():
return ResNet([3, 4, 6, 3])
def ResNet101():
return ResNet([3, 4, 23, 3])
def ResNet152():
return ResNet([3, 8, 36, 3])
if __name__ == '__main__':
# model = torchvision.models.resnet50()
model = ResNet50()
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
同上,将每个block都输出出来。
数据准备
数据使用我以前在图像分类任务中的数据集——植物幼苗数据集,先将数据集转为训练集和验证集。执行代码:
import glob
import os
import shutil
image_list=glob.glob('data1/*/*.png')
print(image_list)
file_dir='data'
if os.path.exists(file_dir):
print('true')
#os.rmdir(file_dir)
shutil.rmtree(file_dir)#删除再建立
os.makedirs(file_dir)
else:
os.makedirs(file_dir)
from sklearn.model_selection import train_test_split
trainval_files, val_files = train_test_split(image_list, test_size=0.3, random_state=42)
train_dir='train'
val_dir='val'
train_root=os.path.join(file_dir,train_dir)
val_root=os.path.join(file_dir,val_dir)
for file in trainval_files:
file_class=file.replace("\\\\","/").split('/')[-2]
file_name=file.replace("\\\\","/").split('/')[-1]
file_class=os.path.join(train_root,file_class)
if not os.path.isdir(file_class):
os.makedirs(file_class)
shutil.copy(file, file_class + '/' + file_name)
for file in val_files:
file_class=file.replace("\\\\","/").split('/')[-2]
file_name=file.replace("\\\\","/").split('/')[-1]
file_class=os.path.join(val_root,file_class)
if not os.path.isdir(file_class):
os.makedirs(file_class)
shutil.copy(file, file_class + '/' + file_name)
训练Teacher模型
Teacher选用ResNet50。
步骤
新建teacher_train.py,插入代码:
导入需要的库
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from torchvision import datasets
from torch.autograd import Variable
from model.resnet_l import ResNet50
import json
import os
定义训练和验证函数
def train(model, device, train_loader, optimizer, epoch):
model.train()
sum_loss = 0
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(target).to(device)
l1_out,l2_out,l3_out,l4_out,fea, out = model(data)
loss = criterion(out, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print_loss = loss.data.item()
sum_loss += print_loss
if (batch_idx + 1) % 10 == 0:
print('Train Epoch: [/ (:.0f%)]\\tLoss: :.6f'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
ave_loss = sum_loss / len(train_loader)
print('epoch:,loss:'.format(epoch以上是关于知识蒸馏IRG算法实战:使用ResNet50蒸馏ResNet18的主要内容,如果未能解决你的问题,请参考以下文章