基于docker快速搭建hive环境
Posted xiao987334176
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于docker快速搭建hive环境相关的知识,希望对你有一定的参考价值。
一、概述
Hive是什么?
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。
最初,Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下Apache Hive为一个开源项目。它用在好多不同的公司。例如,亚马逊使用它在 Amazon Elastic MapReduce。

Hive 不是
- 一个关系数据库
- 一个设计用于联机事务处理(OLTP)
- 实时查询和行级更新的语言
Hiver特点
- 它存储架构在一个数据库中并处理数据到HDFS。
- 它是专为OLAP设计。
- 它提供SQL类型语言查询叫HiveQL或HQL。
- 它是熟知,快速,可扩展和可扩展的。
Hive架构
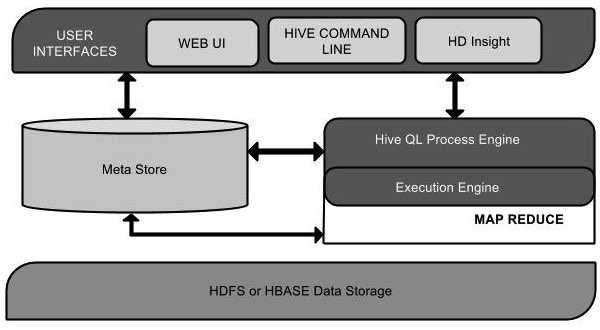
该组件图包含不同的单元。下表描述每个单元:
| 单元名称 | 操作 |
| 用户接口/界面 |
Hive是一个数据仓库基础工具软件,可以创建用户和HDFS之间互动。用户界面,Hive支持是Hive的Web UI,Hive命令行,HiveHD洞察(在Windows服务器)。
|
| 元存储 | Hive选择各自的数据库服务器,用以储存表,数据库,列模式或元数据表,它们的数据类型和HDFS映射。 |
| HiveQL处理引擎 |
HiveQL类似于SQL的查询上Metastore模式信息。这是传统的方式进行MapReduce程序的替代品之一。相反,使用Java编写的MapReduce程序,可以编写为MapReduce工作,并处理它的查询。
|
| 执行引擎 |
HiveQL处理引擎和MapReduce的结合部分是由Hive执行引擎。执行引擎处理查询并产生结果和MapReduce的结果一样。它采用MapReduce方法。
|
| HDFS 或 HBASE | Hadoop的分布式文件系统或者HBASE数据存储技术是用于将数据存储到文件系统。 |
Hive工作原理
下图描述了Hive 和Hadoop之间的工作流程。
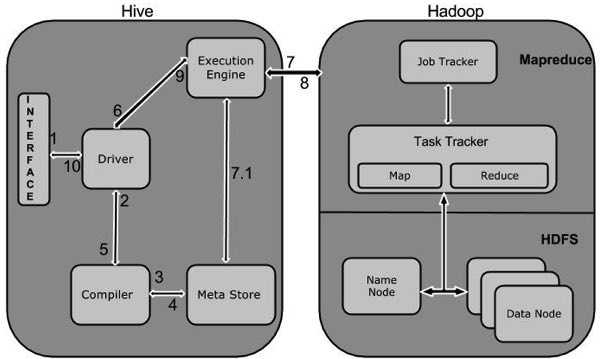
下表定义Hive和Hadoop框架的交互方式:
| Step No. | 操作 |
| 1 |
Execute Query
Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。 |
| 2 |
Get Plan
在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。 |
| 3 |
Get Metadata
编译器发送元数据请求到Metastore(任何数据库)。 |
| 4 |
Send Metadata
Metastore发送元数据,以编译器的响应。 |
| 5 |
Send Plan
编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。 |
| 6 |
Execute Plan
驱动程序发送的执行计划到执行引擎。 |
| 7 |
Execute Job
在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。 |
| 8 |
Metadata Ops
与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。 |
| 9 |
Fetch Result
执行引擎接收来自数据节点的结果。 |
| 10 |
Send Results
执行引擎发送这些结果值给驱动程序。 |
执行过程就是:
HiveQL通过CLI/web UI或者thrift 、 odbc 或 jdbc接口的外部接口提交,经过complier编译器,运用Metastore中的元数据进行类型检测和语法分析,生成一个逻辑方案(logical plan),然后通过简单的优化处理,产生一个以有向无环图DAG数据结构形式展现的map-reduce任务。Hive构建在Hadoop之上,Hive的执行原理:
-
HQL中对查询语句的解释、优化、生成查询计划是由Hive完成的
-
所有的数据都是存储在Hadoop中
-
查询计划被转化为MapReduce任务,在Hadoop中执行(有些查询没有MR任务,如:select * from table)
-
Hadoop和Hive都是用UTF-8编码的
查询编译器(query complier),用云存储中的元数据来生成执行计划,步骤如下:
-
解析(parse)-anlr解析其生成语法树AST(hibernate也是这个):将HQL转化为抽象语法树AST
-
类型检查和语法分析(type checking and semantic analysis):将抽象语法树转换此查询块(query block tree),并将查询块转换成逻辑查询计划(logic plan Generator);
-
优化(optimization):重写查询计划(logical optimizer)–>将逻辑查询计划转成物理计划(physical plan generator)–>选择最佳的join策略(physical optimizer)
二、hive环境安装
hadoop的安装前面已经说过了,注意:Hive版本1.2以上需要Java 1.7或更高版本。 Hive版本0.14到1.1也适用于Java 1.6。 强烈建议用户开始转向Java 1.8。Hadoop 2.x(首选),1.x(不支持Hive 2.0.0以上版本)。
Hive版本0.13也支持Hadoop 0.20.x,0.23.x。Hive常用于生产Linux和Windows环境。 Mac是一个常用的开发环境。
Hadoop集群的搭建前面已经介绍了,链接如下:
https://www.cnblogs.com/xiao987334176/p/13208915.html
由于使用的是jdk1.7,我需要升级到jdk1.8。因此镜像需要重新构建才行!
注意:hive需要运行在hadoop-master节点才可以!
环境说明
| 操作系统 | docker版本 | ip地址 | 配置 |
| centos 7.6 | 19.03.12 | 192.168.31.229 | 4核8g |
我们采用远程模式安装hive,也就是将mysql数据库独立出来,将元数据保存在远端独立的Mysql服务器中。
运行mysql
创建网桥
docker network create hadoop
创建数据目录
mkdir -p /data/mysql/data
运行mysql
docker run -itd --net=hadoop --restart=always --name hadoop-mysql --hostname hadoop-mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=abcd@1234 -v /data/mysql/data:/var/lib/mysql mysql:5.7 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
创建hive数据库
# docker exec -it hadoop-mysql /bin/bash root@hadoop-mysql:/# mysql -u root -pabcd@1234 mysql> CREATE DATABASE `hive` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; Query OK, 1 row affected (0.00 sec)
目录结构
/opt/hadoop-hive 目录结构如下:
./ ├── apache-hive-2.1.1-bin.tar.gz ├── config │ ├── core-site.xml │ ├── hadoop-env.sh │ ├── hdfs-site.xml │ ├── hive-site.xml │ ├── mapred-site.xml │ ├── run-wordcount.sh │ ├── slaves │ ├── ssh_config │ ├── start-hadoop.sh │ └── yarn-site.xml ├── Dockerfile ├── hadoop-2.7.2.tar.gz ├── mysql-connector-java-5.1.38.jar ├── README.md ├── sources.list ├── start-container1.sh └── start-container2.sh
由于软件包比较大,需要使用迅雷下载,下载地址如下:
https://github.com/kiwenlau/compile-hadoop/releases/download/2.7.2/hadoop-2.7.2.tar.gz http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.38/mysql-connector-java-5.1.38.jar http://mirror.bit.edu.cn/apache/hive/hive-2.1.1/apache-hive-2.1.1-bin.tar.gz
构建镜像
docker build -t hadoop-hive:1 .
创建数据目录
mkdir -p /data/hadoop-cluster/master/ /data/hadoop-cluster/slave1/ /data/hadoop-cluster/slave2/
运行镜像
cd /opt/hadoop-hive bash start-container1.sh
启动hadoop集群
bash start-hadoop.sh
注意:这一步会ssh连接到每一个节点,确保ssh信任是正常的。
Hadoop的启动速度取决于机器性能
退出docker容器,拷贝hdfs文件到宿主机目录
docker cp hadoop-master:/root/hdfs /data/hadoop-cluster/master/ docker cp hadoop-slave1:/root/hdfs /data/hadoop-cluster/slave1/ docker cp hadoop-slave2:/root/hdfs /data/hadoop-cluster/slave2/
重新运行容器,并挂载hdfs目录
cd /opt/hadoop-hive bash start-container2.sh
开启hadoop
bash start-hadoop.sh
注意:这一步会ssh连接到每一个节点,确保ssh信任是正常的。
Hadoop的启动速度取决于机器性能
运行wordcount
bash run-wordcount.sh
此脚本会连接到fdfs,并生成几个测试文件。
运行结果:
... input file1.txt: Hello Hadoop input file2.txt: Hello Docker wordcount output: Docker 1 Hadoop 1 Hello 2
wordcount的执行速度取决于机器性能
关闭安全模式
进入hadoop-master容器,执行命令:
hadoop dfsadmin -safemode leave
配置hive-site.xml文件
cat /usr/local/hive/conf/hive-site.xml
内容如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop-mysql:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>abcd@1234</value> <description>password to use against metastore database</description> </property> </configuration>
注意:请根据实际情况修改mysql地址,用户名和密码。由于mysql是ip访问的,需要关闭ssl连接。
hive元数据库初始化
/usr/local/hive/bin/schematool -dbType mysql -initSchema
输出:
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql://hadoop-mysql:3306/hive?createDatabaseIfNotExist=true&useSSL=false Metastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: root Starting metastore schema initialization to 2.1.0 Initialization script hive-schema-2.1.0.mysql.sql Initialization script completed schemaTool completed
注意:它会连接到mysql,并写入相关表数据。
打开navicat客户端,查看表数据
Hive服务端的启动
nohup /usr/local/hive/bin/hive --service metastore &
查看端口
# ss -tunlp|grep 9083 tcp LISTEN 0 50 *:9083 *:* users:(("java",1477,392))
进入hive shell测试
# /usr/local/hive/bin/hive hive> CREATE SCHEMA testdb; OK Time taken: 2.052 seconds hive> SHOW DATABASES; OK default testdb Time taken: 0.48 seconds, Fetched: 2 row(s) hive> quit;
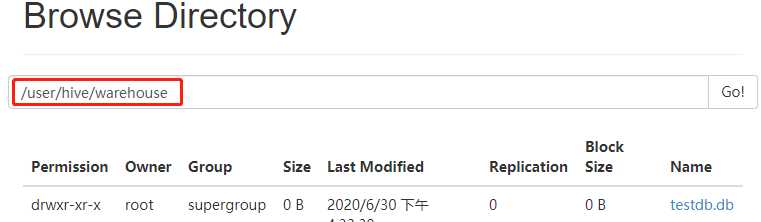
使用hdfs 管理页面,查看刚刚创建的数据库
本文参考链接:
https://www.cnblogs.com/ggzhangxiaochao/p/9363029.html
以上是关于基于docker快速搭建hive环境的主要内容,如果未能解决你的问题,请参考以下文章
基于Docker快速搭建Hadoop集群和Flink运行环境
基于Docker快速搭建Hadoop集群和Flink运行环境