CVPR2020:扩展架构以实现高效的视频识别(X3D)
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVPR2020:扩展架构以实现高效的视频识别(X3D)相关的知识,希望对你有一定的参考价值。
CVPR2020:扩展架构以实现高效的视频识别(X3D)
X3D: Expanding Architectures for Efficient Video Recognition
论文地址:
https://openaccess.thecvf.com/content_CVPR_2020/html/Feichtenhofer_X3D_Expanding_Architectures_for_Efficient_Video_Recognition_CVPR_2020_paper.html
代码位于:https://github.com/facebookresearch/SlowFast
摘要
本文提出了一个高效的视频网络家族X3D,它在空间、时间、宽度和深度上沿着多个网络轴逐步扩展一个微小的2D图像分类体系结构。受机器学习中特征选择方法的启发,采用了一种简单的逐步网络扩展方法,在每一步中扩展一个单轴,达到了很好的复杂度权衡精度。为了将X3D扩展到特定的目标复杂度,我们先进行渐进式向前扩展,然后进行向后收缩。X3D实现了最先进的性能,同时需要4.8x [1]和5.5x [1]更少的乘法和参数,以获得与先前工作类似的精度。我们最令人惊讶的发现是,具有高时空分辨率的网络可以表现良好,同时在网络宽度和参数方面非常轻。我们在视频分类和检测基准上以前所未有的效率报告了具有竞争力的准确性。
1.介绍
视频识别的神经网络很大程度上是通过将二维图像结构(23,37,51,58)扩展到时空来驱动的。当然,这些扩展通常沿时间轴发生,包括将网络输入、特征和/或滤波器内核扩展到时空(例如[6、12、16、32、43、62]);但是,其他设计决策包括深度(层数)、宽度(通道数)和空间大小,通常继承自二维图像架构。虽然沿时间轴扩展(同时保持其他设计特性)通常会提高精度,但如果考虑到计算/精度权衡(这是应用中的中心重要性),则可能是次优的。部分原因是二维模型直接扩展到三维模型,视频识别体系结构的计算量很大。与图像识别相比,典型的视频模型对计算要求更高,例如,图像ResNet[23]比临时扩展的视频变体[68]可以使用大约27倍的乘法和加法操作。
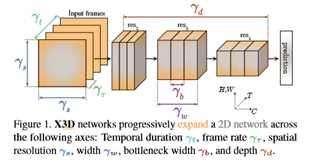
本文从计算/精度权衡的角度研究了视频识别中的低计算机制。我们的设计基于用于图像识别的“移动区域”模型[24,25,48]。我们的核心思想是,虽然沿时间轴扩展一个小模型可以提高精度,但与扩展其他轴相比,计算/精度权衡可能并不总是最佳的,特别是在低计算区域,其中精度可以沿不同轴快速增加。在本文中,我们通过扩展图1所示的多个可能轴,逐步地将微小的基部2D图像架构“扩展”为时空架构。候选轴包括时间持续时间γt、帧速率γτ、空间分辨率γs、网络宽度γw、瓶颈宽度γb和深度γd。生成的架构称为X3D(Expand 3D),用于从2D空间扩展到3D时空域。2D-base架构是由MobileNet[24,25,48]核心的信道可分离卷积概念驱动的,但是它比移动图像模型少10倍的乘法和加法运算,因此变得很小。然后,我们的扩展通过一次仅扩展一个轴来逐步增加计算(例如,增加2倍),训练并验证生成的体系结构,并选择实现最佳计算/精度权衡的轴。重复该过程,直到架构达到所需的计算预算。这可以解释为这些轴定义的超参数空间中坐标下降的一种形式[70]。
我们的渐进式网络扩展方法受到image ConvNet设计历史的启发,在image ConvNet设计中,流行的架构是通过扩展深度[7,23,37,51,58,81]、分辨率[27,57,60]或宽度[75,80]和机器学习中的经典特征选择方法[21,31,34]而产生的。在后一种方法中,渐进式特征选择方法[21,34]从一组最小特征开始,目的是通过在每个步骤中包含(正向选择)单个特征,找到相关特征,以贪婪的方式改进,或者从一整套特征开始,目的是通过重复删除性能降低最少的功能(向后消除)。与之前的研究相比,我们使用了Kinetics-400[33]、Kinetics-600[3]、Charades[49]和AVA[20]。为了进行系统的研究,我们将我们的模型分为不同复杂度的小、中、大模型。总的来说,我们的扩展产生了一系列时空架构,涵盖了广泛的计算/精度权衡。它们可以在实际中依赖于应用程序的不同计算预算下使用。例如,在不同的计算和精度范围内,X3D对当前状态有良好的性能,同时需要减少4.8×和5.5×的乘法和参数,以获得与先前工作类似的精度。此外,扩展是简单和廉价的,例如,我们的低计算模型仅在训练了30个小模型之后完成,这些模型比一个最先进的大型网络累积需要的乘法加法操作少25倍以上[14,68,71]。从概念上讲,我们最令人惊讶的发现是,仅通过扩展时空分辨率和深度创建的非常轻量的视频模型可以很好地执行,同时在网络宽度和参数方面非常轻。X3D网络的宽度明显低于基于imagedesign[23,51,58]的视频架构。我们希望这些进展将有助于今后的研究和应用。
2. X3D网络
图像分类架构经历了架构设计的演变,随着网络深度[7,23,37,51,58,81]、输入分辨率[27,57,60]或信道宽度[75,80]的不断扩展,现有模型也在不断扩展。在移动图像分类领域也可以观察到类似的进展,其中收缩修改(较浅的网络、较低的分辨率、较薄的层、可分离的卷积[24,25,29,48,82])允许在较低的计算预算下操作。鉴于图像转换器网络设计的这段历史,视频架构还没有出现类似的进展,因为它们通常是基于图像模型的直接时间扩展。然而,固定二维架构的单一扩展是理想的,还是沿着不同的轴扩展或收缩更好?对于视频分类来说,时间维度暴露了一个额外的困境,增加了可能性的数量,但也要求它的处理方式不同于空间维度[14,50,64]。我们特别关注不同轴之间的权衡,更具体地说:
三维网络的最佳时间采样策略是什么?长输入持续时间和稀疏采样是否优于短持续时间剪辑的快速采样?
•我们是否需要更高的空间分辨率?以前的作品使用较低的分辨率进行视频分类[32、62、64],以提高效率。而且,视频通常比互联网图像具有更高的空间分辨率;因此,是否存在性能饱和的最大空间分辨率?
•网络的帧速率高,但信道分辨率较低,还是用更宽的模型缓慢处理视频?例如,如果网络有较重的层作为典型的图像分类模型(和慢通道[14])或较轻的层具有较低的宽度(作为快速通道[14])。或者在这两个极端之间有更好的取舍吗?
•当增加网络宽度时,在ResNet块设计[23]中全局扩展网络宽度还是扩展内部(“瓶颈”)宽度更好,这在使用信道可分离卷积的移动图像分类网络中是常见的[48,82]?
•应通过扩大输入分辨率来进行更深层次的操作,以保持接收场足够大且其增长率大致恒定,还是更好地扩展到不同的轴?这是否同时适用于空间和时间维度?
3.实验测试
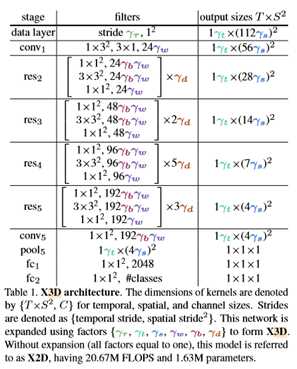
我们首先描述了基本网络架构X2D的实例化,它作为扩展到时空的基线。基本网络实例化遵循ResNet[23]结构和具有退化(单帧)时间输入的慢播网络[14]的快速路径设计。如果所有膨胀系数{γτ、γt、γs、γw、γb、γd}均设为1,则表1中规定了X2D。
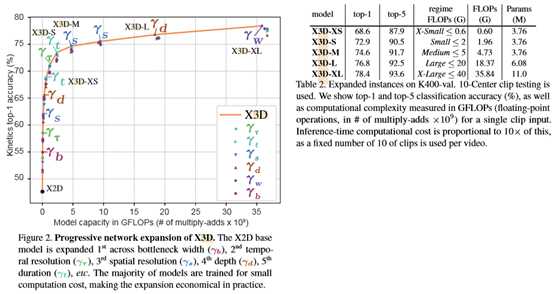
K400扩展过程的精度/复杂度折衷曲线如图2所示。扩展从X2D开始,产生47.75%的top-1精度(垂直轴),1.63M参数,每个剪辑20.67M触发器(水平轴),在每个渐进步骤中大约翻倍。我们使用10个中心剪辑测试作为扩展的默认测试设置,因此每个视频的总成本为×10。我们将在一秒内消除不同数量的测试剪辑。图2中的展开提供了几个有趣的观察结果。
根据VGG模型[7,51]的实质,我们根据目标复杂度定义了一组网络。我们使用触发器,因为这反映了一种硬件不可知的模型复杂性度量。参数也是可能的,但由于它们对输入张量和激活张量大小不敏感,因此我们只将它们报告为次要度量。为了涵盖我们扩展的模型,表2按触发器定义了复杂度范围,从超小型(XS)到超大型(XL)。
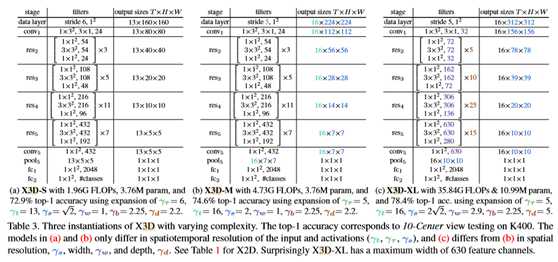
表3显示了三个具有不同复杂性的X3D实例。有趣的是,检查模型的差异,表3a中的X3D-S只是表3b的较低时空分辨率(γt,γτ,γS)版本;因此具有相同数量的参数,表3c中的X3D-XL是通过在空间分辨率(γS)和宽度(γw)中扩展X3D-M 3b而创建的。X2D见表1。
Kinetics-400
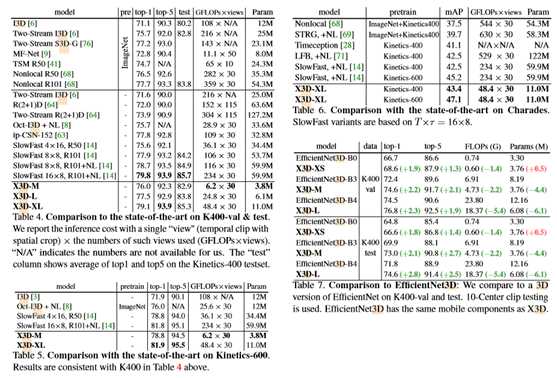
表4显示了与三个X3D的最新结果的比较实例化。到与之前的工作相比,我们使用相同的测试策略,即10LeftCenterRight(即30view)推断。对于每个模型,该表报告(从左到右)ImageNet预训练(pre)、top-1和top-5验证精度、平均测试精度(top-1+top-5)/2(即官方测试服务器度量)、推断成本(GFLOPs×视图)和参数。
Kinetics-600是动力学的一个更大版本,将证明我们的方法的进一步推广。结果见表5。我们的变体显示出与上述类似的性能,最好的模型现在提供的性能比以前的慢速度16×8,R101+NL[14]稍好,同样是4.8×更少的触发器(即乘法加运算)和5.5×更少的参数。在较低的计算范围内,X3D-M可与SlowFast 4×16、R50相媲美,但需要的触发器和参数分别减少5.8×和9.1×。
在表7中,我们比较了三个复杂度与Ef?cientNet3D相似的X3D模型,分别是K400 val和K400 test(自上而下)。从K400 val(顶行)开始,我们的X3D-XS型号只对应于图2中的4个扩展步骤。在触发器(略低)和参数(略高)方面与Ef?cientNet3D-B0相当,但top-1和top-1精度分别提高1.9%和1.3%。
推理成本
在许多情况下,和之前的实验一样,推理过程遵循固定数量的剪辑进行测试。在这里,我们旨在消除使用较少的测试剪辑进行视频级推断的效果。在图3中,我们示出当改变所使用的时间剪辑的数量时,对视频的完全推断的权衡。纵轴显示了K400 val上的top-1精度,横轴显示了不同模型的FLOPs的总体推理成本。
由于我们的扩展是通过验证集性能来衡量的,所以我们很有兴趣看看这是否为X3D带来了好处。因此,我们研究了表7下半部分中K400测试集的潜在差异,在表7下半部分中,在比较上述相同模型时,可以观察到类似的、甚至稍高的精度改进,证明了我们的模型对测试集具有很好的通用性。
在表8的上半部分,我们将X3D-XL与LFB进行了比较,后者使用重型主干架构进行短期和长期建模。与LFB R50/R101相比,X3D-XL提供了相当的精度(+0.3 mAP与LFB R50相比,-0.7 mAP与LFB
R101相比),成本大大降低了10.9×/14×乘法加和6.7×/11.1×参数。

以上是关于CVPR2020:扩展架构以实现高效的视频识别(X3D)的主要内容,如果未能解决你的问题,请参考以下文章
《繁凡的论文精读》CVPR 2019 基于决策的高效人脸识别黑盒对抗攻击(清华朱军)
《繁凡的论文精读》CVPR 2019 基于决策的高效人脸识别黑盒对抗攻击(清华朱军)
繁凡的对抗攻击论文精读CVPR 2019 基于决策的高效人脸识别黑盒对抗攻击(清华朱军)
处理表情识别中的坏数据:一篇CVPR 2020及两篇TIP的解读