ds第七章学习记录
Posted drgnibasaw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ds第七章学习记录相关的知识,希望对你有一定的参考价值。
一.知识要点
- 若在查找的同时对表做修改操作(如插入和删除),则相应的表称之为动态查找表。
- 平均查找长度
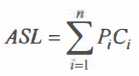
- 设置监视哨的顺序查找
ST.R[O] .key=key; for(i=ST.length;ST.R[i] .key!=key;--i); return i;
//在顺序表ST 中顺序查找其关键字等于 key 的数据元素。若找到,则函数值为该元素在表中的位置,否则为0
- 折半查找
循环执行的条件是low<=high,而不是low<high因为low=high时,查找区间还有最后一个结点, 还要进一步比较 折半查找法在查找成功时进行比较的关键字个数最多不超过树的深度
- 优点 --- 比较次数少 查找效率高
- 缺点 --- 对表结构要求高,只能用于顺序存储的有序表
- 分块查找 (Blocking Search) 索引顺序查找
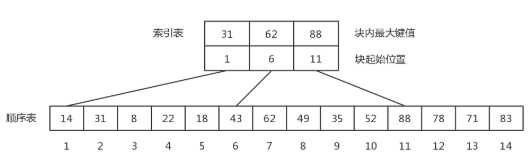 性能介于顺序查找和折半查找之间的一种查找方法
性能介于顺序查找和折半查找之间的一种查找方法- 优点 --- 在表中插入和删除数据元素时,只要找到该元素对应的块,就可以在该块内进行插入和删除运算。
-
缺点 --- 要增加一个索引表的存储空间并对初始索引表进行排序运算
(neuDS)当采用分块查找时,数据的组织方式为( )。(2分)
- 二叉树查找
指针类型的数据
- 平衡二叉树
-
左子树和右子树的深度之差的绝对值不超过1
- 左子树和右子树也是平衡二叉树
-
-
B-树是一种平衡的多叉查找树,是一种在外存文件系统中常用的动态索引技术
-
B+树是一种B-树的变型树,更适合做文件系统的索引
- 平衡二叉树
- 散列表的查找
-
如何构造散列函数 --- 取模
- 以及如何处理冲突 --- 开放地址法
-
- 召回率 查全率
检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率 - 装填因子
结点数和表长的比值
- 召回率 查全率
-
- hash表
typedef struct node
{
int data;
struct node* next;
}NODE;
平均查找长度与结点个数无关
二.作业与实践
二分查找变形
- high=n-1 哈哈忘记了-1的我太傻了
- 不用再跟之前对比 是不是下标最小的了
int search(int d[],int key,int n) { int low=0,high=n-1; int count=0,flag=-1; while(low<=high) { int mid=(low+high)/2; if(key==d[mid]) return mid; if(key<=d[mid]) { high=mid-1; } else low=mid+1; count++; } return flag; }
hashing
- 1不是素数 最小素数为2
-
初始化数组——>构造散列函数——>循环取模 一直到size
-
char类型和int类型 char只有8位
int Hash ( int key, int P )
{
int ptr = key % P;
for(int i=0;i<= P-1; i++)
{
int address = (ptr + i*i) % P;
if(!hashTable[address])
{
hashTable[address] = 1;
return address;
}
}
return -1;
}
以上是关于ds第七章学习记录的主要内容,如果未能解决你的问题,请参考以下文章