Solr搜索引擎的搭建与应用
Posted vcing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr搜索引擎的搭建与应用相关的知识,希望对你有一定的参考价值。
一、什么是Solr?
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
个人理解, Solr是一个索引库,将数据库数据做成索引保存文件,从而大大提高搜索效率。
二、Solr的应用场景
Solr主要解决大数据量全文搜索问题,广泛应用于各大电商平台,例如:淘宝、京东等等。
个人在工作中使用过的两个典型场景:
1、约1.8亿的数据(占硬盘380多G),单条件模糊查询用时不到两秒
2、网站数据1000万左右,日搜索请求量小200万,搜索响应速度两秒内
三、Solr安装配置
1. Solr运行环境要求
需要安装jdk,要求jdk的版本为1.7.0以上版本。
Tomcat要求7以上版本
操作系统:linux、windows都可以
2. 安装文件下载
链接: https://pan.baidu.com/s/1LednAPNO0Jc5Zav8-WjklQ 提取码: 7mh4
3. 安装JDK
JDK安装教程: https://www.cnblogs.com/vcing/p/13173512.html
4. 安装Tomcat
Tomcat安装及配置教程:https://www.cnblogs.com/vcing/p/13173531.html
5.搭建Solr
a) 复制solr-4.7.2目录example/solr到D:Java目录下
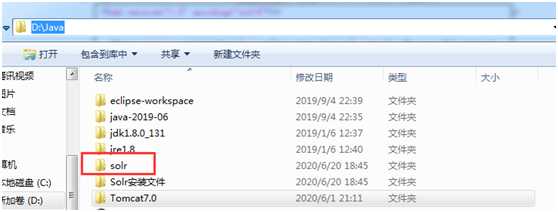
b) 复制solr-4.7.2目录dist/solr-4.7.2.war
到Tomcat的webapps/solr.war(solr-4.7.2.war重命名为solr.war)
c) 复制solr-4.7.2目录example/lib/ext下的所有jar到Tomcat的lib下,同时将example/resources下的log4j.properties文件也复制到Tomcat的lib下
d)在Tomcat/conf/Catalina/localhost下创建solr.xml文件,内容如下:
|
<?xml version="1.0" encoding="utf-8"?> <Context docBase="webapps/solr.war" debug="0" crossContext="true"> <Environment name="solr/home" type="java.lang.String" value="D:/Java/solr" override="true"/> </Context> |
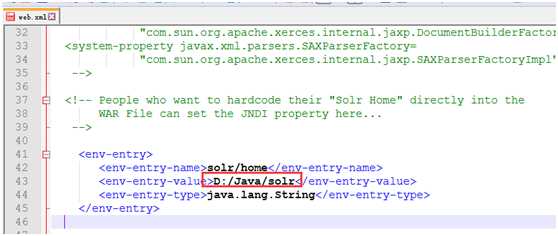
e) 将Solr路径Tomcat7.0webappssolrWEB-INFweb.xml,
|
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>D:/Java/solr</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry> |
f) 重新启动Tomcat服务器,在浏览器输入http://localhost:8080/solr 查看服务,出现如下界面就安装成功了.
四、Solr控制面板介绍
1. Documents
索引库的维护功能。可对索引进行增删改
添加文档
直接 Submit Document 就可以添加文档
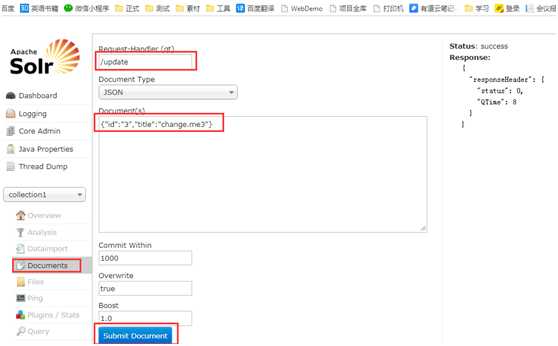
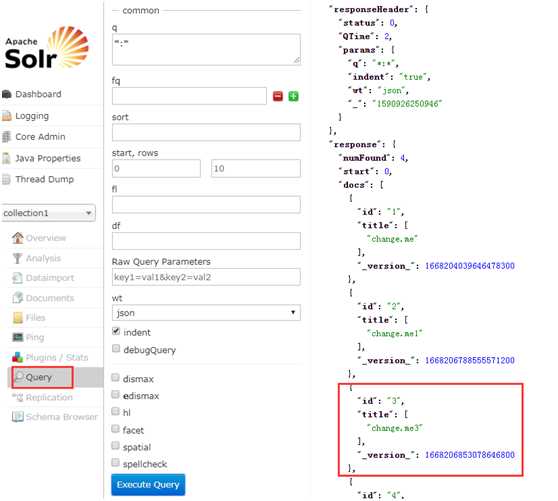
1) 在solr中,一条记录就是一个文档。
2) 文档可以使用json数据格式描述:key就是域名(字段名),value就是值。在solr所有文档中,必须有一个id域。类似关系型数据库表中的主键。必须有,且不能重复。
3) 域必须先定义后使用。必须在schema.xml中定义
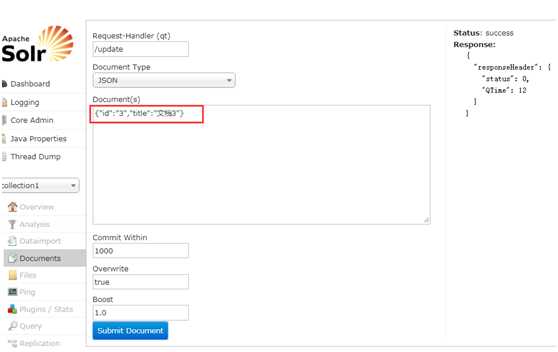
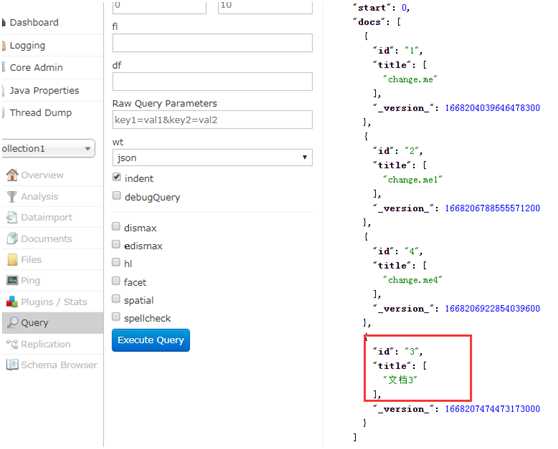
更新文档
更新文档的原理:先删除后添加。保持ID相同,做添加操作,即更新文档。
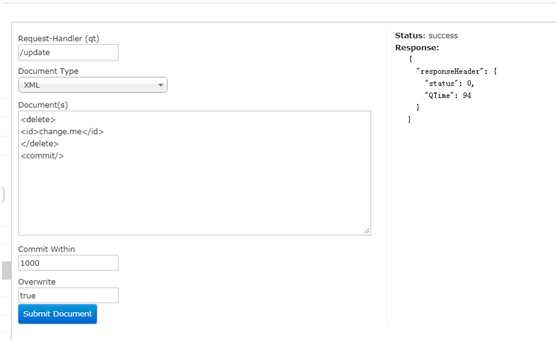
删除文档
- 根据字段删除,删除指定ID文档:<delete><id>change.me</id></delete><commit/>
- 根据查询条件删除:
基础查询语法:
*:*:匹配所有文档;
域名:关键字
删除指定ID文档:<delete><query>id:1</query></delete><commit/>
删除所有文档:<delete><query>*:*</query></delete><commit/>
2.url请求删除
ID删除:http://localhost:8080/solr/collection1/update/?stream.body=<delete><id>12345<id></delete>&commit=true
搜索条件删除:http://localhost:8080/solr/collection1/update/?stream.body=<delete><query>*:*</query></delete>&commit=true
http://localhost:8080/solr/collection1/update/?stream.body=<delete><query>orgingid:12345</query></delete>&commit=true
多搜索条件删除:http://localhost:8080/solr/collection1/update/?stream.body=<delete><query>orderColumn:拟在建项目+AND+firstArea:海外</query></delete>&commit=tru
2. Query
查询索引库
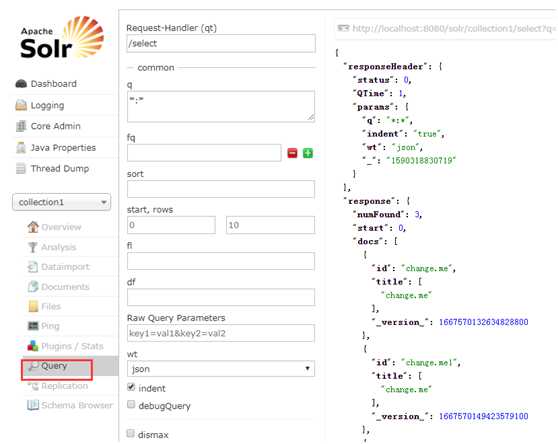
q:查询条件
fq:过滤条件,查询语句和查询语法完全相同。可设置多个过滤条件
sort:排序条件
start,rows:分页条件。start:起始记录,rows每页显示的记录数。
fl:返回结果中域的列表。默认显示所有域
df:默认搜索域
hl:高亮显示
hl.fl:高亮显示的域
hl.simple.pre:高亮前缀
hl.simple.post:高亮后缀
3. Analysis
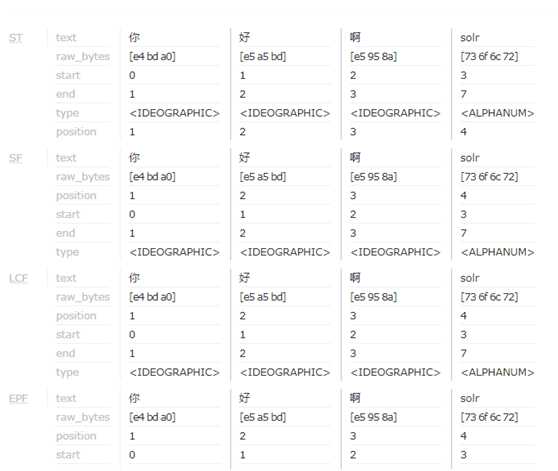
在Field Value输入你好啊solr ,Analyse FieldName/FieldType中选择text_en,然后点击左侧Analyze Value按钮,就能看到分词结果。Solr自带的数据类型,对中文分词效果不太好
效果图如下:

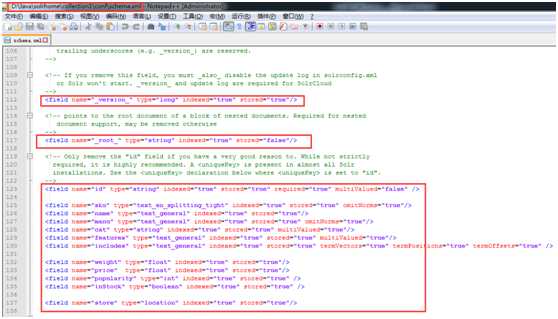
域(字段)列表:所有的域都是定义在schema.xml配置文件中。在solr中,域必须是先定义后使用。如果想修改域的定义及自定义域需要修改schema.xml。
五、Solr分词器安装
安装IK分词器
A. 分词器介绍
一个分词器就是一个数据类型,分词器的安装是非必要的。Solr自带的数据类型,对中文分词效果不太好,根据自己使用需求,可以安装其他分词器。以IK分词器为例,介绍下分词安装步骤
B. 资源下载
官网下载地址:http://code.google.com/p/ik-analyzer/downloads/detail?name=IK%20Analyzer%202012FF_hf1.zip&can=2&q=
当然 Solr安装文件 中已有,可以直接使用
C. 安装配置
1、复制ik分词解压包中的三个文件::IKAnalyzer.cfg.xml、IKAnalyzer2012FF_u1.jar、stopword.dic 到Tomcat7webappssolrWEB-INFlib文件夹下面
2、修改D:Javasolrcollection1conf文件夹下的schema.xml.在<types></types>中增加如下内容:
<!--配置IK分词器—name是名称 下面可以选择分词器--> <fieldType name="text_ik" class="solr.TextField"> <!--索引时候的分词器--> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <!--查询时候的分词器--> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> |
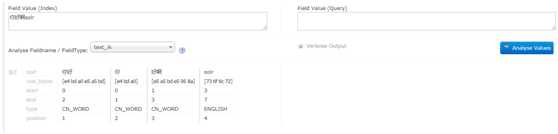
3、重启Tomcat,在浏览器中输入http://localhost:8080/solr ,在页面左侧菜单中选择Core为collection1,点击Analysis(漏斗形状)菜单,在右侧页面Filed Value文本框中输入要测试分词的中文串.
4、在Field Value下方,Analyse FieldName/FieldType中选择text_ik,然后点击左侧Analyze Value按钮,就能看到分词结果。
效果图如下:
六、solr的配置文件及其含义
详见:https://www.cnblogs.com/vcing/p/13196342.html
七、solr连接数据库
安装配置
1、将sqljdbc4.jar复制到D:JavaTomcat7.0webappssolrWEB-INFlib
2、在D:Javasolrcollection1conf下新建data-config.xml文件(名字任意,路径也可以任意)
3、在D:Javasolrcollection1confsolrconfig.xml,文件里配置data-confing.xml路径
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">D:/Java/solr/collection1/conf/db/data-config.xml</str> </lst> </requestHandler> |
4、将solr4.72文件夹下的dist, contrib文件夹复制到D:JavaTomcat7.0
5、在D:Javasolrcollection1confsolrconfig.xml,文件里配置dist, contrib这两个文件夹的路径(solrconfig.xml已存在这些路径,如果以你放置的路径不一样,修改一下就可以了)
<lib dir="D:/Java/Tomcat7.0/contrib/extraction/lib" regex=".*.jar" /> <lib dir="D:/Java/Tomcat7.0/dist/" regex="solr-cell-d.*.jar" /> <lib dir="D:/Java/Tomcat7.0/contrib/clustering/lib/" regex=".*.jar" /> <lib dir="D:/Java/Tomcat7.0/dist/" regex="solr-clustering-d.*.jar" /> <lib dir="D:/Java/Tomcat7.0/contrib/langid/lib/" regex=".*.jar" /> <lib dir="D:/Java/Tomcat7.0/dist/" regex="solr-langid-d.*.jar" /> <lib dir="D:/Java/Tomcat7.0/contrib/velocity/lib" regex=".*.jar" /> <lib dir="D:/Java/Tomcat7.0/dist/" regex="solr-velocity-d.*.jar" /> <lib dir="D:/Java/Tomcat7.0/dist/" regex="solr-dataimporthandler-d.*.jar" /> |
6、将dist文件夹下的这两个文件复制到与数据库驱动同一个文件夹下,以上配置的路径我是用绝对路径配置的,也可以用相对路径,
7、配置连接数据库。首先是配置data-confing.xml文件,data-confing.xml文件就是连接数据库的配置文件(刚才新建的),将如下代码粘贴到该文件中
<?xml version="1.0" encoding="UTF-8"?> <dataConfig> <dataSource driver="com.microsoft.sqlserver.jdbc.SQLServerDriver" url="jdbc:sqlserver://127.0.0.1;DatabaseName=test" user="sa" password="123456"/> <document name="Info"> <entity name="zpxx" transformer="ClobTransformer" pk="id" query="select id,name from test" deltaImportQuery="select id,name from test" deltaQuery="SELECT id FROM test where adddate >=‘${dataimporter.last_index_time}‘">
<field column="id" name="id" /> <field column="name" name="name" /> </entity> </document> </dataConfig> |
配置文件讲解分析
a).这个显而易见,就是连接数据库的字符串了
|
<dataSource driver="com.microsoft.sqlserver.jdbc.SQLServerDriver" url="jdbc:sqlserver://127.0.0.1;DatabaseName=test" user="sa" password="123456"/> |
b).这个就是从哪张表里取数据了的sql语句了
query是获取全部数据的SQL(solr从sql中获取那些数据)
deltaImportQuery是获取增量数据时使用的SQL(数据库新增数据是,追加到solr的数据)
deltaQuery是获取pk的SQL(数据库新增数据是,追加到solr的数据时的条件,根据id ,条件是最后一次获取的时间,${dataimporter.last_index_time,最后获取的时间})
<document name="Info"> <entity name="zpxx" transformer="ClobTransformer" pk="id" query="select id,name from test" deltaImportQuery="select id,name from test" deltaQuery="SELECT id FROM test where adddate >=‘${dataimporter.last_index_time}‘">
<field column="id" name="id" /> <field column="name" name="name" /> </entity> </document> |
c).这个就是数据库与solr的映射关系了,在上一节schema.xml中定义的field子节点对应,那么根据本届内容field就要这么定义
<field column="id" name="id" /> <field column="name" name="name" /> |
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="solrname" type=" string " indexed="true" stored="true" omitNorms="true"/> |
其他的field就可以删掉了(初学者不要删,容易出问题),也可以多定义一些备用,这样table表中id下的数据就存储在了solr中id的位置,name就存储在solrname下了
这个不要删,这是solr自已自己内部的字段,删掉会报错,这样solr就配置完成
<field name="_version_" type="long" indexed="true" stored="true"/> <!-- points to the root document of a block of nested documents. Required for nested document support, may be removed otherwise --> <field name="_root_" type="string" indexed="true" stored="false"/>
|
d). 多表、多库
<entity> ….. </entity> 每一个 entiy就是一张表,有几张表就写几个,这里就要注意一个问题了,单核的solr是把所有的数据存储在在一个文件中,上文中结束的时候说道, schema.xml这个文件可以设置主键(一定要有主键),默认是id, data-confing.xml,文件定义每张表时也指定了主键,没写默认id,多张表示就要注意id的唯一行了,平时我们总是喜欢使用自增id,所以多张表的id肯定会重复,主键的重复solr是不会报错了,但是遵循相同主键后一条覆盖前一条,所以多张表时,就要考虑主键唯一的问题了,如果使用guid的形式那就没问题了,(solr从数据库获取数据是按<entity> ….. </entity>的顺序逐个表去取数据了),那如果非要主键重复存储怎么办,也可以,使用多核模式
多表实例:
<?xml version="1.0" encoding="UTF-8"?> <dataConfig> <dataSource driver="com.microsoft.sqlserver.jdbc.SQLServerDriver" url="jdbc:sqlserver://127.0.0.1;DatabaseName="test" user="sa" password="123456"/> <document name="Info"> <entity name="zpxx" transformer="ClobTransformer" query="select id, name from test" deltaImportQuery="select id, name from test" deltaQuery="SELECT id FROM table where adddate >= ‘${dataimporter.last_index_time}‘">
<field column="id" name=“id" /> <field column="name" name=“name" /> </entity> <entity name="zpxx2" transformer="ClobTransformer" query="select id, name from test2" deltaImportQuery="select id, name from test2" deltaQuery="SELECT id FROM table2 where adddate >=‘${dataimporter.last_index_time}‘">
<field column="id" name=“id" /> <field column="name" name=“name" /> </entity> </document> </dataConfig>
|
现在再说一说多数据库的问题了,一个配置文件可以配置多个数据源。增加一个dataSource元素就可以增加一个数据源了。name属性可以区分不同的数据源。如果配置了多于一个的数据源,那么要注意将name配置成唯一的。
多数据库实例:
<dataSource type="JdbcDataSource" name="ds-1" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://db1-host/dbname" user="db_username" password="db_password"/> <dataSource type="JdbcDataSource" name="ds-2" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://db2-host/dbname" user="db_username" password="db_password"/> 然后这样使用 .. <entity name="one" dataSource="ds-1" ...> .. </entity> <entity name="two" dataSource="ds-2" ...> .. </entity> ..
|
如果存在多表链接怎么办,这个也可以解决, <entity> 中可以嵌套<entity>达到链接效果
例:
<entity name="item" query="select id name from item"> <entity name="feature" query="select description from feature where item_id=‘${item.ID}‘"/>
<entity name="item_category" query="select phone from item_category where category _id=‘${item.ID}‘">
</entity> </entity> |
这个相当于 select a.id ,a.name ,b. description ,c. phone from item as a left join feature as b on a.id=b. item_id left join item_category as c on a.id=c. category _id
这个链接也是有限制的:
子Entity的query必须引用父Entity的pk
子Entity的parentDeltaQuery必须引用自己的pk
子Entity的parentDeltaQuery必须返回父Entity的pk
deltaImportQuery引用的必须是自己的pk
说了这么多我们来简单的配置一个,现在有一张表tableA,有如下字段id ,name,address,phone,class,addtime 我想把这张表的数据存储到solr中, 怎配置,首先在schema.xml 的 fields 节点配置索引字段,(name可以随便起,type是类型,上文字提到过solr的类型,这里为了省事就都用string了)
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="solrname" type=" string " indexed="true" stored="true" omitNorms="true"/> <field name=" address " type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="phone" type=" string " indexed="true" stored="true" omitNorms="true"/> <field name="class" type=" string " indexed="true" stored="true" omitNorms="true"/> <field name="addtime" type=" date" indexed="true" stored="true" omitNorms="true"/> |
上文中还提到过 copyfeild与DynamicField,这个可用可不用,怎样用上文已经解释了,solr中会自带一些定义,想删就删,不删也没事,然后我们配置data-confing.xml,如下,
<dataSource driver="com.microsoft.sqlserver.jdbc.SQLServerDriver" url="jdbc:sqlserver://127.0.0.1;DatabaseName=test" user="sa" password="123456"/> <document name="Info"> <entity name=" test " transformer="ClobTransformer" pk="id" query="select id, name ,address,phone,class,addtime from tableA" deltaImportQuery=" select id, name ,address,phone,class,addtime from tableA" deltaQuery="SELECT id FROM tableA where addtime > ‘${dataimporter.last_index_time}‘">
<field column="id" name="id" /> <field column="name" name="solrname" /> <field column="address " name=“address " /> <field column="phone " name="phone " /> <field column="class " name="class " /> <field column="addtime " name="addtime " /> </entity> </document> </dataConfig>
|
好了,这样就配置完成了,下面该开始执行了,执行有两种方式
先说第一种,浏览器执行方式:
终止跑索引
http://localhost:8080//solr/collection1/dataimport?command=abort
开始索引
http://localhost:8080//solr/collection1/dataimport?command=full-import
增量索引
http://localhost:8080//solr/collection1/dataimport?command=delta-import
直接在浏览器中输入 http://localhost:8080//solr/collection1/dataimport?command=full-import就可以了
我们看看效果
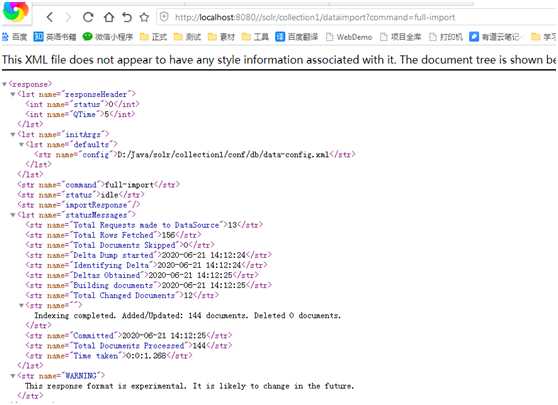
这种方式我们看不到执行过程,执行时间
Solr还提供了图形化的执行方式,如下:
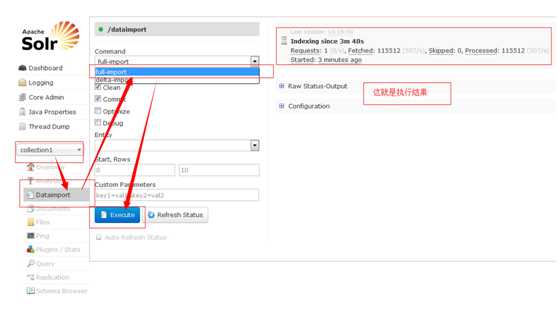
Full Import工作原理:
执行本Entity的Query,获取所有数据;
针对每个行数据Row,获取pk,组装子Entity的Query;
执行子Entity的Query,获取子Entity的数据。
Delta Import工作原理:
查找子Entity,直到没有为止;
执行Entity的deltaQuery,获取变化数据的pk;
合并子Entity parentDeltaQuery得到的pk;
针对每一个pk Row,组装父Entity的parentDeltaQuery;
执行parentDeltaQuery,获取父Entity的pk;
执行deltaImportQuery,获取自身的数据;
如果没有deltaImportQuery,就组装Query
强调一下,修改了Solr或TomCat配置文件 ,需重启tomcat
八、solr定时增量索引与安全
solr增量索引的方式,就是一个Http请求,但是这样的请求显然不能满足要求,我们需要的是一个自动的增量索引,solr官方提供了一个定时器实例,来完成增量索引。
1、下载 apache-solr-dataimportscheduler-1.0.jar,
下载地址:http://solr-dataimport-scheduler.googlecode.com/files/apache-solr-dataimportscheduler-1.0.jar
当然,Solr安装文件 中有,可以直接使用
2、安装配置
1) 将apache-solr-dataimportscheduler-1.0.jar
复制到D:JavaTomcat7.0webappssolrWEB-INFlib
2) 修改D:JavaTomcat7.0webappssolrWEB-INF下的web.xml文件, 在servlet节点前面增加
<listener> <listener-class> org.apache.solr.handler.dataimport.scheduler.ApplicationListener </listener-class> </listener> |
3) 将apache-solr-dataimportscheduler-.jar 中 dataimport.properties 取出,放入D:Javasolrconf,没有conf新建一个
4) 重启tomcat即可
5) dataimport.properties 配置项说明
|
################################################# # # # dataimport scheduler properties # # # #################################################
# to sync or not to sync # 1 - active; anything else - inactive syncEnabled=1
# which cores to schedule # in a multi-core environment you can decide which cores you want syncronized # leave empty or comment it out if using single-core deployment syncCores=game,resource
# solr server name or IP address # [defaults to localhost if empty] server=localhost
# solr server port # [defaults to 80 if empty] port=8080
# application name/context # [defaults to current ServletContextListener‘s context (app) name] webapp=solr
# URL params [mandatory] # remainder of URL params=/select?qt=/dataimport&command=delta-import&clean=false&commit=true
# schedule interval # number of minutes between two runs # [defaults to 30 if empty] interval=1
# 重做索引的时间间隔,单位分钟,默认7200,即1天; # 为空,为0,或者注释掉:表示永不重做索引 reBuildIndexInterval=2
# 重做索引的参数 reBuildIndexParams=/select?qt=/dataimport&command=full-import&clean=true&commit=true
# 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000; # 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期 reBuildIndexBeginTime=03:10:00
|
以上是原文,#后面的是注释,我们来翻译一下
|
################################################# # # # dataimport scheduler properties # # # #################################################
syncEnabled=1 #要定时的增量索引的核心,多核逗号隔开 collection1, collection2 syncCores= collection1
# 这个就不用说了,服务器地址 server=192.168.0.9 port=8080 webapp=solr # 增量索引执行的命令 params=/dataimport?command=delta-import&clean=false&commit=true #多长时间执行一次,默认单位分钟 interval=30 #下面的,是有人更改了该文件,新加的定时重建索引,原包是不带定时重建索引的,只有增量索引,官方的包是不支持下面三句话的,不需要可以删掉 reBuildIndexInterval=7200 reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true reBuildIndexBeginTime=03:10:00
|
3、solr安全性的问题
了解solr后,大家都知道了,solr是通过Http请求去执行所有操作的,那问题就来了,如果别人知道了你的solr服务器的地址就很危险了,solr的新增和删除也都是通过http请求来完成的,地址暴漏后,
你的数据就容易受到攻击了.我这里的解决办法是,设置tomcat的访问权限,只有固定ip可以访问,这样别人就访问不了你的solr了
修改C:Program FilesApache Software FoundationTomcat 7.0confserver.xml,加入ip限制即可
全局设置,对Tomcat下所有应用生效
server.xml中添加下面一行,重启服务器即可:
<Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="192.168.1.*" deny=""/>
此行放在</Host>之前。
例:
1).只允许192.168.1.10访问:
<Valve className="org.apache.catalina.valves.RemoteAddrValve"allow="192.168.1.10" deny=""/>
2).只允许192.168.1.*网段访问:
<Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="192.168.1.*" deny=""/>
3).只允许192.168.1.10、192.168.1.30访 问:
<Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="192.168.1.10,192.168.1.30" deny=""/>
4).根据主机名进行限制:
<Valve className="org.apache.catalina.valves.RemoteHostValve" allow="abc.com" deny=""/>
九、solr在程序中应用
1、Java-SolrJ管理索引库
solr提供的一个客户端,就是一个jar包,把jar包添加到工程中整合solr服务。
1) 第一步:创建java工程
2) 第二步:导入jar包
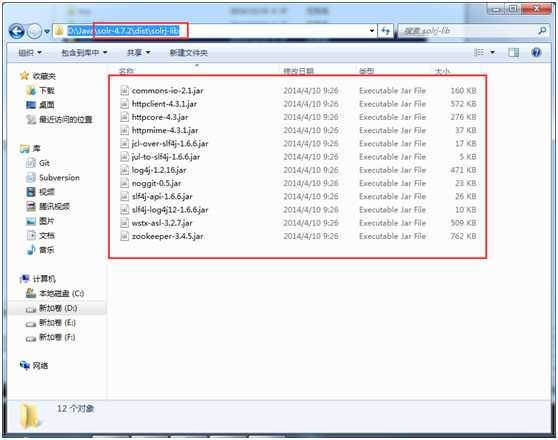
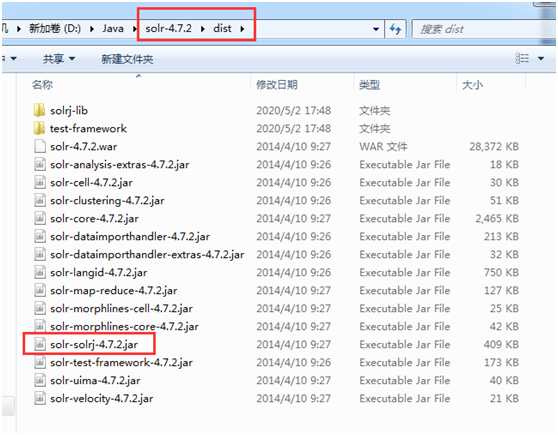
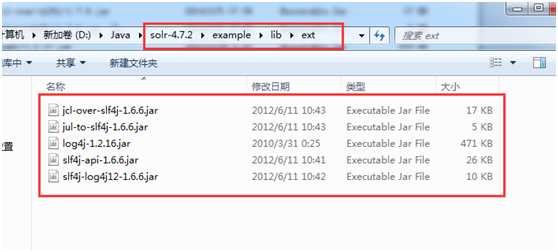
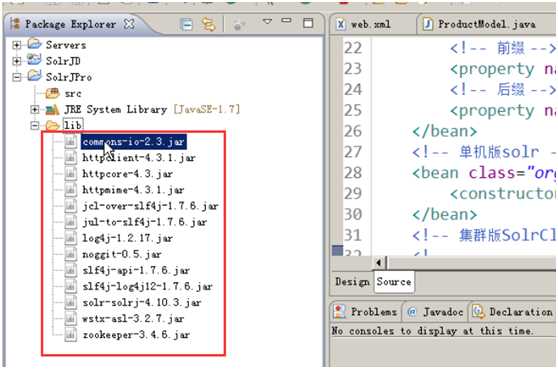
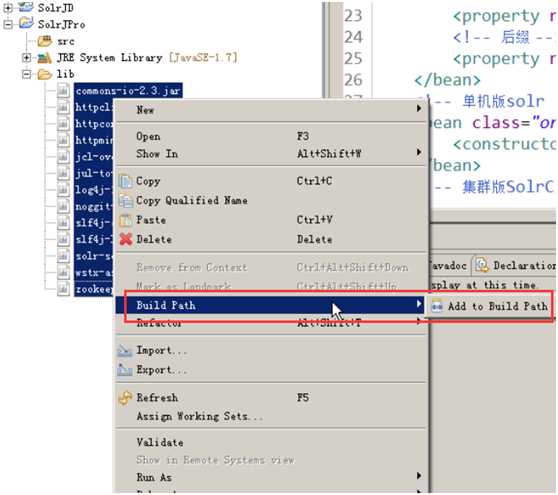
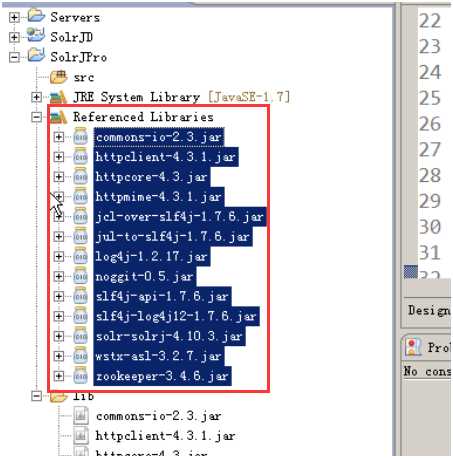
3)第三步:创建java类进行测试
添加文档
代码演示:(不发源码,自己手敲熟悉一遍)
- 创建一个连接solr服务的客户端对象SolrServer对象。
- 创建一个文档对象
- 向文档对象中添加域
- 提交文档到索引库
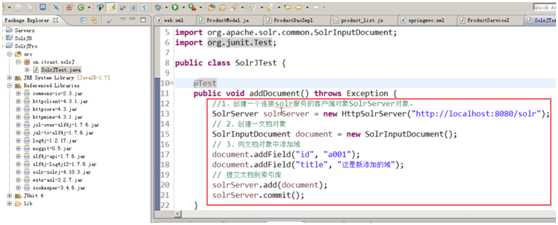
更新文档
更新文档同添加文档,ID保持一致即可,这里就做代码演示了
删除文档
代码演示:(不发源码,自己手敲熟悉一遍)
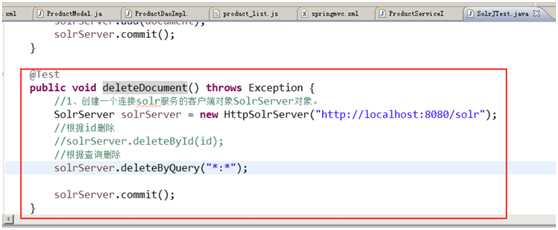
查询

2、C#-Solr管理索引库
两种方式:
手写请求,通过solr 命令进行增删改查
代码演示
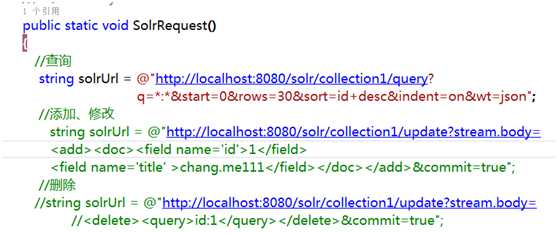


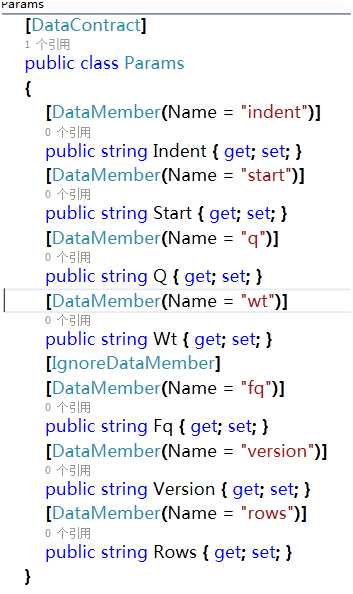
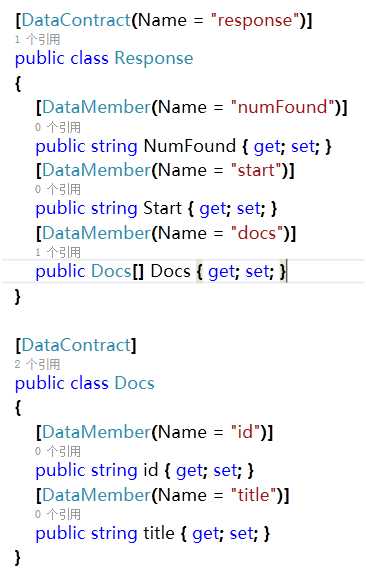
使用SolrNet.dll 实现增删改查
参考资料:https://www.cnblogs.com/vcing/p/13196312.html
十、相关扩展
本篇笔记整理主要参考前辈 "一枚信蜂"的博客笔记,修复了他笔记中一些配置问题,想了解更多请参照:https://www.cnblogs.com/wenxinghaha/
以上是关于Solr搜索引擎的搭建与应用的主要内容,如果未能解决你的问题,请参考以下文章