详解支持向量机
Posted panchuangai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解支持向量机相关的知识,希望对你有一定的参考价值。
作者|Anuj Shrivastav 编译|VK 来源|Medium

介绍
监督学习描述了一类问题,涉及使用模型来学习输入示例和目标变量之间的映射。如果存在分类问题,则目标变量可以是类标签,如果存在回归问题,则目标变量是连续值。一些模型可用于回归和分类。我们将在此博客中讨论的一种这样的模型是支持向量机,简称为SVM。我的目的是为你提供简单明了的SVM内部工作。
假设我们正在处理二分类任务。
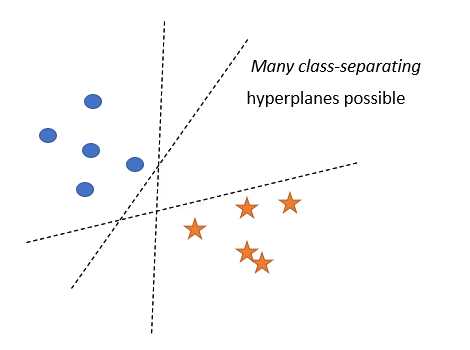
可能有无限多的超平面可以将这两个类分开。你可以选择其中任何一个。但是这个超平面能很好地预测新查询点的类吗?你不认为离一个类很近的那个平面有利于另一个类吗?直观地说,分离两个类的最佳方法是选择一个超平面,该超平面与两个类中最近的点等距。
这就是SVM的作用!
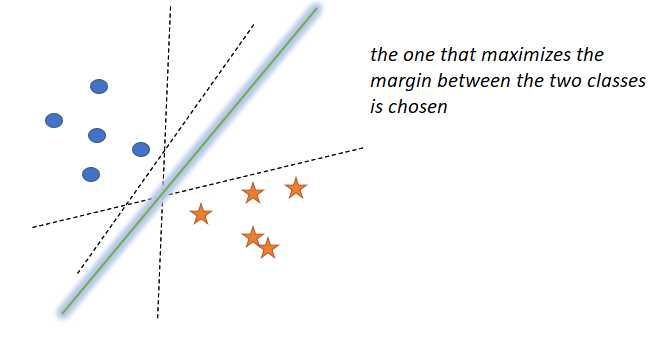
支持向量机的核心思想是:
选择尽可能广泛地将+ve点与-ve点分开的超平面π。(ve代表vector,向量,也就是样本的向量)
设π是分离这两类的超平面,π+和π_是两个平行于π的超平面
π?是当我们平行于π移动并与π最近的+ve点接触时得到的平面
π?是当我们平行于π移动并接触到π的最近-ve点时得到的平面
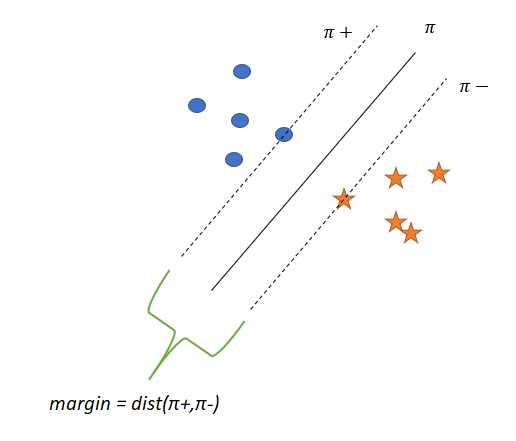
d=margin = dist(π?,π?)
SVM试图找到一个π来最大化间隔。
随着间隔的增加,泛化精度也随之提高。
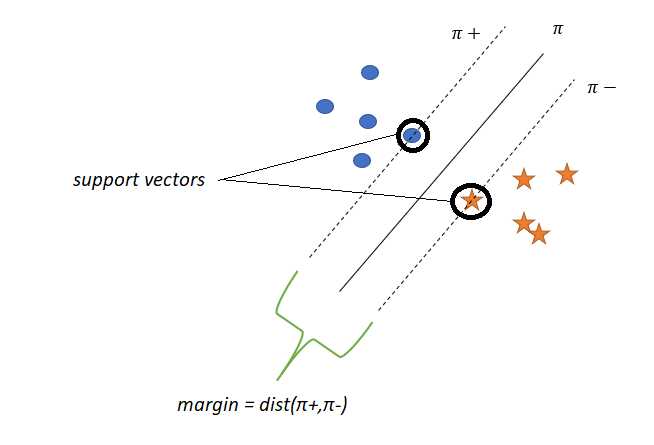
支持向量
位于π?或π?上的点称为支持向量。
SVM数学公式
π: 边距最大化的超平面
π: w?x+b=0
设
π?:w?x+b=+1
π?上的任何点或在正方向远离π?的任何点都标记为正
π?:w?x+b=-1
π?上的任何点或在负方向远离π?的任何点都标记为负
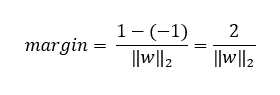
优化问题为
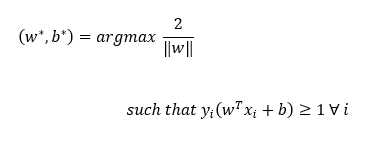
现在,这看起来不错,但是,它只在我们的数据是线性可分时起作用。否则,我们将无法解决上述优化问题,也无法得到最优的w和b。
假设一个数据不是线性可分的场景:
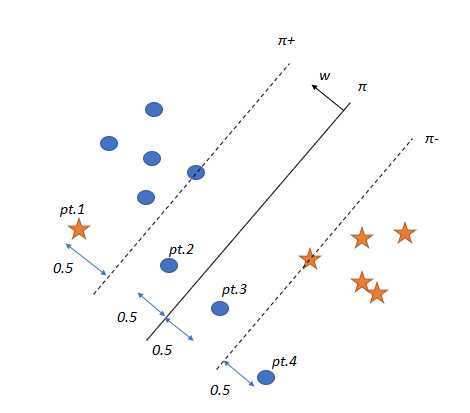
因为这四个点,我们的优化问题永远不会得到解决,因为这些点y?(w?x+b)不大于1。
这是因为我们的优化问题过于严格,它只解决线性可分数据。硬边距就是这种方法的名称。
那么,我们可以修改它吗?我们能不能稍微宽大一点,这样它就可以处理几乎线性可分的数据?

我们要做的是,我们做一个松弛变量ζ?(zeta),对应于每个数据点,这样对于位于+ve区域的+ve点和位于-ve区域的-ve点,
ζ?=0。
这就给我们留下了错误的分类点和间隔内的点。
ζ?的含义,以图为例,当ζ?=2.5
这意味着pt.4在相反的方向上与它的正确超平面(在本例中为π?)相距2.5个单位。
类似地,pt.1与最优超平面(本例中为π?)的方向相反,距离为2.5个单位。
当ζ?增大时,该点在错误方向上离最优超平面更远。

改进优化问题
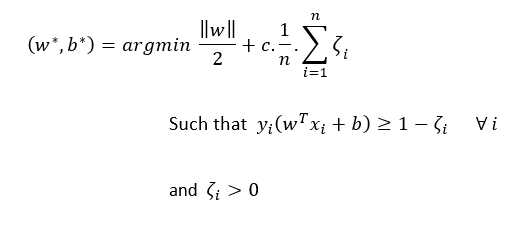
让我们把它分解
首先,约束条件:
我们知道,

现在:
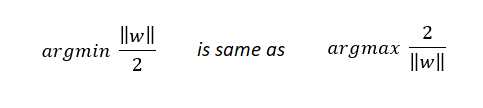
和

c是超参数。
我们可以直观地认为优化问题为:
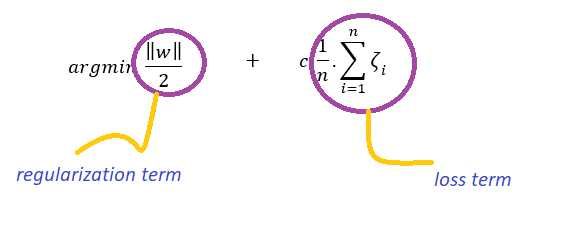
如果c值较高,则损失项的权重更大,从而导致数据的过拟合。
如果c值较低,则正则化项的权重较大,导致数据欠拟合。
SVM对偶形式
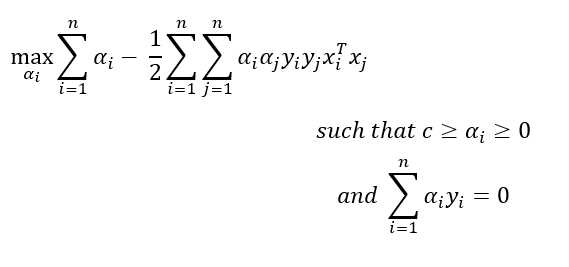
等等!我们怎么得到这个对偶形式的?
这都和最优化有关如果我们深入研究这个问题,我们就会偏离我们的目标。让我们在另一个博客中讨论这个对偶形式。
为什么我们需要这个对偶形式?
对偶形式有时更容易解决,如果对偶间隙非常小,我们会得到相似的结果。特别是支持向量机:对偶形式非常重要,因为它通过核函数开启了一种解释支持向量机的新方法(我将在本博客的后面部分告诉你)。
注意:在对偶形式中,所有x?都以点积的形式出现,不像原始形式中所有x?都作为独立点出现。
α?可以被认为是一个拉格朗日乘数
观察对偶形式:
- 对于每个x?,有相应的α?
- 所有x?都是点积的形式
- 我们对一个新点的分类方式改变如下:
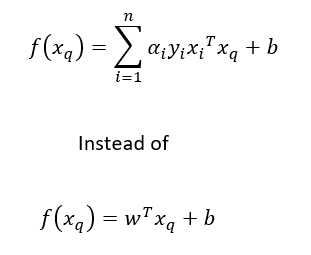
- 支持向量α?>0,非支持向量α?=0。
这意味着只有支持向量才是重要的,这就是将该模型命名为支持向量机的原因。
现在,以对偶形式
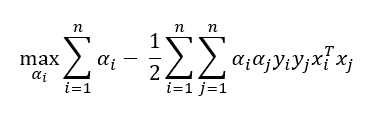
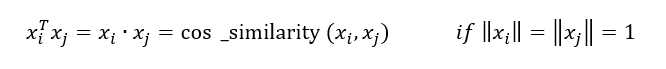
因此,如果给出一个相似矩阵,我们可以使用对偶形式,而不是原始形式。这就是支持向量机的优点。通常,这种相似性(x?,x?)被K(x?,x?)代替,其中K称为核函数。
核技巧及其背后的直觉
用核函数K(x?,x?)替换相似性(x?,x?)称为核化,或应用核技巧。
如果你看它,它只是计算x?和x?的点积。那么,有什么了不起的?
让我们以下面的数据集为例。
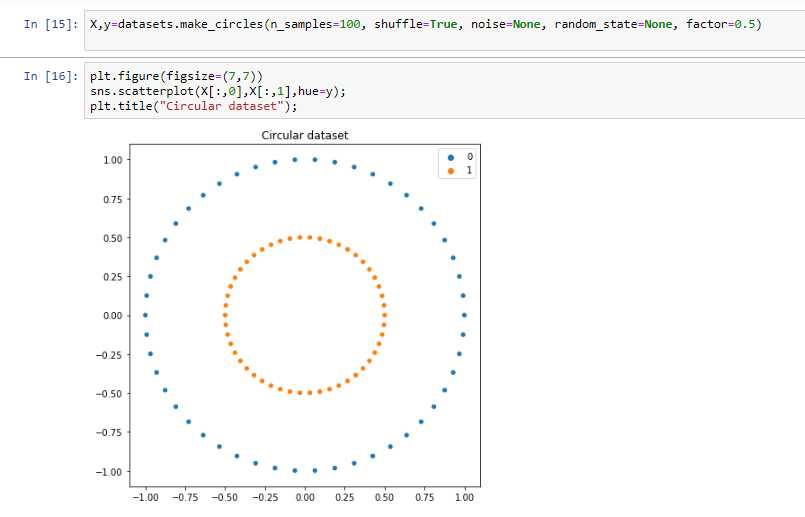
很明显,在线性模型的帮助下,这两个类是不能分离的。
现在,将数据集转换为具有 <x?2,x?2,2x?x?> 的特征的多维数据集。
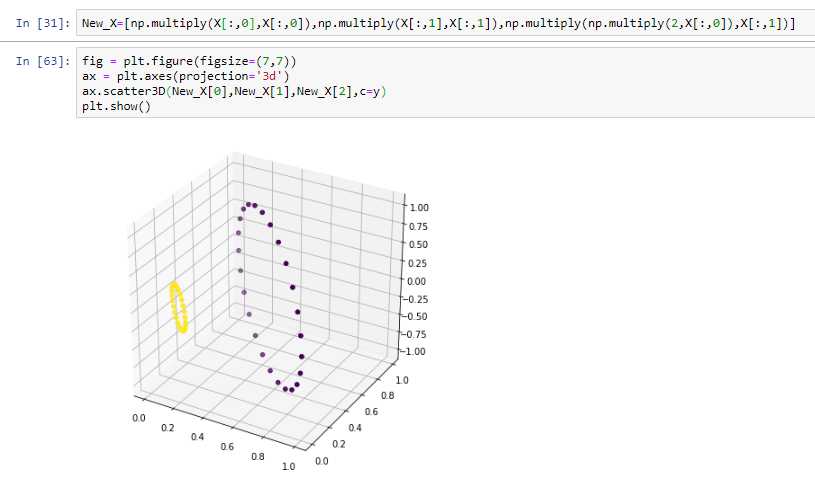
你看到了吗?应用适当的特征变换和增加维数使数据线性可分。
这就是核支持向量机的作用。它将原始特征映射到一个高维空间中,在该空间中找到间隔最大的超平面,并将该超平面映射到原始维空间中,得到一个非线性决策曲面,而不必实际访问该高维空间。
所以
线性支持向量机:在x?的空间中寻找间隔最大化超平面
核支持向量机:在x?的变换空间中寻找间隔最大化超平面
因此,核支持向量机也能求解非线性可分数据集。
让我们看看支持向量机中使用的一些核函数-
多项式核
定义如下:
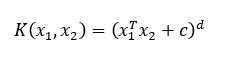
其中
d=数据维度
c=常数
对于二次核,设c=1,即
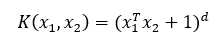
当维度为2
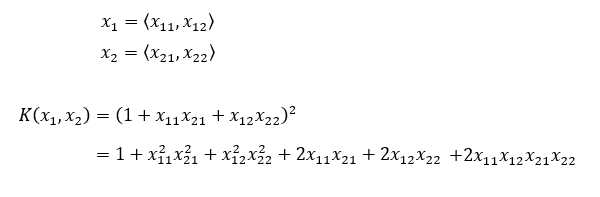
这可以被认为是2个向量x?和x?的乘积,其中:
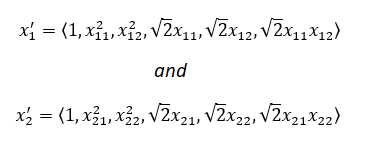
现在维度=d‘=6
因此,核化与特征转换是一样的,但通常是d‘>d,核化是在内部隐式地完成的。
径向基函数(RBF核)
它是最受欢迎的核,因为你无法确定要选择哪个核时,可以选择它
定义如下:
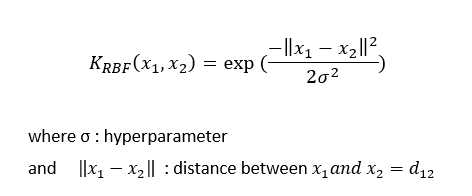
d的效果:
当d增大时,指数部分的分子减小,换句话说,K值或相似度减小。
σ的影响:
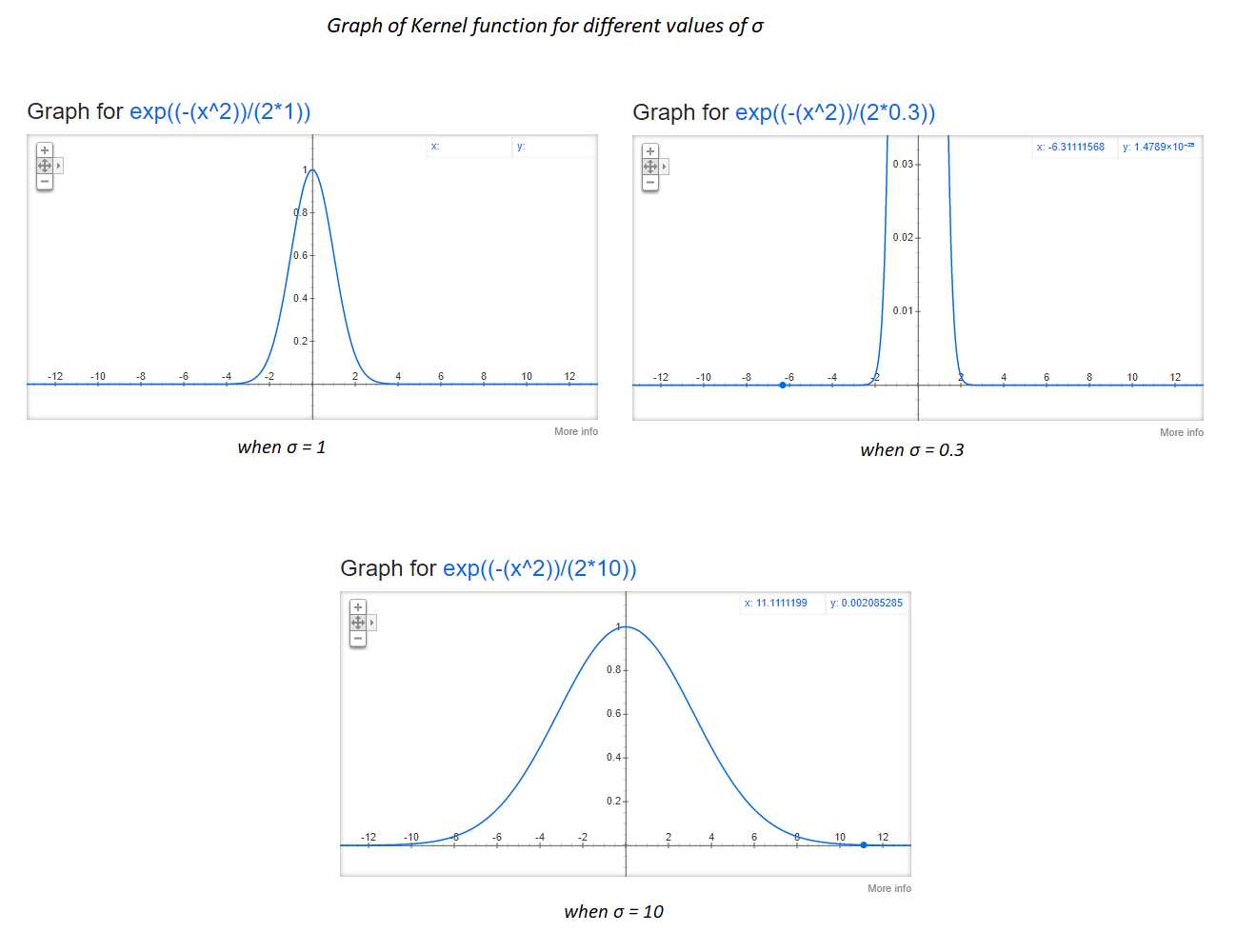
如果你注意,当σ=0.3,在x=2,接近于0。在x = 4,σ= 1时和x = 11,σ= 10,它接近0。这表明当σ增加时,即使两个点是很远,相似的score可能也不会很低。
例如假设有两个点x?和x?的距离为4个单元。如果我们应用σ= 0.3的RBF核,核函数K值或相似值是0。如果我们设置σ= 1,K值很接近0,但如果我们设置σ= 10,K值约为0.4左右。
现在说明RBF核背后的直觉
还记得我们在使用多项式核函数时得到的6维映射函数吗?现在让我们尝试找出RBF核的一个映射函数。
为了简化数学,假设原始数据的维数为2,指数部分的分母为1。在这种情况下,
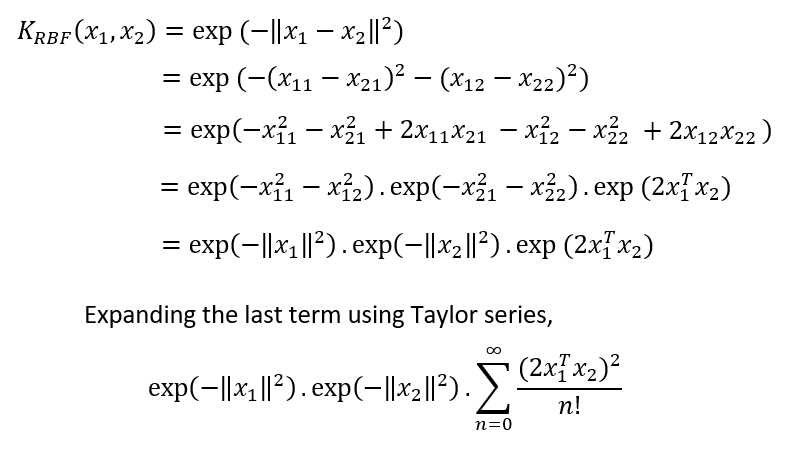
如果我们试图找出RBF核的映射函数,就会得到一个无限向量。这意味着RBF核需要我们的数据映射到无限维的空间,计算相似性得分并返回它,这就是为什么如果你不知道选择哪个核,RBF核函数将是最安全的选择。
用于回归的SVM
到目前为止,我们已经研究了如何使用支持向量机执行分类任务。但支持向量机不仅限于此。它也可以用来执行回归任务。怎样?让我们看看!
首先,让我们看看支持向量回归(SVR)的数学公式
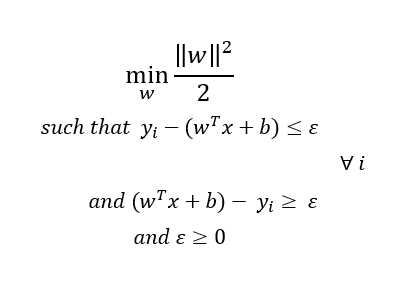
别担心!我帮助你理解。
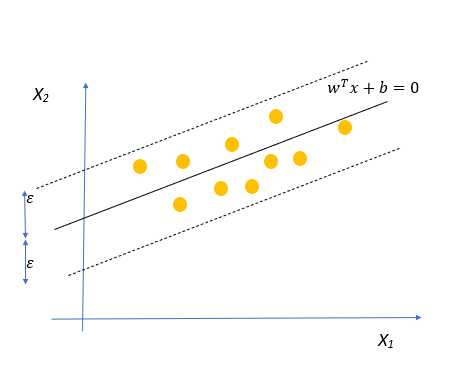
SVR的工作方式是,它试图找到一个最适合的数据点的超平面,同时保持一个软间隔=ε(超参数),这意味着所有的点都应该在超平面两侧ε距离。
最小化这里的边界意味着我们想要找到一个超平面,这个超平面以较低的误差来匹配数据。
注意:平方是为了使函数变得可微并适合于优化。对于SVC也可以这样做。
这个公式有什么问题?
这里的问题是,我们太严格,我们期望的点位于ε超平面的距离在现实世界并不经常发生。在这种情况下,我们将无法找到所需的超平面。那么,我们该怎么做呢?
与我们在SVC中处理这个问题的方法相同,我们将为法向点引入两个松弛变量ζ和ζ*,以允许某些点位于范围之外,但会受到惩罚。
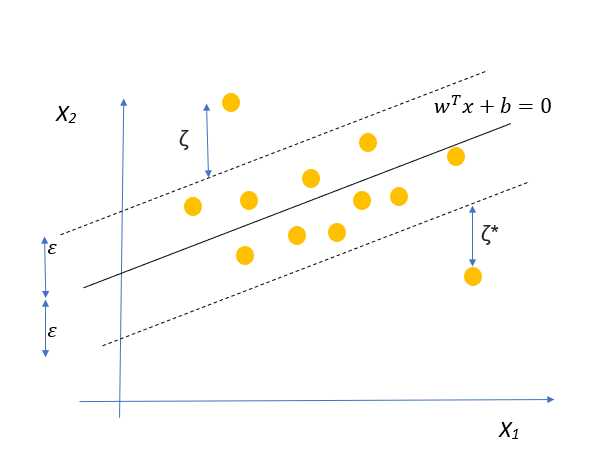
所以数学公式现在变成:
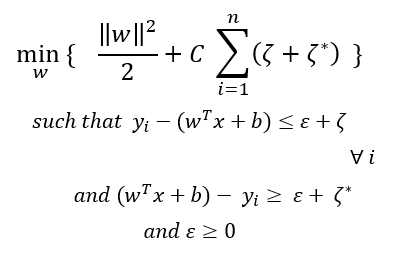
其中C确定所需的严格程度。C值越大,对边距外的点的惩罚就越多,这可能导致数据的过度拟合。更少的C意味着对边缘以外的点的惩罚更少,这可能导致数据拟合不足。
与SVC中一样,图显示了SVR的原始形式。结果表明,对偶形式更易于求解,并且可以利用核技巧求出非线性超平面。
正如我已经说过的,对偶形式的公式是有点棘手的,涉及解决约束优化问题的知识。我们不会深入讨论太多细节,因为这会转移我们对支持向量机的注意力。
SVR对偶形式
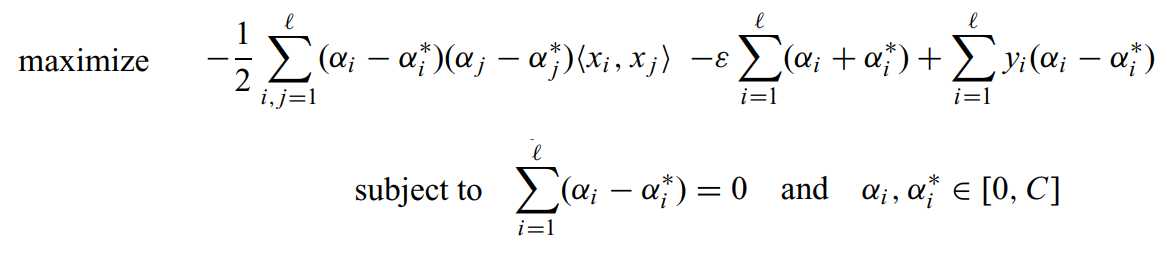
这是通过使用拉格朗日乘子求解优化问题得到的。
对于一个新的点,我们计算输出值的方法是:
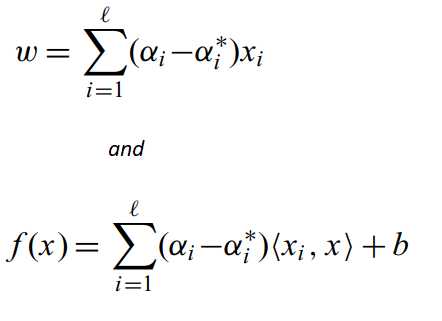
你有没有注意到,x?是点积的形式?是的,和我们在SVC中得到的一样。我们可以用前面提到的相似度或核函数来代替这个点积。应用核技巧还可以帮助我们拟合非线性数据。
支持向量机的各种情况
特征工程和特征转换,这是通过找到上面讨论的正确的核来实现的
决策面,对于线性支持向量机:决策曲面只是一个超平面,对于核支持向量机:它将是一个非线性曲面
相似函数/距离函数,支持向量机的原始形式不能处理相似函数。然而,因为x?点积的存在形式,对偶形式可以很容易地处理它。
特征的重要性,如果特征不是共线的,那么权重向量w中特征的权重决定了特征的重要性。如果特征是共线的,可以使用前向特征选择或后向特征消除,这是确定任何模型特征重要性的标准方法。
离群值,与其他模型如Logistic回归相比,支持向量机的影响较小。
偏差-方差,它依赖于支持向量机对偶形式中c的值。
如果c值较高,则误差项的权重较大,因此模型可能会对数据进行过拟合;如果c值较低,则误差项的权重较小,模型可能会对数据进行欠拟合。
- 高维度,支持向量机的设计可以很好地工作,即使在高维度。如图所示,支持向量机的数学公式中已经存在一个正则化项,有助于处理高维问题。你可能会说像KNN这样的其他模型并不适用于高维空间,那么SVMs有什么特别之处呢?这是因为支持向量机只关心找到使边距最大的平面,而不关心点之间的相对距离。
支持向量机的优点
- 它有一个正则化项,有助于避免数据的过拟合
- 它使用核技巧,这有助于处理甚至非线性数据(在SVR情况下)和非线性可分数据(在SVC情况下)
- 当我们不了解数据时,支持向量机是非常好的。
- 可以很好地处理非结构化和半结构化数据,比如文本、图像和树。
- 从某种意义上说,它是健壮的,即使在训练示例包含错误的情况下也能工作
支持向量机的局限性
- 选择正确的核是一项困难的任务。
- 支持向量机算法有多个超参数需要正确设置,以获得对任何给定问题的最佳分类结果。参数可能导致问题A的分类精度很好,但可能导致问题B的分类精度很差。
- 当支持向量机的数据点数目较大时,训练时间较长。
- 对于核支持向量机,其权向量w的解析比较困难。
参考
- https://alex.smola.org/papers/2004/SmoSch04.pdf
- https://www.saedsayad.com/support_vector_machine_reg.htm
- https://statinfer.com/204-6-8-svm-advantages-disadvantages-applications/
- http://www.cs.uky.edu/~jzhang/CS689/PPDM-Chapter2.pdf
原文链接:https://medium.com/@anujshrivastav97/demystifying-support-vector-machine-b04d202bf11e
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
以上是关于详解支持向量机的主要内容,如果未能解决你的问题,请参考以下文章