跑google-BERT的fine-tune阶段时内存不足
Posted okcokc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跑google-BERT的fine-tune阶段时内存不足相关的知识,希望对你有一定的参考价值。
背景
毕业论文选择了文本处理的情感分析。交了论文的初稿后,导师看了觉得写得不错,希望我冲击一下优秀论文,给我推荐了bert算法让我再去跑一趟。本是第一次接触NLP的我又去看了这个前2年才由谷歌开发出来的算法,简直头皮发麻。在google开源代码的run_classifier.py里添加了自己的Processor之后,便用它来跑自己的数据集。
问题的出现与解决
运行报错如下:
NotFoundError: No registered ‘_CopyFromGpuToHost‘ OpKernel for CPU devices compatible with node swap_out_gradients/bert/encoder/layer_0/output/dense/MatMul_grad/MatMul_1_0 = _CopyFromGpuToHostT=DT_FLOAT, _class=["loc@gradients/bert/encoder/layer_0/output/dense/MatMul_grad/MatMul_1_0"], _device="/job:localhost/replica:0/task:0/device:CPU:0"
. Registered: device=‘GPU‘
[[Node: swap_out_gradients/bert/encoder/layer_0/output/dense/MatMul_grad/MatMul_1_0 = _CopyFromGpuToHost[T=DT_FLOAT, _class=["loc@gradients/bert/encoder/layer_0/output/dense/MatMul_grad/MatMul_1_0"], _device="/job:localhost/replica:0/task:0/device:CPU:0"](bert/encoder/layer_0/intermediate/dense/mul_1/_4059)]]
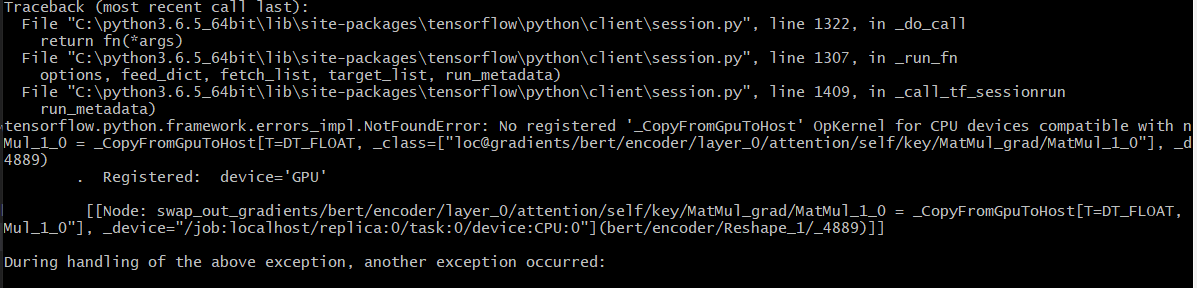
问题困扰了大半天,搜索引擎上的各种方法都尝试过了一次,仍旧无法解决,询问导师也无果。最终没办法,打算上github给google提issue。结果鬼使神差的在issue看到了同样的问题,有人回复自己遇到这个问题时改小了批处理的尺寸解决了。
按照前人的经验立马修改了运行.py文件时的参数train_batch_size,将值从32慢慢调小到1终于可以跑了。

实际上,当自己遇到问题时,更多的情况下是自行搜索解决方法,其次是咨询身边的人。当二者都不能解决问题时,才会考虑到博客、issue等询问他人。毫无疑问,一般相关问题的博主肯定更加了解自己遇到的问题;然而我的选择却不是第一时间向他们咨询,这或多或少受到平常所用的即时通讯软件影响。博主不会时刻盯着提问,自己也不会时刻盯着回答;相较之下自己还是更加倾向于相对低效但更加即时的获取答案方式。
以上是关于跑google-BERT的fine-tune阶段时内存不足的主要内容,如果未能解决你的问题,请参考以下文章