迁移学习fine-tune和局部参数恢复
Posted qqw-1995
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了迁移学习fine-tune和局部参数恢复相关的知识,希望对你有一定的参考价值。
一、迁移学习
就是把已训练好的模型参数迁移到新的模型来帮助新模型训练。
模型的训练与预测:
深度学习的模型可以划分为 训练 和 预测 两个阶段。
训练 分为两种策略:一种是白手起家从头搭建模型进行训练,一种是通过预训练模型进行训练。
预测 相对简单,直接用已经训练好的模型对数据集进行预测即可。

优点:
1)站在巨人的肩膀上:前人花很大精力训练出来的模型在大概率上会比你自己从零开始搭的模型要强悍,没有必要重复造轮子。
2)训练成本可以很低:如果采用导出特征向量的方法进行迁移学习,后期的训练成本非常低,用CPU都完全无压力,没有深度学习机器也可以做。
3)适用于小数据集:对于数据集本身很小(几千张图片)的情况,从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。这时候如果还想用上大型神经网络的超强特征提取能力,只能靠迁移学习。
迁移学习的几种方式:
1、Transfer Learning:冻结预训练模型的全部卷积层,只训练自己定制的全连接层。
2、Extract Feature Vector:先计算出预训练模型的卷积层对所有训练和测试数据的特征向量,然后抛开预训练模型,只训练自己定制的简配版全连接网络。
3、Fine-tune:冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
* 注:Transfer Learning关心的问题是:什么是“知识”以及如何更好地运用之前得到的“知识”,这可以有很多方法和手段,eg:SVM,贝叶斯,CNN等。
而fine-tune只是其中的一种手段,更常用于形容迁移学习的后期微调中。
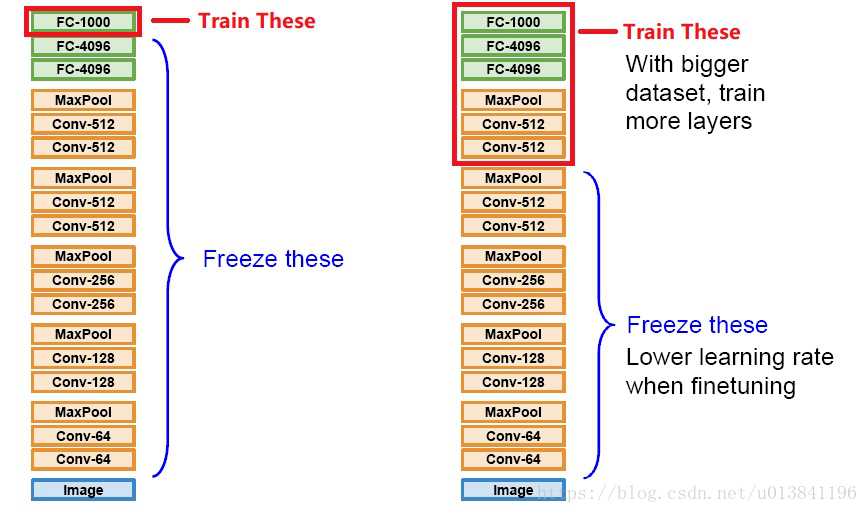
三种迁移学习方式对比
1、第一种和第二种训练得到的模型本质上并没有什么区别,但是第二种的计算复杂度要远远优于第一种。
2、第三种是对前两种方法的补充,以进一步提升模型性能。要注意的是,这种方法并不一定能真的对模型有所提升。
本质上来讲:这三种迁移学习的方式都是为了让预训练模型能够胜任新数据集的识别工作,能够让预训练模型原本的特征提取能力得到充分的释放和利用。但是,在此基础上如果想让模型能够达到更低的Loss,那么光靠迁移学习是不够的,靠的更多的还是模型的结构以及新数据集的丰富程度。
二、实验:尝试对模型进行微调,以进一步提升模型性能
1、fine-tune的作用:
拿到新数据集,先用预训练模型处理,通常用上面的方法一或方法二测试预训练模型在新数据上的表现,如果表现不错,可以尝试fine-tune,进一步解锁卷积层以继续训练。
但是不要期待质的飞跃,另外,如果由于新数据集与原数据集差别太大导致表现很差,一方面可以考虑从头训练,另一方面也可以考虑解锁比较多层的训练。
2、不同数据集下使用微调
数据集1:数据量少,但数据相似度非常高
在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别,方法一
数据集2:数据量少,数据相似度低
在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。方法三
数据集3:数据量大,数据相似度低
在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。
数据集4:数据量大,相似度高
这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
3.微调的注意事项
1)通常的做法是截断预先训练好的网络的最后一层(softmax层),并用与我们自己的问题相关的新的softmax层替换它。
2)使用较小的学习率来训练网络。
3)如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。
注:卷积神经网络的核心是:
(1)浅层卷积层提取基础特征,比如边缘,轮廓等基础特征。
(2)深层卷积层提取抽象特征,比如整个脸型。
(3)全连接层根据特征组合进行评分分类。
4、实验操作具体步骤
1、下载预训练模型
2、预处理:按照预训练模型原本的预处理方式对数据进行预处理,使用预训练模型一定要确保让待训练的数据尽可能向原数据集靠拢,这样才能最大程度发挥模型的识图本领。
3、基模型和定制模型:构建和预训练里面完全相同的模型。
4、查看固定和恢复节点名
5、训练过程设置恢复,固定张量的列表
三、代码详情
基模型和定制模型
import slim.nets.resnet_v1 as resnet_v1 # 定义模型,因为给出的只有参数,并没有模型,这里需要指定模型的具体结构 with slim.arg_scope(resnet_v1.resnet_arg_scope()): # logits就是最后预测值,images就是输入数据,指定num_classes=None是为了使resnet模型最后的输出层禁用 logits, end_points = resnet_v1.resnet_v1_50(inputs=input_images, num_classes=None) # 自定义的输出层 with tf.variable_scope("Logits"): # 将原始模型的输出数据去掉维度为2和3的维度,最后只剩维度1的batch数和维度4的300*300*3 # 也就是将原来的二三四维度全部压缩到第四维度 net = tf.squeeze(logits, axis=[1, 2]) # 加入一层dropout层 net = slim.dropout(net, keep_prob=0.5, scope=‘dropout_scope‘) # 加入一层全连接层,指定最后输出大小 logits = slim.fully_connected(net, num_outputs=labels_nums, scope=‘fc‘)
查看固定和恢复节点名
look_checkpoint.py
import os from tensorflow.python import pywrap_tensorflow model_dir = os.getcwd() # 获取当前文件工作路径 print(model_dir)#输出当前工作路径 checkpoint_path = r‘G:\\1-modelused\\Siamese_Densenet_Single_Net\\output\\640model\\model3/model_epoch_20.ckpt‘#model_dir + "\\\\ckpt_dir\\\\model-ckpt-100" print(checkpoint_path)#输出读取的文件路径 # 从checkpoint文件中读取参数 reader = pywrap_tensorflow.NewCheckpointReader(checkpoint_path) var_to_shape_map = reader.get_variable_to_shape_map() # 输出变量名称及变量值 for key in var_to_shape_map: # if key.startswith(‘DenseNet_121/AuxLogits‘): # print(1) # print(key) print("tensor_name: ", key)
训练过程设置恢复,固定张量的列表
CKPT_FILE = r‘.\\pretrain\\resnet_v1_50.ckpt‘ #不需要从谷歌训练好的模型中加载的参数。这里就是最后的全连接层,因为在新的问题中要重新训练这一层中的参数。 #这里给出的是参数的前缀 CHECKPOINT_EXCLUDE_SCOPES = ‘Logits‘ ## 指定最后的全连接层为可训练的参数,需要训练的网络层参数名称,在fine-tuning的过程中就是最后的全连接层 TRAINABLE_SCOPES = ‘Logits‘ #获取所有需要从谷歌训练好的模型中加载的参数 def get_tuned_variables(): exclusions = [scope.strip() for scope in CHECKPOINT_EXCLUDE_SCOPES.split(‘,‘)] variables_to_restore = [] #枚举inception-v3模型中所有的参数,然后判断是否需要从加载列表中移除 for var in slim.get_model_variables(): excluded = False for exclusion in exclusions: if var.op.name.startswith(exclusion): excluded = True break if not excluded: variables_to_restore.append(var) return variables_to_restore #获取所有需要训练的变量列表。 def get_trainable_variables(): scopes = [scope.strip() for scope in TRAINABLE_SCOPES.split(‘,‘)] variables_to_train = [] #枚举所有需要训练的参数前缀,并通过这些前缀找到所有的参数。 for scope in scopes: variables = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,scope) variables_to_train.extend(variables) return variables_to_train #定义加载Google训练好的Inception-v3模型的Saver load_fn = slim.assign_from_checkpoint_fn( CKPT_FILE, get_tuned_variables(), ignore_missing_vars=True ) saver = tf.train.Saver(max_to_keep=100) max_acc = 0.0 with tf.Session() as sess: ckpt = tf.train.get_checkpoint_state(‘models/resnet_v1/‘) if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path): saver.restore(sess, ckpt.model_checkpoint_path) else: sess.run(tf.global_variables_initializer()) sess.run(tf.local_variables_initializer()) # 加载谷歌已经训练好的模型 print(‘Loading tuned variables from %s‘ % CKPT_FILE) load_fn(sess)
以上是关于迁移学习fine-tune和局部参数恢复的主要内容,如果未能解决你的问题,请参考以下文章