Flink状态管理详解:Keyed State和Operator List State深度解析
Posted felixzh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink状态管理详解:Keyed State和Operator List State深度解析相关的知识,希望对你有一定的参考价值。
为什么要管理状态
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。下面的几个场景都需要使用流处理的状态功能:
- 数据流中的数据有重复,我们想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。
- 检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
- 对一个时间窗口内的数据进行聚合分析,分析一个小时内某项指标的75分位或99分位的数值。
- 在线机器学习场景下,需要根据新流入数据不断更新机器学习的模型参数。
我们知道,Flink的一个算子有多个子任务,每个子任务分布在不同实例上,我们可以把状态理解为某个算子子任务在其当前实例上的一个变量,变量记录了数据流的历史信息。当新数据流入时,我们可以结合历史信息来进行计算。实际上,Flink的状态是由算子的子任务来创建和管理的。一个状态更新和获取的流程如下图所示,一个算子子任务接收输入流,获取对应的状态,根据新的计算结果更新状态。一个简单的例子是对一个时间窗口内输入流的某个整数字段求和,那么当算子子任务接收到新元素时,会获取已经存储在状态中的数值,然后将当前输入加到状态上,并将状态数据更新。
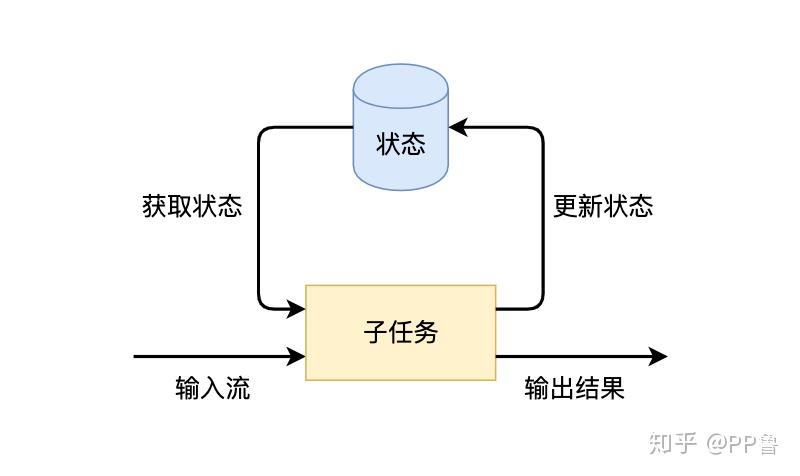
获取和更新状态的逻辑其实并不复杂,但流处理框架还需要解决以下几类问题:
- 数据的产出要保证实时性,延迟不能太高。
- 需要保证数据不丢不重,恰好计算一次,尤其是当状态数据非常大或者应用出现故障需要恢复时,要保证状态的计算不出任何错误。
- 一般流处理任务都是7*24小时运行的,程序的可靠性非常高。
基于上述要求,我们不能将状态直接交由内存管理,因为内存的容量是有限制的,当状态数据稍微大一些时,就会出现内存不够的问题。假如我们使用一个持久化的备份系统,不断将内存中的状态备份起来,当流处理作业出现故障时,需要考虑如何从备份中恢复。而且,大数据应用一般是横向分布在多个节点上,流处理框架需要保证横向的伸缩扩展性。可见,状态的管理并不那么容易。
作为一个计算框架,Flink提供了有状态的计算,封装了一些底层的实现,比如状态的高效存储、Checkpoint和Savepoint持久化备份机制、计算资源扩缩容等问题。因为Flink接管了这些问题,开发者只需调用Flink API,这样可以更加专注于业务逻辑。
Flink的几种状态类型
Managed State和Raw State
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)。从名称中也能读出两者的区别:Managed State是由Flink管理的,Flink帮忙存储、恢复和优化,Raw State是开发者自己管理的,需要自己序列化。

两者的具体区别有:
- 从状态管理的方式上来说,Managed State由Flink Runtime托管,状态是自动存储、自动恢复的,Flink在存储管理和持久化上做了一些优化。当我们横向伸缩,或者说我们修改Flink应用的并行度时,状态也能自动重新分布到多个并行实例上。Raw State是用户自定义的状态。
- 从状态的数据结构上来说,Managed State支持了一系列常见的数据结构,如ValueState、ListState、MapState等。Raw State只支持字节,任何上层数据结构需要序列化为字节数组。使用时,需要用户自己序列化,以非常底层的字节数组形式存储,Flink并不知道存储的是什么样的数据结构。
- 从具体使用场景来说,绝大多数的算子都可以通过继承Rich函数类或其他提供好的接口类,在里面使用Managed State。Raw State是在已有算子和Managed State不够用时,用户自定义算子时使用。
下文将重点介绍Managed State。
Keyed State和Operator State
对Managed State继续细分,它又有两种类型:Keyed State和Operator State。这里先简单对比两种状态,后续还将展示具体的使用方法。
Keyed State是KeyedStream上的状态。假如输入流按照id为Key进行了keyBy分组,形成一个KeyedStream,数据流中所有id为1的数据共享一个状态,可以访问和更新这个状态,以此类推,每个Key对应一个自己的状态。下图展示了Keyed State,因为一个算子子任务可以处理一到多个Key,算子子任务1处理了两种Key,两种Key分别对应自己的状态。
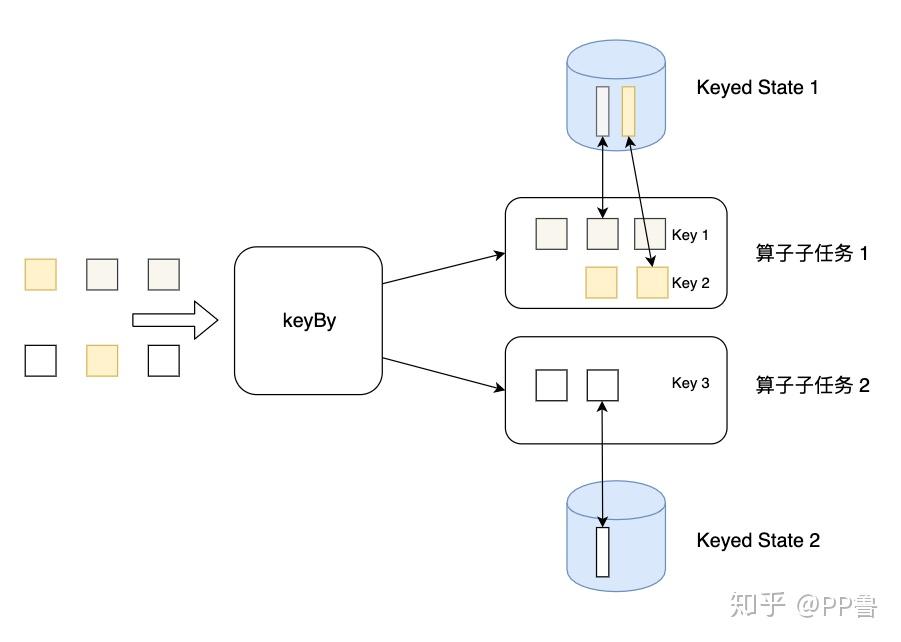
Operator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。下图展示了Operator State,算子子任务1上的所有数据可以共享第一个Operator State,以此类推,每个算子子任务上的数据共享自己的状态。
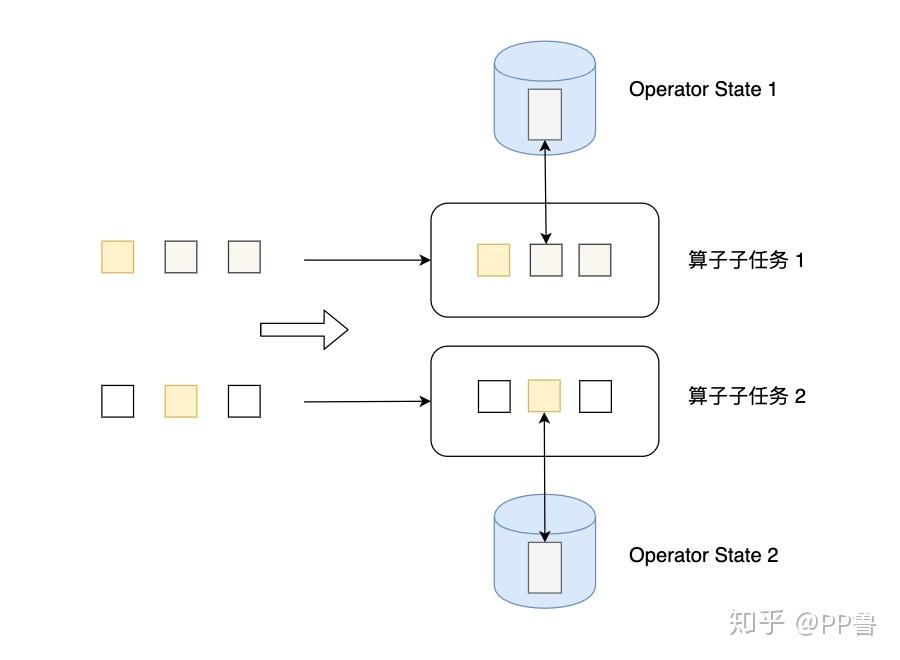
无论是Keyed State还是Operator State,Flink的状态都是基于本地的,即每个算子子任务维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。
在之前各算子的介绍中曾提到,为了自定义Flink的算子,我们可以重写Rich Function接口类,比如RichFlatMapFunction。使用Keyed State时,我们也可以通过重写Rich Function接口类,在里面创建和访问状态。对于Operator State,我们还需进一步实现CheckpointedFunction接口。

上表总结了Keyed State和Operator State的区别。
横向扩展问题
状态的横向扩展问题主要是指修改Flink应用的并行度,确切的说,每个算子的并行实例数或算子子任务数发生了变化,应用需要关停或启动一些算子子任务,某份在原来某个算子子任务上的状态数据需要平滑更新到新的算子子任务上。其实,Flink的Checkpoint就是一个非常好的在各算子间迁移状态数据的机制。算子的本地状态将数据生成快照(snapshot),保存到分布式存储(如HDFS)上。横向伸缩后,算子子任务个数变化,子任务重启,相应的状态从分布式存储上重建(restore)。
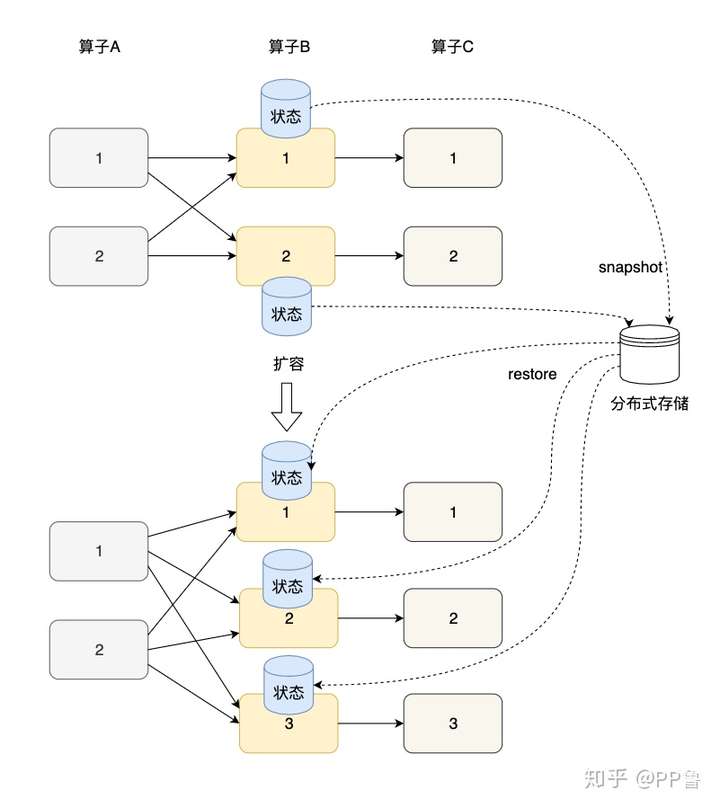
对于Keyed State和Operator State这两种状态,他们的横向伸缩机制不太相同。由于每个Keyed State总是与某个Key相对应,当横向伸缩时,Key总会被自动分配到某个算子子任务上,因此Keyed State会自动在多个并行子任务之间迁移。对于一个非KeyedStream,流入算子子任务的数据可能会随着并行度的改变而改变。如上图所示,假如一个应用的并行度原来为2,那么数据会被分成两份并行地流入两个算子子任务,每个算子子任务有一份自己的状态,当并行度改为3时,数据流被拆成3支,或者并行度改为1,数据流合并为1支,此时状态的存储也相应发生了变化。对于横向伸缩问题,Operator State有两种状态分配方式:一种是均匀分配,另一种是将所有状态合并,再分发给每个实例上。
Keyed State的使用方法
对于Keyed State,Flink提供了几种现成的数据结构供我们使用,包括ValueState、ListState等,他们的继承关系如下图所示。首先,State主要有三种实现,分别为ValueState、MapState和AppendingState,AppendingState又可以细分为ListState、ReducingState和AggregatingState。
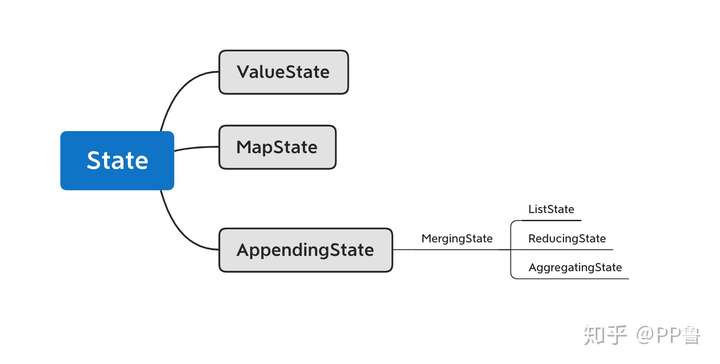
这几个状态的具体区别在于:
ValueState[T]是单一变量的状态,T是某种具体的数据类型,比如Double、String,或我们自己定义的复杂数据结构。我们可以使用value()方法获取状态,使用update(value: T)更新状态。MapState[K, V]存储一个Key-Value map,其功能与Java的Map几乎相同。get(key: K)可以获取某个key下的value,put(key: K, value: V)可以对某个key设置value,contains(key: K)判断某个key是否存在,remove(key: K)删除某个key以及对应的value,entries(): java.lang.Iterable[java.util.Map.Entry[K, V]]返回MapState中所有的元素,iterator(): java.util.Iterator[java.util.Map.Entry[K, V]]返回一个迭代器。需要注意的是,MapState中的key和Keyed State的key不是同一个key。ListState[T]存储了一个由T类型数据组成的列表。我们可以使用add(value: T)或addAll(values: java.util.List[T])向状态中添加元素,使用get(): java.lang.Iterable[T]获取整个列表,使用update(values: java.util.List[T])来更新列表,新的列表将替换旧的列表。ReducingState[T]和AggregatingState[IN, OUT]与ListState[T]同属于MergingState[T]。与ListState[T]不同的是,ReducingState[T]只有一个元素,而不是一个列表。它的原理是新元素通过add(value: T)加入后,与已有的状态元素使用ReduceFunction合并为一个元素,并更新到状态里。AggregatingState[IN, OUT]与ReducingState[T]类似,也只有一个元素,只不过AggregatingState[IN, OUT]的输入和输出类型可以不一样。ReducingState[T]和AggregatingState[IN, OUT]与窗口上进行ReduceFunction和AggregateFunction很像,都是将新元素与已有元素做聚合。
注意,Flink的核心代码目前使用Java实现的,而Java的很多类型与Scala的类型不太相同,比如List和Map。这里不再详细解释Java和Scala的数据类型的异同,但是开发者在使用Scala调用这些接口,比如状态的接口,需要注意将Java的类型转为Scala的类型。对于List和Map的转换,只需要需要引用import scala.collection.JavaConversions._,并在必要的地方添加后缀asScala或asJava来进行转换。此外,Scala和Java的空对象使用习惯不太相同,Java一般使用null表示空,Scala一般使用None。
之前的文章中其实已经多次使用过状态,这里再次使用电商用户行为分析来演示如何使用状态。我们知道电商平台会将用户与商品的交互行为收集记录下来,行为数据主要包括几个字段:userId、itemId、categoryId、behavior和timestamp。其中userId和itemId分别代表用户和商品的唯一ID,categoryId为商品类目ID,behavior表示用户的行为类型,包括点击(pv)、购买(buy)、加购物车(cart)、喜欢(fav)等,timestamp记录行为发生时间。本文采用阿里巴巴提供的一个淘宝用户行为数据集,为了精简需要,只节选了部分数据。下面的代码使用MapState[String, Int]记录某个用户某种行为出现的次数。这里读取了数据集文件,模拟了一个淘宝用户行为数据流。
/**
* 用户行为
* categoryId为商品类目ID
* behavior包括点击(pv)、购买(buy)、加购物车(cart)、喜欢(fav)
* */
case class UserBehavior(userId: Long,
itemId: Long,
categoryId: Int,
behavior: String,
timestamp: Long)
class MapStateFunction extends RichFlatMapFunction[UserBehavior, (Long, String, Int)] {
// 指向MapState的句柄
private var behaviorMapState: MapState[String, Int] = _
override def open(parameters: Configuration): Unit = {
// 创建StateDescriptor
val behaviorMapStateDescriptor = new MapStateDescriptor[String, Int]("behaviorMap", classOf[String], classOf[Int])
// 通过StateDescriptor获取运行时上下文中的状态
behaviorMapState = getRuntimeContext.getMapState(behaviorMapStateDescriptor)
}
override def flatMap(input: UserBehavior, collector: Collector[(Long, String, Int)]): Unit = {
var behaviorCnt = 1
// behavior有可能为pv、cart、fav、buy等
// 判断状态中是否有该behavior
if (behaviorMapState.contains(input.behavior)) {
behaviorCnt = behaviorMapState.get(input.behavior) + 1
}
// 更新状态
behaviorMapState.put(input.behavior, behaviorCnt)
collector.collect((input.userId, input.behavior, behaviorCnt))
}
}
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(8)
// 获取数据源
val sourceStream: DataStream[UserBehavior] = env
.addSource(new UserBehaviorSource("state/UserBehavior-50.csv")).assignTimestampsAndWatermarks(new AscendingTimestampExtractor[UserBehavior]() {
override def extractAscendingTimestamp(userBehavior: