数据可视化分析历年电影票房(数据读取过滤分类绘图)
Posted -ashe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据可视化分析历年电影票房(数据读取过滤分类绘图)相关的知识,希望对你有一定的参考价值。
本次案例主要用到numpy,pandas和matplotlib。期中pandas中的groupby分组方法较为重要,matplotlib中可以对画图进行更详细的设置,比如设置x、y轴刻度、折线宽度和样式以及颜色等等。
如图部分所示,这是一个关于对历年电影的数据,期中包括电影名称,年份、导演、票房收入等等。
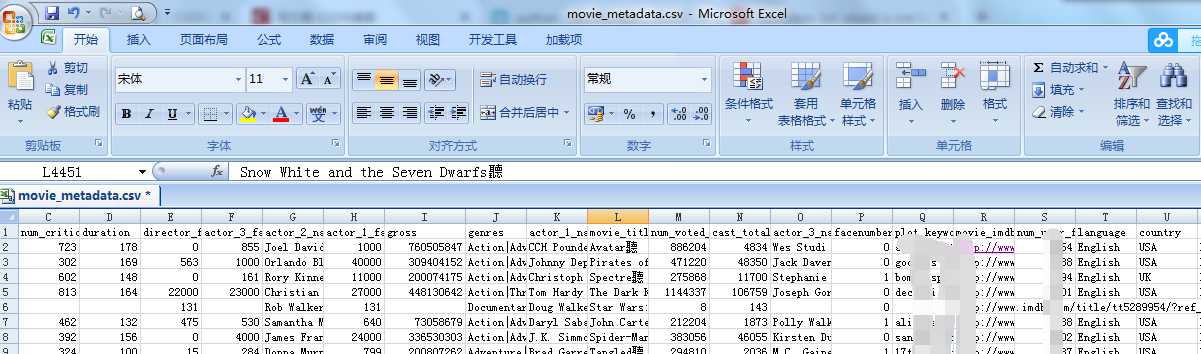
(1)读取文件、处理缺省值
import numpy as np import pandas as pd from matplotlib import pyplot as plt import matplotlib #读取数据 data = pd.read_csv(‘movie_metadata.csv‘) print(data.head())#读取数据前五行 print(data.shape)#打印数据的形状 效果如图所示,可以看到第4行有出现一些空值,这对我们做分局分析是不利的,接下来还需对数据中的空值做处理,清洗。: #处理缺省值,把一些空值进行滤除 data = data.dropna(how = ‘any‘) print(data.head())
(2)统计、分组
#查看票房收入统计 group_director= data.groupby(‘director_name‘)[‘gross‘].sum()#根据director_name进行分组,然后求gross列的和 #print(group_director.head()) #排列 result = group_director.sort_values(ascending=False)#按照降序方法进行排列 print(result) #sort_values函数参数使用: #ascending 是否按指定列的数组升序排列,默认为True,即升序排列 #inplace 是否用排序后的数据集替换原来的数据,默认为False,即不替换
效果如下,途中可以看出票房收入最高的是“Steven Spielberg(史蒂文·斯皮尔伯格)”,总的票房输入是4.114233e+09。
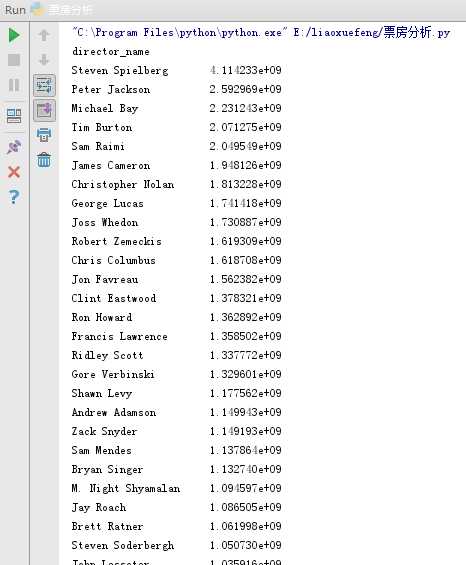
(3)
#电影产量年份图 movie_year = data.groupby(‘title_year‘)[‘movie_title‘].count() #计算每年的电影产量 #print(movie_year.index.tolist()) #print(movie_year.values.tolist()) #为x、y坐标赋值 x = (movie_year.index.tolist()) #把index索引值拿出来作为x轴,也就是年份,以列表形式输出。 y = movie_year.values.tolist()#把values值作为y轴,也就是每年的电影量的和。 #设置画布格式 #plt.xticks(range(len(x),10)) plt.figure(figsize=(20,8),dpi = 80) #设置画布大小为20,8,分析率为80. my_font=matplotlib.font_manager.FontProperties(fname=r‘C:WindowsFontssimsun.ttc‘,size = 18)#设置字体 #设置坐标轴标签 plt.xlabel(‘时间‘,fontproperties = my_font) #设置x轴标签 plt.ylabel(‘电影量‘,fontproperties = my_font)#设置y轴标签 plt.title(‘电影产量年份图‘,fontproperties = my_font,color = ‘red‘)#设置标题名称 #绘制折线图 plt.plot(x,y) plt.show()
具体效果如下,
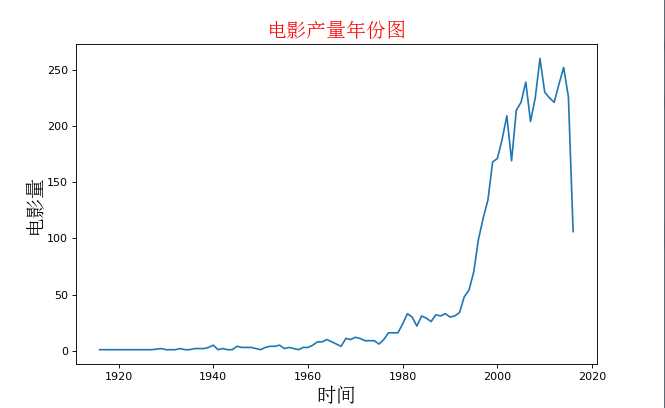
以上是关于数据可视化分析历年电影票房(数据读取过滤分类绘图)的主要内容,如果未能解决你的问题,请参考以下文章