地图构建两篇顶级论文解析
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了地图构建两篇顶级论文解析相关的知识,希望对你有一定的参考价值。
地图构建两篇顶级论文解析
一.基于声纳的密集水下场景重建
标题:Dense, Sonar-based Reconstruction of Underwater Scenes
作者:Pedro V. Teixeira, Dehann Fourie, Michael Kaess, and John J. Leonard
来源:IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS),2019
摘要
通常,重建问题分为三个独立的步骤:首先,根据前端的要求,使用传感器处理技术来过滤和分割传感器数据。其次,前端建立问题的因子图,以获得机器人完整轨迹的精确估计。最后,通过对传感器数据的进一步处理,得到最终结果,现在从优化的轨迹重新投影。在本文中,我们提出了一种将上述问题结合在一个特定应用框架下的重建问题建模方法:基于声纳的水下结构检测。这是通过将声纳分割和点云重建问题与SLAM问题一起作为因子图来实现的。我们用船体检验试验的数据提供了试验结果。
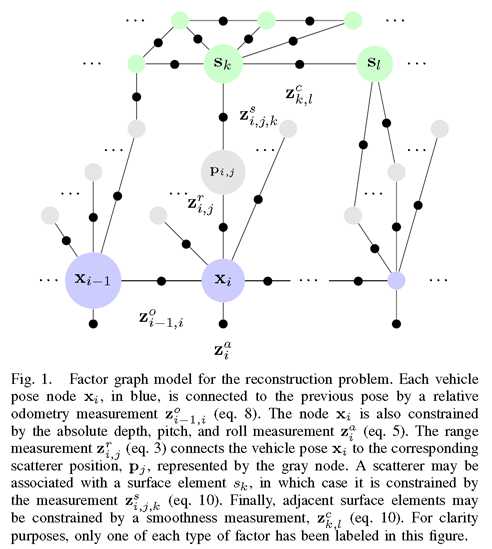
图1 重构问题的因子图模型
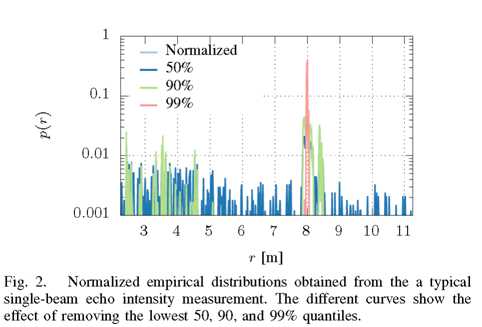
图2 典型单波束回波强度测量得到的归一化经验分布。不同的曲线显示了去除最低50、90和99%的效果。
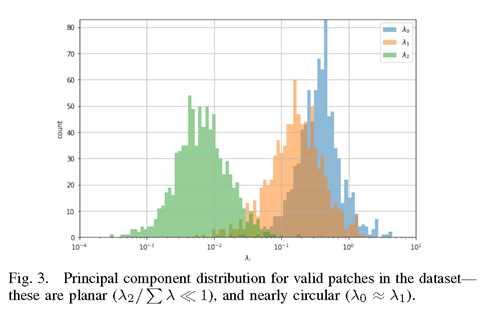
图3 数据集中有效像块的主成分分布-这些像块是平面的(??2/????1)和近似圆形的(??0≈??1)

图4 分割输出
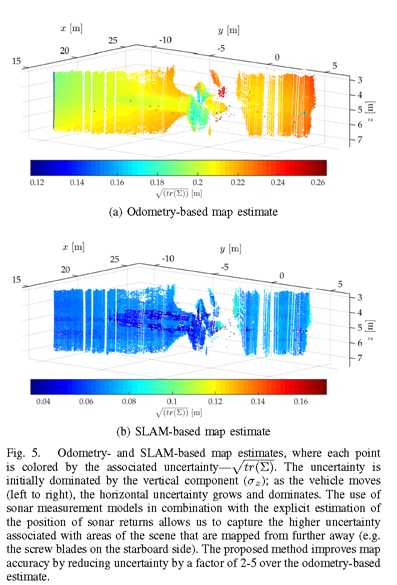
图5 基于里程和SLAM的地图估计
二.ElevateNet:一种用于估计2D水下声呐图像缺失维度的卷积神经网络
标题:ElevateNet: A Convolutional Neural Network for Estimating the Missing Dimension in 2D Underwater Sonar Images
作者:Robert DeBortoli, Fuxin Li, Geoffrey A. Hollinger
来源:2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
摘要
在这项工作中,我们解决的问题是从2D水下声纳图像预测缺失维度(仰角)。这些图像中由于非扩散反射等现象的存在造成的的高噪声水平经常会限制物理模型的实用性。因此,我们提出利用卷积神经网络(CNN)作为一种有效的方法来提取有用的信息而不会被嘈杂的数据所误导。我们还引进了一种自监督的方法,该方法利用声纳传感器的物理特性,在没有地面真值仰角图的情况下在真实数据上训练网络。仅给出单个图像,我们的方法就可以给出准确的仰角估计。最后,我们证明了在模拟和实际数据上,相比其他方法,我们的方法可以产生更准确的3D重建。
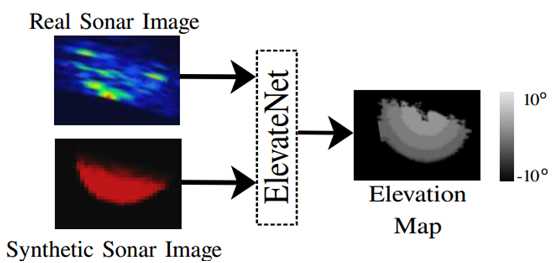
图1 ElevateNet 的输入和输出。向ElevateNet输入2D声呐图像(左),会产生仰角的像素级别的估计结果。当地面真值信息可用时,网络可以以监督的方式进行训练,使用合成数据的情况也一样。我们的方法在地面真值数据不可用时,也可以基于真实声呐图像在自监督方式下使用。
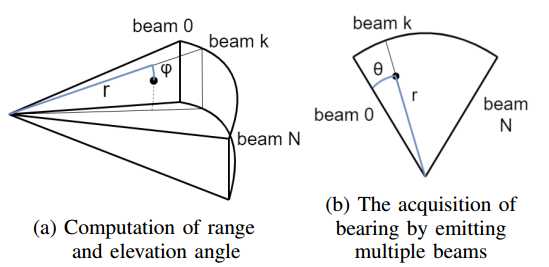
图2 从欧式坐标到极坐标的映射关系
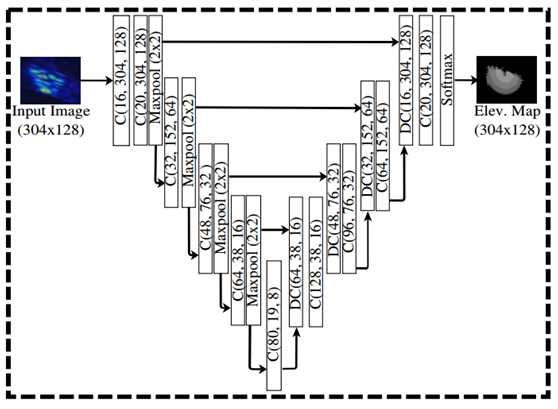
(a) ElevateNet的学习部分。C = 卷积/批正则化/ReLU层。DC=解卷积层。C(a,b,c)分别是卷积层的滤波器数量,输出图像宽度和高度。
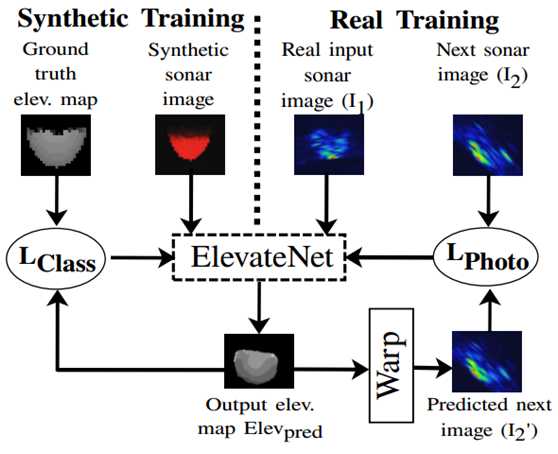
b) ElevateNet的训练方法。在合成数据上的训练(左循环)可以直接通过将网络输出与地面真值仰角图比较。在真实数据上的训练(右循环)使用输出来预测下一帧图像,并用光度误差应用在预测出的图像和真实的下一帧声呐图像比较中。
图3 我们的整体模型架构。(a)展示了可直接用于合成数据的ElevateNet详细模型参数。(b)介绍所使用的两种训练方法(分别针对合成数据和实际数据)。注意,图(a)和(b)中的虚线框表示的是同一个模型。

图4 实验中使用的Seabotix vLBV300和Gemini 720i成像声纳(右下角的白色矩形)
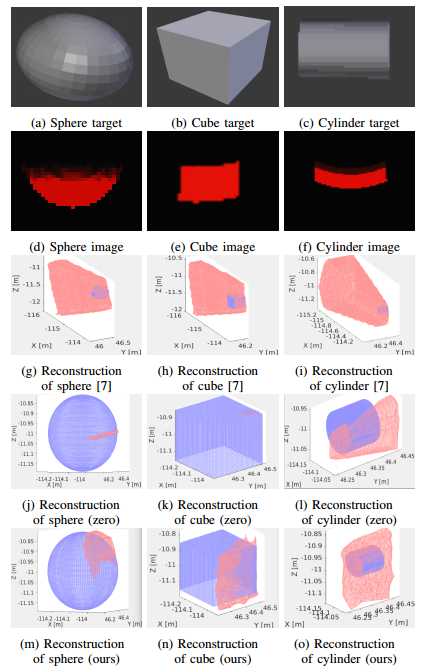
图5 合成声呐目标(a)-(c)、各自的合成声呐图像(d)-(f),一小部分图像的重建网格(g)-(o)。对于图(g)-(o),地面真值网格是蓝色的,预测网格是红色的。图(k)中预测的网格较小,但位于图像的右上角。在这些实验中,只能看到部分地面真实物体,因此预测网格只能覆盖物体的一部分。对于球体和立方体,我们的方法是唯一能够捕获成像对象的形状的方法。CNN将圆柱体当成立方体,因此会预测出一个垂直平面。
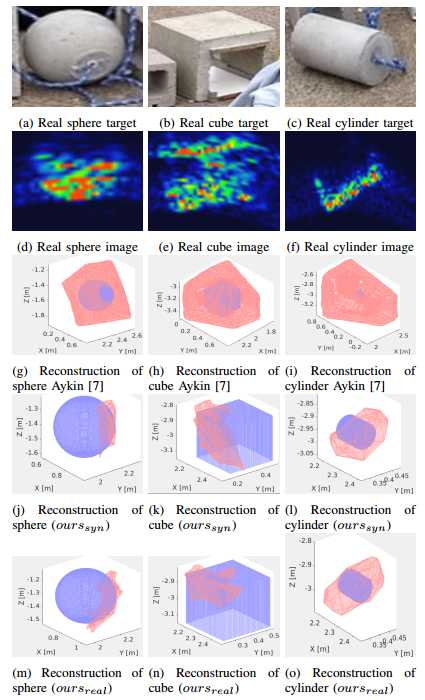
图6 真实声呐目标(a)-(c)、各自的声呐图像(d)-(f),使用Aykin方法得到的重建网格(g)-(i)。(j)-(l)和(m)-(o)分别是我们的模型不进行和进行真实训练的结果。网格中,地面真值使用蓝色进行标注,估计的网格用红色标注。由于我们只能看到物体的一部分,因此估计出的重建也只包括物体地面真值的一部分。对于球体和立方体,我们的方法可以在有限的视角条件下获得物体的形状。

表1 合成的像素级仰角的MAE(m)
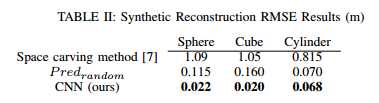
表2 合成重建RMSE结果(m)

表3 对下一帧估计结果的评估
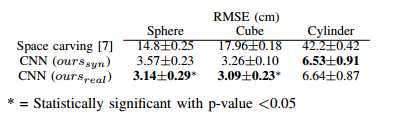
表4 在真实数据上的3D重建准确率
以上是关于地图构建两篇顶级论文解析的主要内容,如果未能解决你的问题,请参考以下文章