NVIDIA Tensor Cores解析
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NVIDIA Tensor Cores解析相关的知识,希望对你有一定的参考价值。
NVIDIA Tensor Cores解析
高性能计算机和人工智能前所未有的加速
Tensor Cores支持混合精度计算,动态调整计算以加快吞吐量,同时保持精度。最新一代将这些加速功能扩展到各种工作负载。NVIDIA Tensor内核为所有工作负载提供了新的能力,从革命性的新精度Tensor Float 32(TF32)人工智能训练中的10倍加速到浮点64(FP64)高性能计算的2.5倍加速。

Revolutionary AI Training
当人工智能模型面临更高层次的挑战时,如精确的对话人工智能和深度推荐系统,它们的复杂性继续爆炸。像威震天这样的对话人工智能模型比像ResNet-50这样的图像分类模型大数百倍,也更复杂。以FP32精度训练这些大型模型可能需要几天甚至几周的时间。NVIDIA GPU中的张量磁芯提供了一个数量级的更高性能,降低了TF32和FP16等精度。并通过NVIDIA CUDA-X在本机框架中直接支持™ 库中,实现是自动的,在保持准确性的同时,大大缩短了训练的收敛时间。
Breakthrough AI Inference
一个好的人工智能推理加速器不仅要有很好的性能,还要有多功能性来加速不同的神经网络,同时还要有可编程性,使开发人员能够构建新的神经网络。高吞吐量的低延迟同时最大化利用率是可靠部署推理的最重要性能要求。NVIDIA Tensor Cores提供全系列精度——TF32、bfloat16、FP16、INT8和INT4,提供无与伦比的多功能性和性能。
Advanced HPC
高性能混凝土是现代科学的一个基本支柱。为了揭示下一代的发现,科学家们利用模拟来更好地理解药物发现的复杂分子、潜在能源的物理学和大气数据,以便更好地预测和准备极端天气模式。NVIDIA Tensor内核提供了包括FP64在内的全方位精度,以加速所需的最高精度的科学计算。
NVIDIA HPC SDK是一套综合的编译器、库和工具,用于为NVIDIA平台开发HPC应用程序。
现代应用的加速
CUDA-X AI和CUDA-X HPC库与NVIDIA Tensor Core gpu无缝协作,加速跨多个域应用程序的开发和部署。
现代人工智能有可能扰乱许多行业,但如何利用它的力量是一个挑战。开发人工智能应用程序需要许多步骤:
数据处理、特征工程、机器学习、验证和部署,每一步都涉及处理大量数据和执行大量计算操作。CUDA-X人工智能提供了克服这一挑战所需的工具和技术。
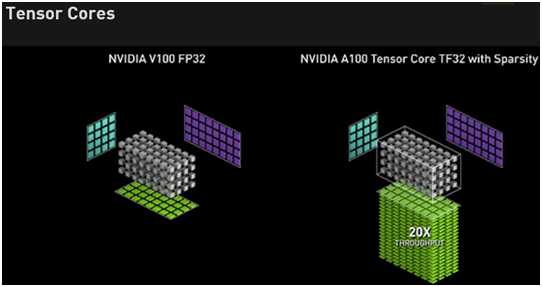
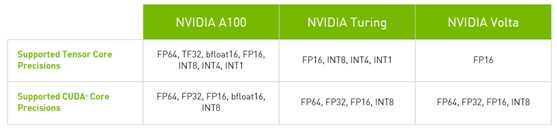
A100 Tensor Cores
第三代
NVIDIA Tensor核心技术为人工智能带来了惊人的加速,将训练时间从几周缩短到几小时,并为推理提供了巨大的加速。NVIDIA安培体系结构提供了巨大的性能提升,并提供了新的精度,以覆盖研究人员所需的全谱-TF32、FP64、FP16、INT8和INT4加速和简化人工智能采用,并将NVIDIATensor Cores的功率扩展到高性能计算机。
Tensor Float 32
随着人工智能网络和数据集继续呈指数级增长,它们的计算需求也同样增长。较低精度的数学运算带来了巨大的性能加速,但它们历来需要一些代码更改。A100带来了一种新的精度,TF32,它的工作原理和FP32一样,同时为人工智能提供高达20倍的加速,而不需要任何代码更改。
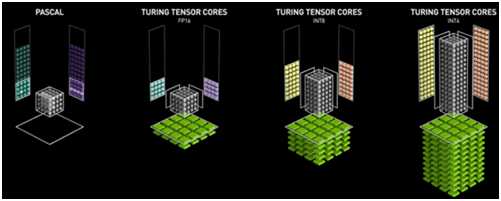
图灵Tensor Cores
第二代
英伟达图灵™ Tensor Cores心技术的特点是多精度计算,有效的人工智能推理。图灵Tensor Cores为深度学习训练和推理提供了一系列精度,从FP32到FP16到INT8,以及INT4,在性能上超过NVIDIA Pascal™ GPU。
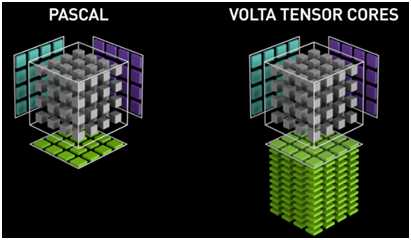
Volta Tensor Cores
第一代
专为深度学习而设计的NVIDIA Volta第一代Tensor Cores™ 在FP16和FP32中使用混合精度矩阵乘法提供开创性的性能,高达12倍的高峰值teraFLOPS(TFLOPS)用于训练,6倍的高峰值TFLOPS用于NVIDIA Pascal上的推理。这一关键能力使Volta能够在Pascal上提供3倍的训练和推理性能加速。
NVIDIA赢得MLPerf推理基准
NVIDIA在新的MLPerf基准上发布了最快的结果,该基准测试了数据中心和边缘的人工智能推理工作负载的性能。新的业绩是在该公司今年早些时候公布的MLPerf基准业绩同样强劲的情况下发布的。
MLPerf的五个推理基准——应用于一系列的形状因子和四个推理场景——涵盖了诸如图像分类、对象检测和翻译等已建立的人工智能应用。
用例和基准是:

NVIDIA在以数据中心为中心的场景(服务器和脱机)的所有五个基准测试中都名列前茅,其中Turing gpu为每个处理器提供了商用项目中最高的性能。Xavier在以边缘为中心的场景(单流和多流)下提供了商用边缘和移动SOC中最高的性能。
NVIDIA的所有MLPerf结果都是使用NVIDIA TensorRT 6高性能深度学习推理软件实现的,该软件可以方便地优化和部署从数据中心到边缘的人工智能应用程序。新的TensorRT优化也可以作为GitHub存储库中的开放源代码使用。请参阅此开发人员博客中的完整结果和基准测试详细信息。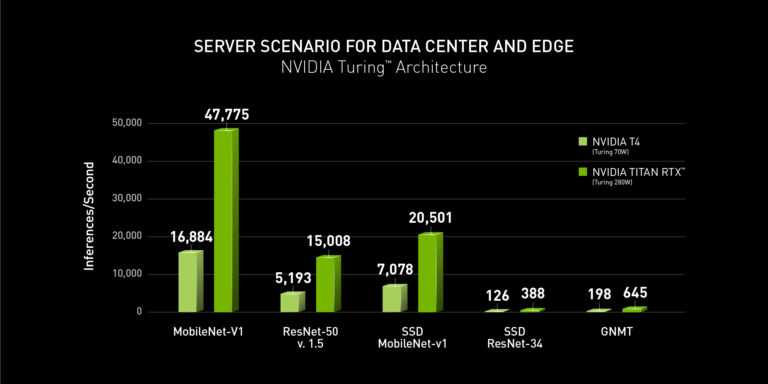
除了是唯一一家提交了MLPerf Inference v0.5所有五个基准测试的公司外,NVIDIA还在开放部门提交了ResNet-50v1.5的INT4实现。这个实现带来了59%的吞吐量增长,准确率损失小于1.1%。在这个博客中,我们将带您简要介绍我们的INT4提交,它来自NVIDIA早期的研究,用于评估图灵上INT4推理的性能和准确度。在此了解有关INT4精度的更多信息。
NVIDIA在扩展其推理平台的同时,今天还推出了Jetson Xavier NX,这是世界上最小、最强大的用于边缘机器人和嵌入式计算设备的AI超级计算机。
Jetson-Xavier NX模块与Jetson-Nano引脚兼容,基于NVIDIA的Xavier SoC的低功耗版本,该版本在边缘SoC中引领了最近的MLPerf推断0.5结果,为在边缘部署高要求的基于AI的工作负载提供了更高的性能,这些工作负载可能受到尺寸、重量、功率和成本等因素的限制。在此处了解有关新系统的更多信息,并了解如何在5个类别中的4个类别中占据榜首。
最强大的端到端人工智能和高性能数据中心平台
Tensor核心是完整NVIDIA数据中心解决方案的基本组成部分,该解决方案集成了NGC的硬件、网络、软件、库以及优化的AI模型和应用程序™. 作为最强大的端到端人工智能和高性能计算机平台,它允许研究人员提供真实的结果,并将解决方案大规模部署到生产中。
以上是关于NVIDIA Tensor Cores解析的主要内容,如果未能解决你的问题,请参考以下文章
如何通过 Vulkan 使用 Nvidia Tensor Cores
用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割