序列模式挖掘综述
Posted yejintianming00
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了序列模式挖掘综述相关的知识,希望对你有一定的参考价值。
基本的序列模式挖掘:主要包括一些经典算法,分为以下三类。
-
1)基于Apriori特性的算法:Apriori([‘e?prɑ?‘?:r?])算法、AprioriSome算法、AprioriAll算法、DynamicSome算法等等
2)基于垂直格子的算法:SPADE算法
3)增量式序列模式挖掘:用来研究当序列增加时,如何维护序列模式,提高数据挖掘效率的问题,典型算法有:ISM算法、ISE算法、IUS算法。
4)多维序列模式挖掘:它是将多维有价值的信息融合到单位序列中,进而挖掘出最优价值的信息。典型算法有三种Uni-Seq、Seq-Dim,Dim-Seq。
5)基于约束的序列模式挖掘:目前的序列模式挖掘算法产生了大量的无用信息或者冗余信息,降低了挖掘的效率,因此提出了约束序列模式挖掘,通过添加约束条件,挖掘用户最感兴趣、最优价值的序列模式。
序列模式挖掘的发展方向:并行序列模式挖掘、周期序列模式挖掘、分布式序列模式挖掘、图序列模式挖掘
-
需要解决的问题:
1)如何进一步提高挖掘海量数据的效率?
2)如何结合相关领域知识来解决实际问题?
3)进一步改进算方法,并将应用大数据挖掘很重。
大数据挖掘研究主要集中采用以下几种方式:
-
基于内存数据分解的方式:随着数据集越来越大,计算机无法一次性地将大数据集读入内存,数据分解结束由此而生,数据分解技术采用分而治之的思想,将大数据集分割成一块块小数据集读入内存,然后进行挖掘,最后合并挖掘结果,大大提高了挖掘效率
-
基于磁盘存储的方式:由于内存空间较小,不能整体地将大数据集进行处理,因此需要将一部分数据存放在磁盘上,这样能够有更多的内存空间来处理后面的数据。
-
基于采样的方式,采样方法是统计学经常采用的技术,我们可以从大规模数据集中抽取出能够反映大数据集的样本,然后对大数据集样本进行挖掘。
序列模式挖掘概念:
-
序列模式挖掘是指从序列数据库中寻找频繁子序列作为模式的知识发现过程,即输入一个序列数据库,输出所有不小于最小支持度的序列的过程。它有广泛的应用领域:预测用户购买行为、预测Web访问模式、预测天气变化、预测时长趋势。
-
序列模式挖掘和关联规则挖掘的区别
序列模式是找出序列数据库中数据之间的先后顺序。比如:用户访问某个网站各个网页的顺序,关联规则是找出事务数据库中数据之间的并发关系。比如:啤酒喝尿布。关联规则挖掘不关注事务之间的先后顺序,序列模式挖掘需要考虑序列间的先后顺序。
序列模式挖掘经典算法
-
AprioriAll算法
-
基本思想:每当扫描数据库时,计算上一次扫描生成的候选序列的support,如果support不小于min_sup,就将其当做大序列
-
算法描述
-
排序阶段,主要是根据交易时间和ID进行排序
-
频繁项目集挖掘阶段,执行一次Apriori算法,找到所有support不小于min_sup的频繁项目集,这个阶段主要是为下一步的转换做铺垫工作
-
转化阶段,根据上一步产生的频繁项集,扫描交易序列数据,根据MAP映射得到新的序列项集
-
序列阶段,根据上一步得到的新序列项集,再次执行Apriori算法,找到新的频繁项集
-
最大化序列阶段,从挖掘的新的频繁序项集中,找出长度最长的序列模式
-
-
算法分析:
-
AprioriAll算法是对Apriori算法的进一步改进,主要区别是在产生候选项集和频繁序列模式方面需要考虑序列元素的顺序。
-
存在的问题:
-
容易生成大量的候选项集
-
需要对数据库进行多次扫描
-
很难找到长序列模式
-
在转换阶段产生巨大的开销
-
-
GSP 算法
GSP算法基于 Apriori 理论,首先产生较短的候选项集,然后将短候选项集进行剪枝,接着通过连接生成长候选序列模式,最后计算其支持度。
-
基本思想:GSP 算法有两个方面的改进:第一,对冗余候选模式进行剪枝。第二,采用哈希树来存储候选模式。
-
算法描述
-
除此扫描序列数据库,得到所有长度为1的序列即为F1,作为种子集,
-
对长度为i的种子集Fi进行连接和剪枝,生成长度为i+1的候选序列
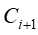 ;再次扫描序列数据库,统计每个候选序列support,然后产生长度为i+1的序列
;再次扫描序列数据库,统计每个候选序列support,然后产生长度为i+1的序列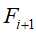 ,并将
,并将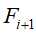 作为新种子集
作为新种子集 -
重复(b),直到找到所有的序列模式为止
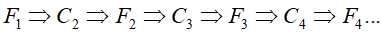
-
-
存在的问题:
-
当序列数据库比较大时,容易生成庞大的候选序列
-
需要对序列数据库进行多次扫描
-
对长序列模式的处理效率比较低
-
-
FreeSpan算法
-
基本思想
该算法基于分而治之的思想,将原始数据集进行划分,同时在分割的过程中动态地进行序列模式挖掘,并将产生的序列模式作为新的划分集。
-
算法描述
-
扫描序列数据库S,找到S中的所有的长度为1的频繁项集,并且按照字母表的顺序生成f_list列表
-
按照f_list列表将序列数据库划分成若干个子集
-
首次扫描序列数据库S,找到所有的频繁项然后与前一项连接组成候选序列 ,计算该候选序列在序列数据库中的支持度,对于support小于min_sup的项进行剪枝
-
递归的挖掘长度更长的序列,直到挖掘出所有长度的频繁序列
-
-
算法分析
从性能上分析,FreeSpan算法要由于类Apriori算法,它不仅能够高效的挖掘到所有长度的频繁序列,而且能够大大减少候选项集的数量
-
存在的问题
在挖掘过程中会产生大量的投影数据库,而且投影数据库一般不会缩减,另外,候选序列很多,需要考虑每一个的候选序列的组合情况
-
-
PrefixSpan算法
-
基本思想
采用分而治之的思想,首先扫描序列数据库,找到所有长度为1的序列模式,把这些序列模式作为前缀,将序列数据库划分为多个小投影数据库,然后在各个投影数据库上进行递归的序列模式挖掘,效果如图所示,首先有一个序列数据库S,根据前缀划分,产生多个投影数据库
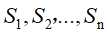 ,然后分别在这多个投影数据库中进行递归的挖掘,直到找到所有的频繁序列模式为止。
,然后分别在这多个投影数据库中进行递归的挖掘,直到找到所有的频繁序列模式为止。 
-
算法描述
-
首次扫描序列数据库,找到长度为1的所有频繁序列;、
-
按照(a)中得到频繁序列划分为n个不同前缀;
-
根据n个不同的前缀,构造相应的投影数据库,并递归的挖掘频繁序列的子集,直到不能产生长度为1的频繁序列模式为止
-
-
PrefixSpan算法存在的问题
尽管PrefixSpan算法能够提升挖掘的效率,但该算法仍存在一些不足,第一:该算法需要构造大量的投影数据库,并且构造投影数据库的开销较大;第二,该算法需要递归的扫描投影数据库,耗费大量的时空代价,同时也大大降低了算法的挖掘效率;第三,该算法挖掘出的频繁序列模式,都是按照字典序进行排列,不能满足实际的需求。
-
-
经典算法的比较分析
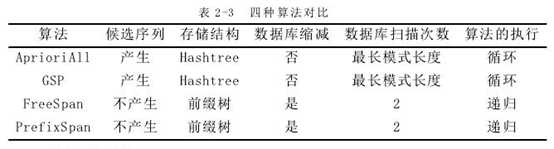
(1)算法基本特性分析
下表列出了四种算法在候选序列、存储结构、数据库缩减、扫描次数、算法执行方面的对比
(2)执行效率分析
Apriori All 算法会产生大量的候选项集,尤其是当挖掘频繁序列长度增加时,产生
的候选项集呈现指数式增长,因此需要消耗大量的存储空间。此外还需要扫描投影数
据库,也需要消耗大量的扫描时间。尽管 GSP算法和Apriori All算法都属于Apriori类,但是GSP算法能够在一定程度上减少候选序列的数量,因此总体效率比Apriori All算法高很多。Free Span算法是基于模式增长的算法,不会产生大量的候选项集,并且每一次仅仅扫描投影数据库,而不是扫描原数据库的候选序列,比类 Apriori 的算法效率要高的多,尤其在支持度较低时更为明显。Free Span 的缺点有两个方面:(1)在挖掘的过程中会产生大量的投影数据库。(2)产生的候选序列很多,需要考虑每一个候选序列的组合情况,因此造成了很大的开销。Prefixspan算法是对Free Span算法的改进,不会产生候选序列模式,另外Prefix Span算法也需要构造大量的投影数据库,造成较大的开销但Prefix Span算法比Free Span算法的收缩速度快,它能够大大缩减搜索空间,缩小投影数据库的规模。
以上是关于序列模式挖掘综述的主要内容,如果未能解决你的问题,请参考以下文章