栈vs堆,最详细的对比
Posted leo-gong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了栈vs堆,最详细的对比相关的知识,希望对你有一定的参考价值。
栈vs堆:不同之处
栈负责追踪那些在我们代码中执行的内容(或者是那些被调用的内容)。而堆则负责追踪我们的对象(我们的数据,当然大多数情况下都是“数据”,稍后我会讨论这个问题)。
注:栈类似于代码执行过程的一个容器,而堆则类似于保存数据的容器。
把栈想象成一个一系列的盒子,一个落着一个在上面。当我们每次调用一个方法(called a Frame)时,我们通过将盒子叠加在最顶部的盒子上来观察在我们的代码中究竟发生了什么。其实,我们只能使用栈中最顶部的盒子。当我们处理完最顶部的盒子(我们执行过的方法、函数)后我们就丢弃它并且继续使用之前在顶部的盒子。堆对于栈很相似,只是堆的目的是保存信息(大多数情况下不追踪执行代码),所以在任何时刻我们的堆都能被访问。有了堆,我们将不像栈一样有那么多访问约束。堆更像是一堆在床上我们还没来得及整理的洗干净的衣服;我们能快速的得到我们想要的衣服。而栈更像是在壁橱里的一摞鞋盒,我们拿掉最顶上的鞋盒为了得到下面的盒子里的鞋。
注:网上找了两个图片替代作者的图片,这样会更生动些。左侧为栈,右侧为堆。

栈可自我维护,这意味着它基本只关系它自己的内存管理。当栈顶的盒子不再使用之后,随即就丢弃掉。堆,在另一方面而言,必须关心垃圾回收问题,这些问题主要是处理如何保持堆整洁(没有人喜欢乱堆脏衣服,臭气熏天~~~)。
注:栈中的内容是每执行一次指令之后即释放掉,所以无需关注资源泄漏;堆则需要GC不定时的回收已不再使用的资源,需维护并关注性能问题。
堆栈上究竟发生了什么
在我们的堆或者栈中我们有四个主要类型:值类型、引用类型、指针类型和指令。
- 值类型:
在C#中,所有的值类型均继承自System.ValueType这个抽象类。
注:System.ValueType继承自System.Object,并且重写了.ToString()等方法,以便阻止某些情况下的装箱问题。
- bool
- byte
- char
- decimal
- double
- enum
- float
- int
- long
- sbyte
- short
- struct
- uint
- ulong
- ushort
2. 引用类型:
在C#中,如下的引用类型均继承自System.Object,当然除了Object其自身。
- class
- interface
- delegate
- object
- string
3. 指针类型:
放置在我们内存管理中的第三个类型是一个引用类型,这就是我们常说的指针。我们不明确的使用指针,他们是被CLR管理的资源。指针(或者引用)是不同于引用类型的,当我们在讨论引用类型的时候,就是说我们是通过指针使用引用类型的。一个指针是指向另一个内存空间的一大块内存。一个指针占据空间就像是一个我们放置在堆或者栈中,并且它的值是一个地址或者为Null。
4. 指令类型:
稍后,在后面的文章中我们会分析。
如何推断类型是在堆上,还是在栈上?
这里,我们有两条黄金定律:
- 引用类型总是在堆上创建,十分简单,是吧?
- 值类型和指针类型总是在它声明的地方创建。这有点复杂并且需要懂一点栈是如何工作的。
栈,正如我们前面讲的,是负责追踪每一个线程中代码执行情况(或者被调用)。你可以认为它是一个线程状态并且每一个线程有它自己的状态。当我们的代码调用执行一个方法,开始执行一个已经被JIT编译过的指令,并且存活在方法表中(live on the method table),它也将参数放置在线程栈中。然后,当我们进入方法体并且带着参数执行方法时,指令将被提到栈顶部。
下面我们用一段代码来演示:

1 public int AddFive(int pValue)
2 {
3 int result;
4 result = pValue + 5;
5 return result;
6 }
这就是发生在栈上的事情。必须记住的是我们正在观察的是已经存在于栈上的:我们执行方法并且方法参数被放置在栈中,稍后我们谈论参数细节。
此图中的AddFive方法并不存在于栈中,这里只是为了演示说明。
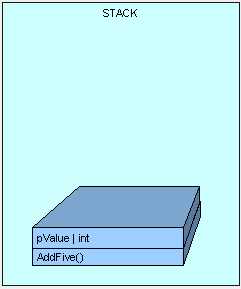
下一步,命令执行到存在于我们的类型表中的AddFive()方法,如果第一次执行该方法,JIT会执行一次。
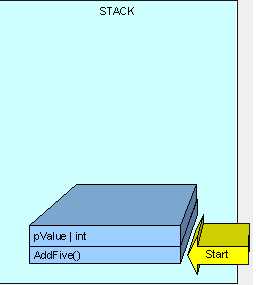
当方法执行时,我们需要一些内存为“result”这个变量,并且这个变量将在栈上创建,如下图:
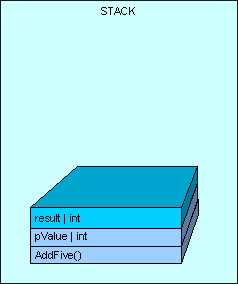
方法执行完毕,返回结果。如下图:
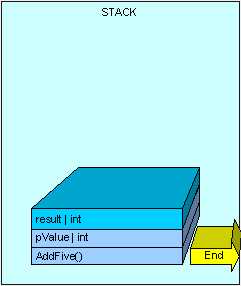
所有在栈上创建的内存将被清理,通过将指针指向一开始AddFive()指向的可用内存地址。
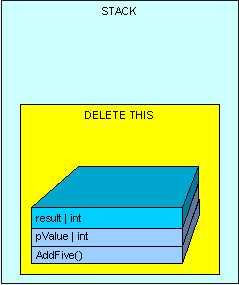
在这个例子中,我们的“result”变量将被放置在栈中。事实上,每次当值类型带着方法体被声明时,它将被放置在栈中。
现在,值类型有时也被放置在堆中。请记住这个规则,值类型是根据其声明的地方而决定其是在堆还是在栈上的。如果一个值类型在方法体外面声明的,但是在引用类型内部,这样它将被包裹在引用类型,并且在堆上创建。
例子如下:
如果我们有如下的MyInt类(类自然是一个引用类型)
public class MyInt
{
public int MyValue;
}
执行如下:
public MyInt AddFive(int pValue)
{
MyInt result = new MyInt();
result.MyValue = pValue + 5;
return result;
}
就像刚才一样,线程开始执在线程栈上的行方法和参数,如下图:
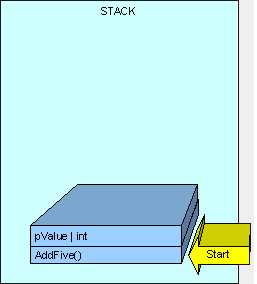
现在就比较有趣了。因为MyInt是一个引用类型,MyInt类型将被放置在堆中,并且被一个放置在栈中的指针所引用(指向),如下图:
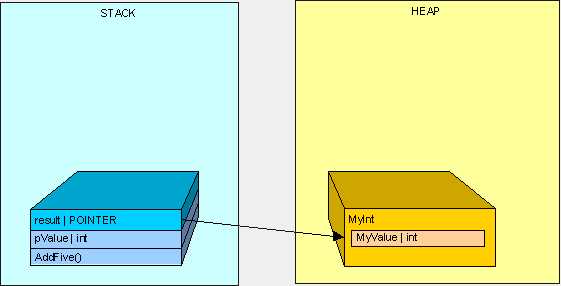
在AddFive()被执行后,我们将清理栈,如下图:
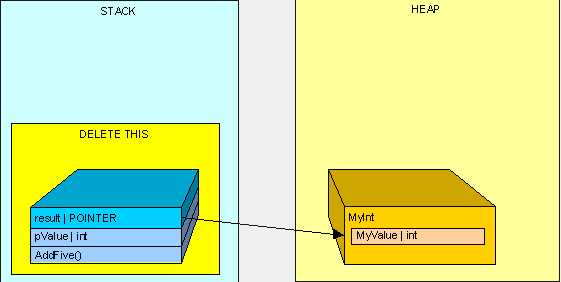
我们只剩下一个孤独的对象在堆中(在栈中将没有任何指针指向堆中的MyInt),如下图:
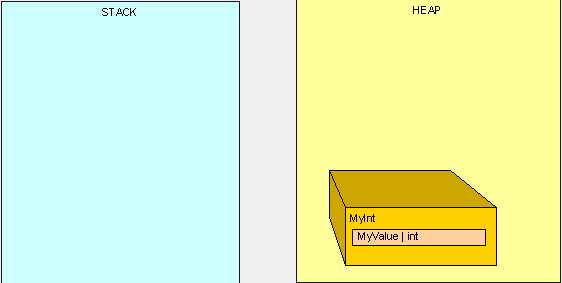
这就是GC展现实力的舞台。当我们达到一定内存瓶颈时我们需要堆中要有更多的空间,这时GC出场。GC将停止所有运行中的线程(完全停止),找出在堆中所有没有被引用的对象并且删除它们。GC将重新组织所有在堆中的对象以获得空间,调整所有在堆以及栈中的指针。就像你想象的那样,这将花费十分昂贵的性能,所以现在你就能看出当你在写高性能代码时,关注堆栈中有什么是如此的重要。
注:1.GC回收一般发生在程序内存不够用时,否则不会发生除非手动调用。2.手动调用GC可实现强制“尝试”回收资源。3.GC中的所有资源是分“代”的,每次检测堆中的对象是否还有引用,如果有当前的“代”数加一,否则减一,GC回收“代”数最小的资源,这也就解释了为什么即使我手动调用GC.Collect()方法之后,对象还是没有马上被回收的问题。4.频繁调用GC.Collect()会导致频繁的线程中断,从而严重影响性能。
好的,十分棒,跟我有什么关系?
问的好。
当我们用引用类型时,我们正在处理指针这个类型,而不是引用(实际的方法、类型)其本身;当我们用值类型时,我们就是用的类型自身。这令人费解,对吗?
再来,下面这个例子很好的诠释了这个问题:
public int ReturnValue()
{ int x = new int(); x = 3; int y = new int(); y = x; y = 4; return x; }
最终的结果是3. 十分简单,不是吗?
public class MyInt
{
public int MyValue;
}
public int ReturnValue2()
{
MyInt x = new MyInt();
x.MyValue = 3;
MyInt y = new MyInt();
y = x;
y.MyValue = 4;
return x.MyValue;
}
返回值是什么?答案是4!
为什么?…x.MyValue是如何变为4的?看一看我们正在做的是什么并且是否这样做有意义:
public int ReturnValue()
{
int x = 3;
int y = x;
y = 4;
return x;
}
注:值类型是传递值,而非传递引用,如下图:
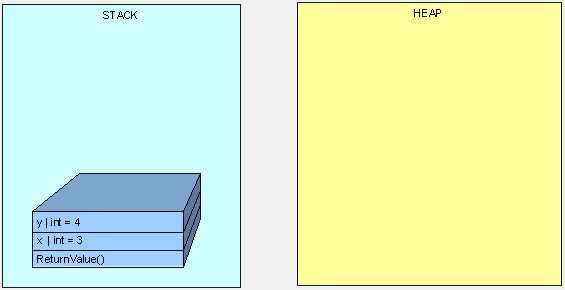
下一个例子,我们没得到“3”,因为x和y都是指向同一个堆对象的变量。
public int ReturnValue2()
{
MyInt x;
x.MyValue = 3;
MyInt y;
y = x;
y.MyValue = 4;
return x.MyValue;
}
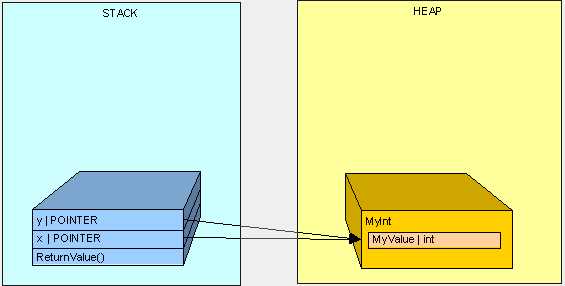
注:实际来讲,引用类型则是指向堆中的同一个对象。
希望这能让您对值类型和引用类型有一个更好的理解通过C#代码并且理解指针的用法和在那里使用。
在下一部分(Part Two),我们将更深入的聊一聊内存管理,尤其要是讨论方法参数。
总结
- 堆与栈的概念及不同点:在内存中栈主要负责处理线程中的命令,并且是以栈Stack的形式读取与执行的;堆主要是存储方法体以及数据,类似于床上散落的衣服,可供随机读取。
- 值类型与引用类型不同点:引用类型永远存在于托管堆上,值类型在哪取决于声明的位置。
- 堆和栈上的垃圾回收:栈有自我维护特性,执行完语句马上释放不会造成资源泄漏。堆则需GC回收,并且符合GC回收的规则,很多堆上的内容在程序退出前都没有被回收,很可能是无意中某处还保留着内容的引用导致,这将严重影响性能。
- 值类型与引用类型在改变内容时处理的方式不同:值类型执行内容拷贝,引用类型始终更改的是所引用的内容,这将导致两者行为上的不一致。
以上是关于栈vs堆,最详细的对比的主要内容,如果未能解决你的问题,请参考以下文章
a堆内存与栈内存异同(Java Heap Memory vs Stack Memory Difference)