机器学习算法总结——朴素贝叶斯
Posted jiangxinyang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法总结——朴素贝叶斯相关的知识,希望对你有一定的参考价值。
1、模型的定义
朴素贝叶斯是基于贝叶斯定理与特征条件独立假设的分裂方法。首先我们来了解下贝叶斯定理和所要建立的模型。对于给定的数据集
![]()
假定输出的类别yi ∈ {c1, c2, ...., ck},朴素贝叶斯通过训练数据集的来学习联合概率分布P(x|y)。但是直接求联合概率分布P(x|y)一般比较难,因此在这里我们近视的求先验概率分布和条件概率分布来替代它。先验概率分布如下
![]()
对于先验概率的求解,可以根据大数定理认为就是该类别在总体样本中的比例。条件概率分布如下
![]()
通过先验概率和条件概率的求解就可以学习到联合概率(一般认为联合概率是正比近似于先验概率和条件概率的乘积),然而在这里的条件概率也是不好求的,若直接求解的话,参数的个数是所有特征取值个数的连乘。因此在这里引入了朴素贝叶斯思想。
朴素贝叶斯法假定上面的条件概率中各特征之前是相互独立的。此时我们可以做链式展开,表达式如下
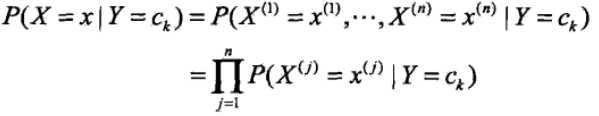
朴素贝叶斯法实际上是有求联合概率分布的过程,以及通过联合概率求后验概率(也是一种条件概率)的过程,像这类的分类器属于生成式模型。区别于它的就是判别生成式模型,常见的有决策树,逻辑回归,SVM等,这类模型都是直接生成结果(可能是P(y) 或者P(y|x) )。了解了先验概率和条件概率的计算过程,我们再来看看贝叶斯定理是如何计算后验概率的
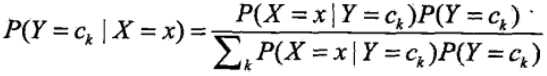
引入朴素的思想,假设各特征之间相互独立
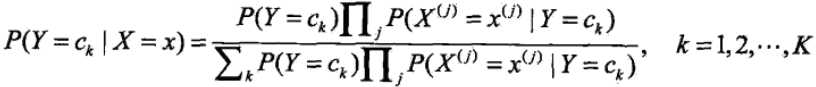
这就是朴素贝叶斯分类的基本公式,因此我们的模型可以建为
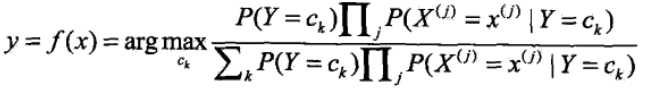
而对于右边式子中的分母,分母是一个和类别无关的式子,也就是说对于所有的ck都是一样的,然后在这里我们只是求的最大概率的类别,因此去掉这一项是不会影响结果的(即对表达式进行同比例的放大或缩小是不会影响最大解的判断的),最终的式子可以写成
![]()
2、后验概率最大化
先来了解下0-1损失函数:
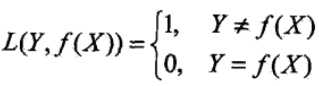
此时的期望风险函数,在优化模型的时候我们的目的是为了使得期望损失最小化
![]()
而对于朴素贝叶斯模型,期望损失函数可以表示为
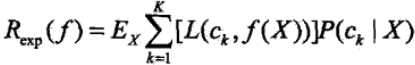
这里面的损失函数和0-1损失有所不同,可以看成分类到每个类别的概率乘以0-1损失函数,也就是说在k中只有一次L函数会取0,其余的都取1,此时我们还要使得取0时的条件概率P(ck|x)是最大的,这样整体的期望损失就是最小的。具体的数学推导过程如下
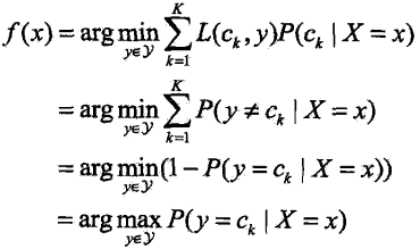
为了使得期望风险最小化就是使得后验概率最大化。
3、朴素贝叶斯的参数估计
采用极大似然估计来求解先验概率和条件概率,先验概率的极大似然估计
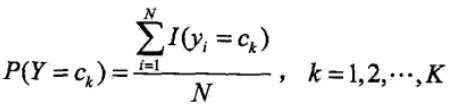
条件概率的极大似然估计
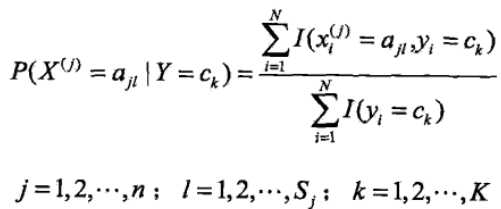
但是用极大似然估计可能会出现概率值为0的情况。这时候会影响到后验概率的计算(因为链式求解时,一旦存在某一个值为0,则会导致整个链式的解为0,也就是求得的条件概率为0).因此我们会采用贝叶斯估计,先验概率的表达式
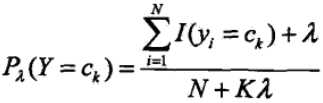
贝叶斯估计的条件概率表达式
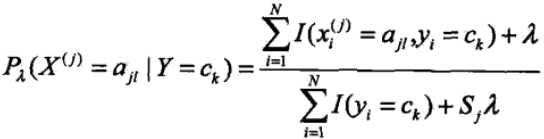
因此朴素贝叶斯模型只要计算出训练集上各类参数,比如先验概率,各特征在各类别上的概率(这些是用来计算条件概率的)等,基于这些学得的值来预测
4、朴素贝叶斯总结
朴素贝叶斯的优点:
1)朴素贝叶斯模型分类效率稳定
2)对小规模的数据集表现很好,能处理多分类问题,适合增量式训练,尤其是数据集超出内存后,我们可以一批批的去训练
3)对缺失数据不太敏感,算法比较简单,常用于文本分类
朴素贝叶斯的缺点;
1)理论上,朴素贝叶斯较其他模型相比具有最小的误差率,但实际上却不一定,因为朴素贝叶斯引进了各特征之间相互独立这一假设。因此在各特征之间相关性较强时,朴素贝叶斯表现一般,但是在各特征之间独立性很强时,朴素贝叶斯表现很好
2)通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率
3)对输入数据的表达形式很敏感
以上是关于机器学习算法总结——朴素贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章