K-means 聚类学习
Posted bc10
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K-means 聚类学习相关的知识,希望对你有一定的参考价值。
没有监督标签,只有x特征值,没有y,没有办法去预测,没有办法证明你做的对错,这样的数据集,我们能做的是什么呢?就是非监督机器学习。常见的算法就是聚类或者降维。聚类做的是什么?就是挖掘数据集中的规律的存在,通过把相似的数据归类,帮助我们探索数据集里的样本如何划分,比如可以将用户分群,不同的营销策略。聚类里包含的算法也是非常多。
聚类的基本思路是:物以类聚,人以群分。通过特征,计算样本之间的相似度。
K-means 聚类学习:
第一步:确定一个超参数k,k就是打算把样本聚集为几类。
第二步:在所有的样本中,随机的选择三个点,作为聚类的初始中心。
第三步:依次计算除这三个中心点以外的每一个点,和三个中心点的距离。然后找出样本点离哪个中心点最近。
第四歩:将所有点划分到离它最近的那个中心点所代表的簇中去。
第五步:所有样本会被划分k个类别,有了k堆数据,分别计算这k个簇的质心。例如:
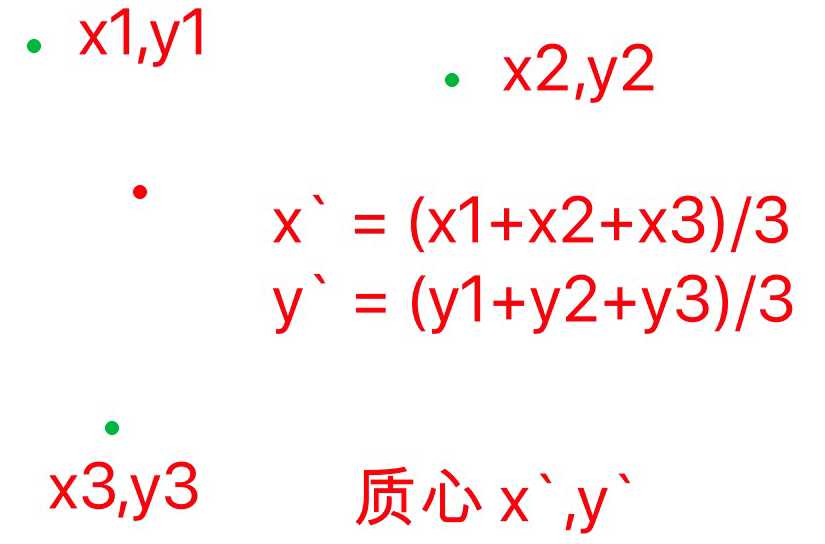
第六步:生成k个新的聚类中心点,以这k个新的重点重新重复3-5歩。
第七歩:终止条件(一):在重复的聚类过程中,所有样本点的分类结果都不再发生变化;(二)或者达到你设定的算法最大迭代次数,例如max_iter = 200 .
原理-算法实现:
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
KMeans(
n_clusters=8, # int, optional 聚类的数量
init=‘k-means++‘, # 一种选择初始质心的方法
n_init=10,# 使用不同质心种子运行k-means算法的次数。 在inertia,最终结果将是n_init连续运行的最佳输出。
max_iter=300, # 最大迭代次数,如果超过此次数将不会继续迭代
tol=0.0001, # MSE 下降到什么数值大小的时候停止迭代
precompute_distances=‘auto‘,
verbose=0,
random_state=None, # 随机数种子
copy_x=True,
n_jobs=None, # 使用cpu核心数量
algorithm=‘auto‘,
)
n_clusters=8, # int, optional 聚类的数量
init=‘k-means++‘, # 一种选择初始质心的方法
n_init=10,# 使用不同质心种子运行k-means算法的次数。 在inertia,最终结果将是n_init连续运行的最佳输出。
max_iter=300, # 最大迭代次数,如果超过此次数将不会继续迭代
tol=0.0001, # MSE 下降到什么数值大小的时候停止迭代
precompute_distances=‘auto‘,
verbose=0,
random_state=None, # 随机数种子
copy_x=True,
n_jobs=None, # 使用cpu核心数量
algorithm=‘auto‘,
)
模型评估
下面来说说Kmeans算法的模型效果评估,模型算法的评估主要是从以下几个方面来进行度量1、样本离最近聚类中心的总和(inertias)
# inertias:其是K均值模型对象的属性,表示样本距离最近的聚类中心的总和,它是作为在没有真实分类标签下的非监督式评估指标,该值越小越好,值越小证明样本在类间的分布越集中,即类内的距离越小。
2、轮廓系数
# 轮廓系数:它用来计算所有样本的平均轮廓系数,使用平均群内距离和每个样本的平均最近簇距离来计算,它是一种非监督式评估指标。其最高值为1,最差值为-1,0附近的值表示重叠的聚类,负值通常表示样本已被分配到错误的集群。
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.silhouette_score.html#sklearn.metrics.silhouette_score
通过轮廓系数找到最好的k值,其实就是调参。常用的方法是:2轮廓系数。
3、CH指标
CH指标通过计算类中各点与类中心的距离平方和来度量类内的紧密度,通过计算各类中心点与数据集中心点距离平方和来度量数据集的分离度,CH指标由分离度与紧密度的比值得到。从而,CH越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果。
以上是关于K-means 聚类学习的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch机器学习—— 目标检测中k-means聚类方法生成锚框anchor