深度学习小知识K-means聚类
Posted 你好啊:)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习小知识K-means聚类相关的知识,希望对你有一定的参考价值。
K-means聚类及相关理论介绍
什么是K-Means聚类方法
将Kmeans聚类分为两部分进行介绍:
- 聚类:所谓聚类就是将数据集中的数据,根据某部分特性进行类别的划分。
- 聚类流程:
- 数据准备,将需要聚类的数据集进行一些预处理,如归一化、正则化、降维等
- 特征选取,定义需要聚类的特征,比如狗的分类中,都有尖尖的耳朵。
- 特征提取,提取到关键的特征
- 聚类,根据类似特征,对数据进行分类
- 效验,对最终聚类的结果进行效验并调整 - Kmeans:kmeans就是经典且有效的聚类算法。
主要思想:计算各个数据的之间的聚类,并将这几个类别分为K个类别。
具体:准备一个数据集和人为设定的聚类数目K值(在YOLO系列中Anchor聚类的数目为9,这是精确度和速度的均衡);选取K个对象作为开始的聚类中心,然后计算每个对象与聚类中心之间的聚类,将对象分配到对应的聚类中心;分配完成之后,在重复计算以满足设定的某个条件。
Kmeans聚类算法流程
-
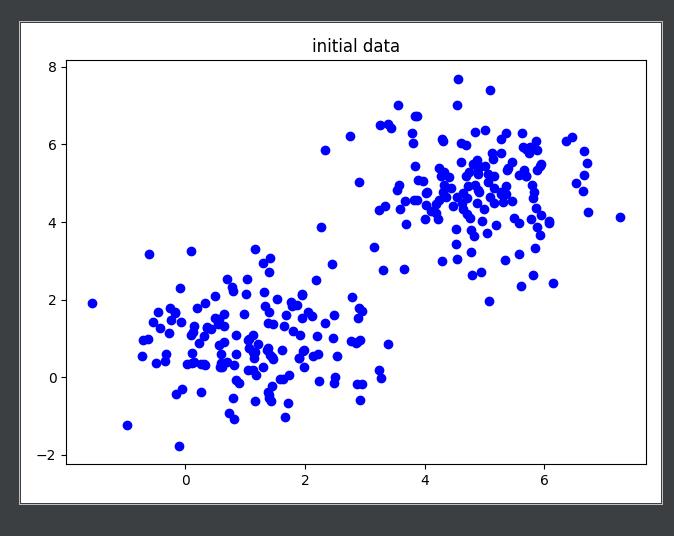
1 随机初始化数据
-
-
2 生成两个聚类中心(第一次是随机生成的),将每个类别计算距离距离中心的距离,进行分类。

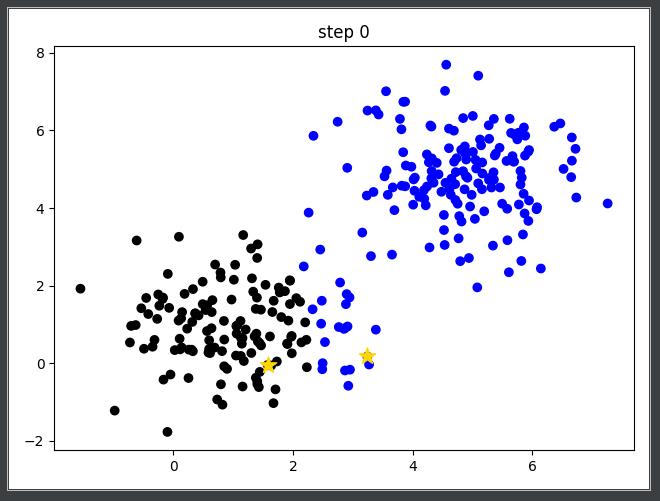
-
3 计算每个聚类中心的平均值(如:X坐标/Y坐标的均值作为新的聚类中心),生成新的聚类中心,再对按照聚类中心的距离重新分类。
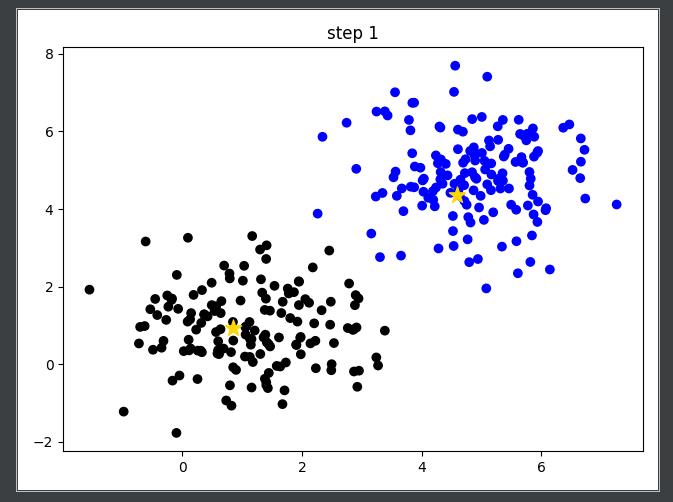
-
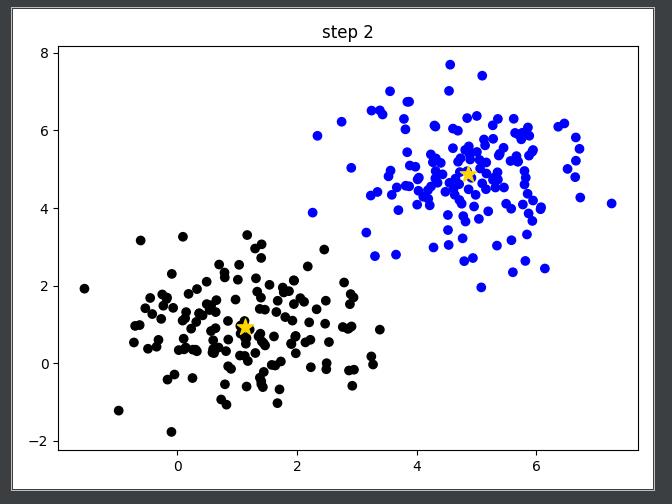
不断重复,最终没什么变化或者满足阈值调节终止,即算到最优情况
-
!!!end!!!
以上是关于深度学习小知识K-means聚类的主要内容,如果未能解决你的问题,请参考以下文章