eduSrc域名收集脚本
Posted Xinux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了eduSrc域名收集脚本相关的知识,希望对你有一定的参考价值。
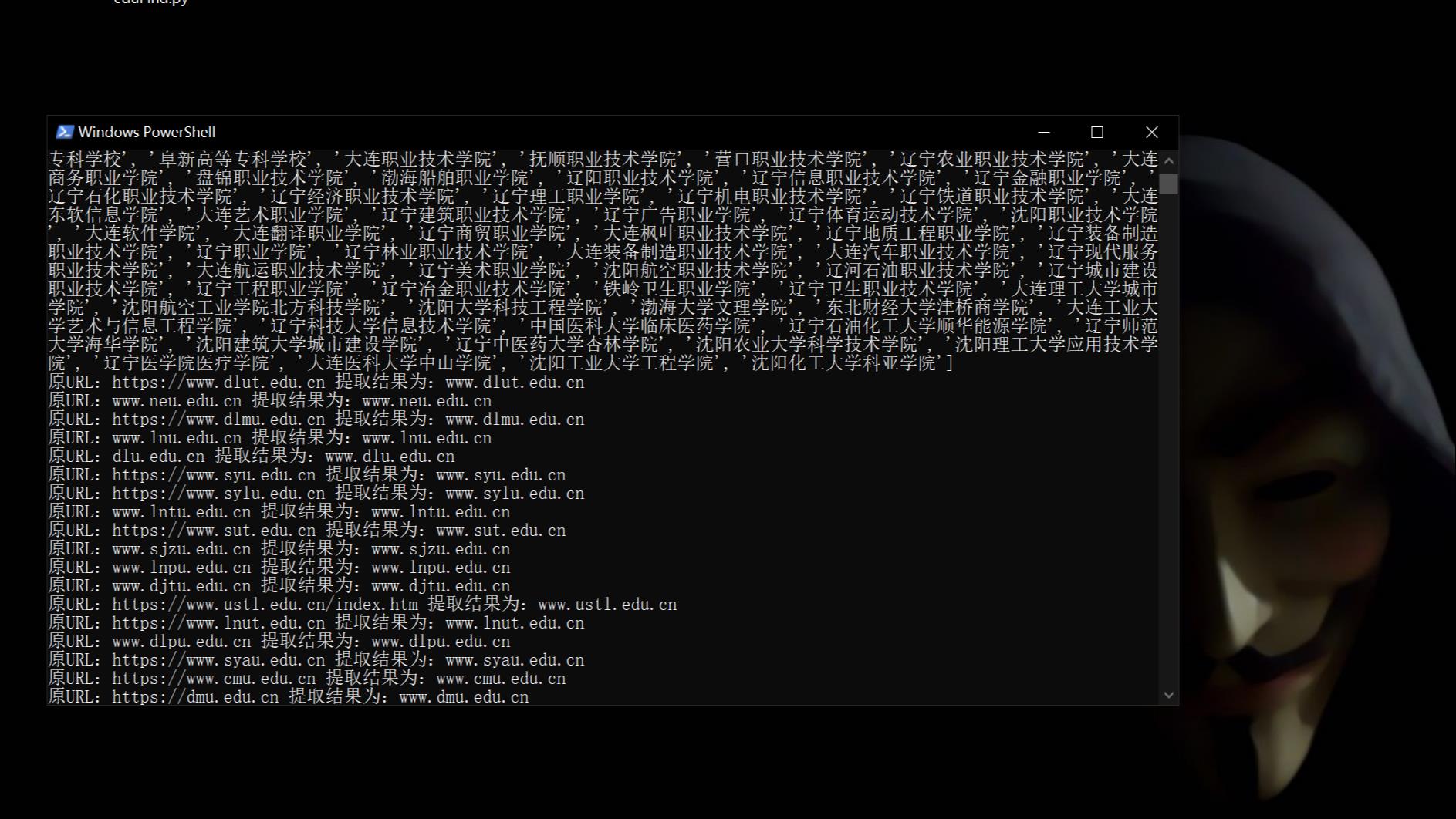 eduSrc主域名收集脚本,现成可用,不存在cookie过期问题。
eduSrc主域名收集脚本,现成可用,不存在cookie过期问题。
eduSrc主域名查找脚本
二改版本,原作者项目地址:
https://github.com/Ernket/edu-crawler
原作者的可能下载下来不能直接用,这个则可以。刚改完,热乎的哈哈哈
效果,可以直接拿来用
用法:
直接输入省即可,用拼音的方式输入,如辽宁 liaoning
下载: https://wwux.lanzouw.com/iA1Kn0myt3od
密码:31ge
原理
首先是高校名称的获取
根据 http://u.feelingmsg.com 进行高校名称的获取

获得高校名再去bing进行搜索,将第一个结果的url提炼出来
def schoolsite(n):
global bing
for i in n:
bingurl=bing+i
req = requests.get(bingurl,headers=headers)
tree=etree.HTML(req.text)
res=tree.xpath(\'//div[@class="b_caption"]/div/cite/text()\')
def eduName(url):
req = requests.get(url,headers=headers)
req.encoding="gb2312"
tree = etree.HTML(req.text)
res=tree.xpath("//tr/td/span[@class=\'STYLE54\']/a/text()")
print(res)
schoolsite(res)
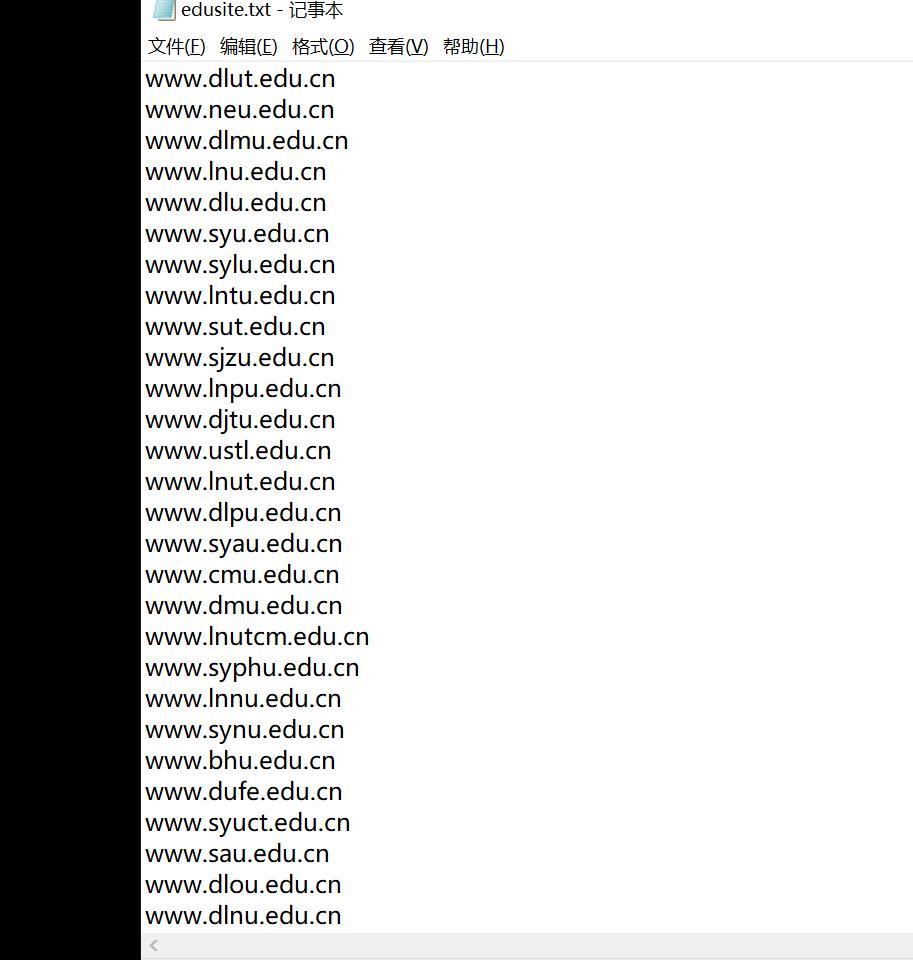
最后就是结果输出到txt文件中
以上是关于eduSrc域名收集脚本的主要内容,如果未能解决你的问题,请参考以下文章