信息搜集方法小结(持续更新)
Posted 思源湖的鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了信息搜集方法小结(持续更新)相关的知识,希望对你有一定的参考价值。
目录
前言
记录下信息搜集常用的方法
1、域名信息收集
- Whois站长之家:http://whois.chinaz.com/
- 微步在线:https://x.threatbook.cn/
- 阿里云中国万网:https://whois.aliyun.com/
- Whois Lookup查找目标网站所有者信息:http://whois.domaintools.com/
- Netcraft Site Report显示目标网站使用的技术:
http://toolbar.netcraft.com/site_report?url= - Robtex DNS查询显示关于目标网站的全面的DNS信息:https://www.robtex.com/
- 全球Whois查询:https://www.whois365.com/cn/
- 站长工具爱站查询:https://whois.aizhan.com/
- 爱站网ping检测\\IP反查域:https://dns.aizhan.com/
- DNS服务器解析:http://tool.chinaz.com/nslookup
- 多地ping 检查dns是否存在:http://ping.chinaz.com/ping.chinaz.com
- 同ip查旁站:http://s.tool.chinaz.com/same
2、ICP备案查询
- https://www.beian88.com/
- http://beian.miit.gov.cn/publish/query/indexFirst.action
- https://www.tianyancha.com/
- http://www.beianbeian.com/
3、子域名收集
(1)子域名爆破
- layer
- K8
- subDomainsBrute
- dnsmaper
- Sublist3r
- googlehack
- MaltegoCE
- photon
- Lscan
- dnsbrute
- wydomain
(2)在线子域名
- http://i.links.cn/subdomain/
- https://phpinfo.me/domain/
- pentest-tools.com
- http://www.yunsee.cn/
- https://findsubdomains.com/
- https://dnsdumpster.com/
- https://d.chinacycc.com/
- http://z.zcjun.com/
(3)一个脚本
import requests
import threading
from bs4 import BeautifulSoup
import re
import time
url = input( 'url(如baidu.com): ' )
head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'}
ip = 'http://site.ip138.com/{}'.format( url )
# domain_url = url.split('.')
# domain_url = domain_url[1]+'.'+domain_url[2]
domain_url = url
domain = 'http://site.ip138.com/{}/domain.htm'.format( domain_url )
t = time.strftime("%Y-%m-%d"+'_', time.localtime())
html_file = open( url+'_'+t+'.html','w' )
html_file.write( '''
<head>
<title>%s的扫描结果</title>
<link rel="stylesheet" href="https://cdn.staticfile.org/twitter-bootstrap/3.3.7/css/bootstrap.min.css">
<script src="https://cdn.staticfile.org/jquery/2.1.1/jquery.min.js"></script>
<script src="https://cdn.staticfile.org/twitter-bootstrap/3.3.7/js/bootstrap.min.js"></script>
<style>
pre{
margin: 0 0 0px;
}
</style>
</head>
<ul id="myTab" class="nav nav-tabs navbar-fixed-top navbar navbar-default">
<li class="active">
<a href="#ip" data-toggle="tab">
IP历史解析
</a>
</li>
<li><a href="#cms" data-toggle="tab">CMS识别</a></li>
<li><a href="#domain" data-toggle="tab">子域名信息</a></li>
</ul>
<br>
<br>
<br>
<br>
<div id="myTabContent" class="tab-content">
'''%url )
class IP( threading.Thread ):
def __init__(self, ip):
threading.Thread.__init__(self)
self.ip = ip
def run(self):
r = requests.get( self.ip,headers = head )
html = r.text
bs = BeautifulSoup(html, "html.parser")
html_file.write('<div class="tab-pane fade in active" id="ip">')
for i in bs.find_all('p'):
ipc = i.get_text()
ip_html = '<pre>{}</pre>'.format( ipc )
html_file.write( ip_html )
html_file.write('</div>')
class CMS( threading.Thread ):
def __init__(self, cms):
threading.Thread.__init__(self)
self.cms = cms
def run(self):
cms = requests.post('http://whatweb.bugscaner.com/what/', data={'url': self.cms}, headers = head)
text = cms.text
Web_Frameworks = re.search('"Web Frameworks": "(.*?)"]', text)
Programming_Languages = re.search('"Programming Languages":(.*?)"]', text)
javascript_Frameworks = re.search('"JavaScript Frameworks": (.*?)"]', text)
CMS = re.search('"CMS": (.*?)"]', text)
Web_Server = re.search('"Web Servers": (.*?)"]', text)
if CMS:
CMS = CMS.group(1)+'"]'
if Programming_Languages:
Programming_Languages = Programming_Languages.group(1)+'"]'
if JavaScript_Frameworks:
JavaScript_Frameworks = JavaScript_Frameworks.group(1)+'"]'
if Web_Frameworks:
Web_Frameworks = Web_Frameworks.group(1)+'"]'
if Web_Server:
Web_Server = Web_Server.group(1)+'"]'
html = '''
<div class="tab-pane fade" id="cms">
<div class="table-responsive">
<table class="table table-condensed">
<tr>
<th>web框架</th>
<th>脚本版本</th>
<th>JavaScript框架</th>
<th>CMS框架</th>
<th>web服务器</th>
</tr>
<tr>
<td>{0}</td>
<td>{1}</td>
<td>{2}</td>
<td>{3}</td>
<td>{4}</td>
</tr>
</table>
</div>
</div>
'''.format(Web_Frameworks,Programming_Languages,JavaScript_Frameworks,CMS,Web_Server)
html_file.write( html )
class DOMAIN( threading.Thread ):
def __init__(self, domain):
threading.Thread.__init__(self)
self.domain = domain
def run(self):
r = requests.get( self.domain,headers = head )
html = r.text
bs = BeautifulSoup(html, "html.parser")
html_file.write('<div class="tab-pane fade in active" id="domain"')
num = 0
for i in bs.find_all('p'):
num += 1
html_file.write( '<br>' )
domainc = i.get_text()
domain_html = '<pre>[{}]: {}</pre>'.format( num,domainc )
html_file.write( domain_html )
print( domain_html )
html_file.write('</div>')
ip_cls = IP(ip)
ip_html = ip_cls.run()
cms_cls = CMS(url)
cms_html = cms_cls.run()
domain_cls = DOMAIN( domain )
domain_html = domain_cls.run()
4、CMS网站指纹识别
- BugScaner:http://whatweb.bugscaner.com/look/
- 云悉指纹:http://www.yunsee.cn/finger.html
- WhatWeb:https://whatweb.net/
5、CMS漏洞查询
6、敏感目录信息收集
- 御剑扫描器:C段和旁站目录
- wwwscan命令行工具
- DirBuster
- 7kbscan-WebPathBrute
- spinder.py(轻量快速单文件目录后台扫描)
- sensitivefilescan(轻量快速单文件目录后台扫描)
- weakfilescan(轻量快速单文件目录后台扫描)
- 源码泄露
7、端口扫描
- Nmap
# 扫描端口并且标记可以爆破的服务
nmap 目标 --script=ftp-brute,imap-brute,smtp-brute,pop3-brute,mongodb-brute,redis-brute,ms-sql-brute,rlogin-brute,rsync-brute,mysql-brute,pgsql-brute,oracle-sid-brute,oracle-brute,rtsp-url-brute,snmp-brute,svn-brute,telnet-brute,vnc-brute,xmpp-brute
# 判断常见的漏洞并扫描端口
nmap 目标 --script=auth,vuln
# 精确判断漏洞并扫描端口
nmap 目标 --script=dns-zone-transfer,ftp-anon,ftp-proftpd-backdoor,ftp-vsftpd-backdoor,ftp-vuln-cve2010-4221,http-backup-finder,http-cisco-anyconnect,http-iis-short-name-brute,http-put,http-php-version,http-shellshock,http-robots.txt,http-svn-enum,http-webdav-scan,iis-buffer-overflow,iax2-version,memcached-info,mongodb-info,msrpc-enum,ms-sql-info,mysql-info,nrpe-enum,pptp-version,redis-info,rpcinfo,samba-vuln-cve-2012-1182,smb-vuln-ms08-067,smb-vuln-ms17-010,snmp-info,sshv1,xmpp-info,tftp-enum,teamspeak2-version
- Scanport
- webrobot
一些重要端口:
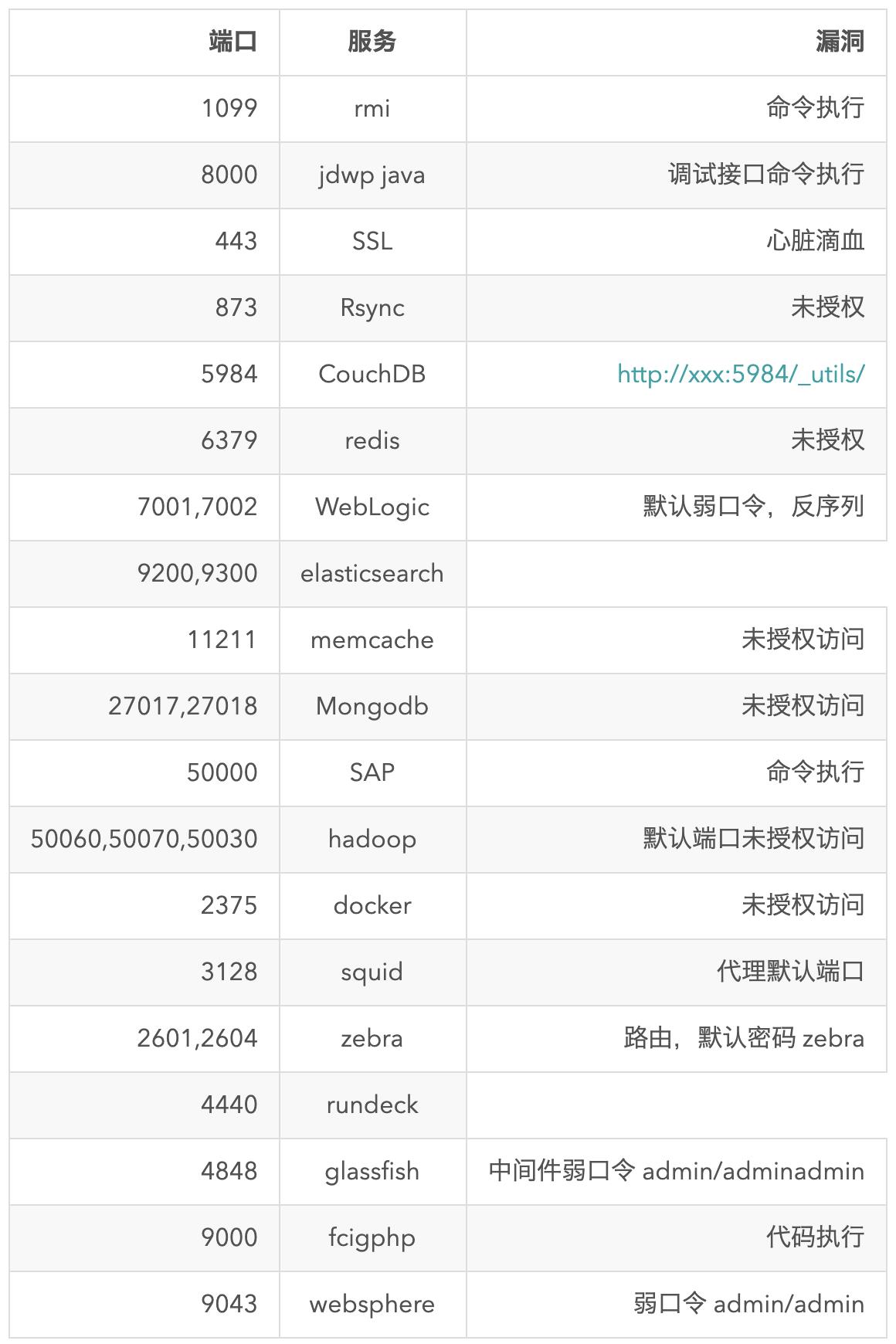
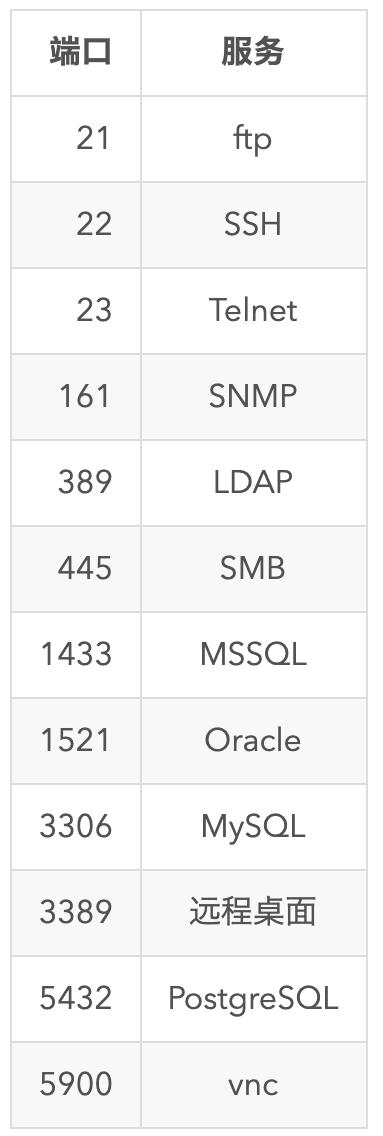
8、Email收集
- teemo
- metago
- burpusit
- awvs
- netspker
- google 语法收集
9、爬虫收集
- spiderfoot (可爬虫出RUL 链接以及JS 以及DOC 以及邮箱和子域名等信息)
- Sn1per (自动化信息收集框架)
- avws, netpsker, burpsuit 可进行爬虫扫描
- Recon-ng 自动化信息收集框架
- instarecon 自动化信息爬虫收集
10、搜索引擎
- https://x.threatbook.cn/
- https://www.zoomeye.org/
- https://www.shodan.io/
- https://haosec.cn/
- 一个集合: https://github.com/atdpa4sw0rd/Search-Tools
前面提到过的google hack
一个工具:https://github.com/su18/Elena
intitle:搜索网页标题中包含有特定字符的网页。
inurl:搜索包含有特定字符的URL。例如输入“inurl:/admin_login”,则可以找到带有admin_login字符的URL,通常这类网址是管理员后台的登录网址。
intext:搜索网页正文内容中的指定字符。
Filetype:搜索指定类型的文件。例如输入“filetype:PDF”,将返回PDF文档。
Site:找到与指定网站有联系的URL。例如输入“Site:www.sunghost.cn”。所有和这个网站有联系的URL都会被显示。
黑客常用的语法
admin site:edu.cn
site:sunghsot.cn intext:管理|后台|登录|用户名|密码|验证码|系统|账号|后台管理|后台登录
site:sunghsot.cn intitle:管理|后台|登录|用户名|密码|验证码|系统|账号|后台管理|后台登录
inurl:login/admin/manage/admin_login/login_admin/system/boos/master/main/cms/wp-admin/sys|managetem|password|username
site:www.sunghost.cn inurl:file
site:www.sunghost.cn inurl:load
site:www.sunghost.cn inurl:php?id=
site:www.sunghost.cn inurl:asp?id=
site:www.sunghost.cn inurl:fck
site:www.sunghost.cn inurl:ewebeditor
inurl:ewebeditor|editor|uploadfile|eweb|edit
intext:to parent directory
intext:转到父目录/转到父路径
inurl:upload.asp
inurl:cms/data/templates/images/index/
intitle:powered by dedecms
index of/ppt
Filetype:mdb
site:www.sunghost.cn intext:to parent directory+intext.mdb
inurl:robots.txt
intitle:index.of "parent directory"
index of /passwd
site:sunghost.cn filetype:mdb|ini|php|asp|jsp
其他相关指令:related,cache,info,define,link,allinanchor等。
intitle
intitle语法通常被用来搜索网站的后台、特殊页面和文件,通过在Google中搜索“intitle:登录”、“intitle:管理”就可以找到 很多网站的后台登录页面。此外,intitle语法还可以被用在搜索文件上,例如搜索“intitle:"indexof"etc/shadow”就可以 找到Linux中因为配置不合理而泄露出来的用户密码文件。
inurl
Google Hack中,inurl发挥的作用的最大,主要可以分为以下两个方面:寻找网站后台登录地址,搜索特殊URL。
寻找网站后台登录地址:和intitle不同的是,inurl可以指定URL中的关键字,我们都知道网站的后台URL都是类似login.asp、 admin.asp为结尾的,那么我们只要以“inurl:login.asp”、“inurl:admin.asp”为关键字进行搜索,同样可以找到很 多网站的后台。此外,我们还可以搜索一下网站的数据库地址,以“inurl:data”、“inurl:db”为关键字进行搜索即可。
寻找网站的后台登录页面
搜索特殊URL:通过inurl语法搜索特殊URL,我们可以找到很多网站程序的漏洞,例如最早IIS中的Uncode目录遍历漏洞,我们可以构造 “inurl:/winnt/system32/cmd exe?/c+dir”这样的关键字进行搜索,不过目前要搜索到存在这种古董漏洞的网站是比较困难的。再比如前段日子很火的上传漏洞,我们使用 ““inurl:upload.asp”或“inurl:upload_soft.asp”即可找到很多上传页面,此时再用工具进行木马上传就可以完成入 侵。
intext
intext的作用是搜索网页中的指定字符,这貌似在Google Hack中没有什么作用,不过在以“intext:to parent directory”为关键字进行搜索后,我们会很惊奇的发现,无数网站的目录暴露在我们眼前。我们可以在其中随意切换目录,浏览文件,就像拥有了一个简 单的Webshell。形成这种现象的原因是由于IIS的配置疏忽。同样,中文IIS配置疏忽也可能出现类似的漏洞,我们用“intext:转到父目录” 就可以找到很多有漏洞的中文网站。
随意浏览网站中的文件
Filetype
Filetype的作用是搜索指定文件。假如我们要搜索网站的数据库文件,那么可以以“filetype:mdb”为关键字进行搜索,很快就可以下载到不少网站的数据库文件。当然,Filetype语法的作用不仅于此,在和其他语法配合使用的时候更能显示出其强大作用。
Site
黑客使用Site,通常都是做入侵前的信息刺探。Site语法可以显示所有和目标网站有联系的页面,从中或多或少存在一些关于目标网站的资料,这对于黑客 而言就是入侵的突破口,是关于目标网站的一份详尽的报告。语法组合,威力加倍虽然上文中介绍的这几个语法能各自完成入侵中的一些步骤,但是只使用一个语法 进行入侵,其效率是很低下的。Google Hack的威力在于能将多个语法组合起来,这样就可以快速地找到我们需要的东西。下面我们来模拟黑客是如何使用Google语法组合来入侵一个网站的。
信息刺探
黑客想入侵一个网站,通常第一步都是对目标网站进行信息刺探。这时可以使用“Site:目标网站”来获取相关网页,从中提取有用的资料。
11、服务器信息/脚本类型
- whatweb
- p0f
- httprint
- httprecon
- avws 也可以得到服务器信息
12、真实IP地址
一些方法:
- 看邮箱头源 ip (可靠)
- 查询域名历史 ip : http://toolbar.netcraft.com
- zmap 全网爆破查询真实 ip (可靠)
- 子域名 (不可靠)
- 网站测试文件如 phpinfo,test 等配置文件
- 备份文件
- 二级域名不一定使用 CDN,二级域名不一定和主站同一个 IP 有可能是同 C 段,可以扫描整个 C 段 WEB 端口
- CDN配置解析不完全,
ping backlion.org和ping www.baklion.org的 IP 不同 - rss订阅
一些网站:
一个脚本:
#############################################################
###
### ▄▄▄▄ ▄▄▄ ▄▄▄▄ ▀ ▄
### ▀ ▀█ ▄ ▄ ▄▄▄▄ █ ▄▀ ▀▄ ▄▄▄ ▄▄█▄▄
### ▄▄▄▀ █▄█ █▀ ▀█ █ █ ▄ █ █ █
### ▀█ ▄█▄ █ █ █ █ █ █ █
### ▀▄▄▄█▀ ▄▀ ▀▄ ██▄█▀ ▄▄█▄▄ █▄▄█ ▄▄█▄▄ ▀▄▄
### █
### ▀
###
### name: xcdn.py
### function: try to get the actual ip behind cdn
### date: 2016-11-05
### author: quanyechavshuo
### blog: http://3xp10it.cc
#############################################################
# usage:python3 xcdn.py www.baidu.com
import time
import os
os.system("pip3 install exp10it -U --no-cache-dir")
from exp10it import figlet2file
figlet2file("3xp10it",0,True)
time.sleep(1)
from exp10it import CLIOutput
from exp10it import get_root_domain
from exp10it import get_string_from_command
from exp10it import get_http_or_https
from exp10it import post_request
from exp10it import get_request
from exp10it import checkvpn
import sys
import re
class Xcdn(object):
def __init__(self,domain):
#必须保证连上了vpn,要在可以ping通google的条件下使用本工具,否则有些domain由于被GFW拦截无法正常访问会导致
#本工具判断错误,checkvpn在可以ping通google的条件下返回1
while 1:
if checkvpn()==1:
break
else:
time.sleep(1)
print("vpn is off,connect vpn first")
if domain[:4]=="http":
print("domain format error,make sure domain has no http,like www.baidu.com but not \\
http://www.baidu.com")
sys.exit(0)
#首先保证hosts文件中没有与domain相关的项,有则删除相关
domainPattern=domain.replace(".","\\.")
#下面的sed的正则中不能有\\n,sed匹配\\n比较特殊
#http://stackoverflow.com/questions/1251999/how-can-i-replace-a-newline-n-using-sed
command="sed -ri 's/.*\\s+%s//' /etc/hosts" % domainPattern
os.system(command)
self.domain=domain
self.http_or_https=get_http_or_https(self.domain)
print('domain的http或https是:%s' % self.http_or_https)
result=get_request(self.http_or_https+"://"+self.domain,'seleniumPhantomJS')
self.domain_title=result['title']
#下面调用相当于main函数的get_actual_ip_from_domain函数
actual_ip = self.get_actual_ip_from_domain()
if actual_ip != 0:
print("恭喜,%s的真实ip是%s" % (self.domain, actual_ip))
#下面用来存放关键返回值
self.return_value=actual_ip
def domain_has_cdn(self):
# 检测domain是否有cdn
# 有cdn时,返回一个字典,如果cdn是cloudflare,返回{'has_cdn':1,'is_cloud_flare':1}
# 否则返回{'has_cdn':1,'is_cloud_flare':0}或{'has_cdn':0,'is_cloud_flare':0}
import re
CLIOutput().good_print("现在检测domain:%s是否有cdn" % self.domain)
has_cdn = 0
# ns记录和mx记录一样,都要查顶级域名,eg.dig +short www.baidu.com ns VS dig +short baidu.com ns
result = get_string_from_command("dig ns %s +short" % get_root_domain(self.domain))
pattern = re.compile(
r"(cloudflare)|(cdn)|(cloud)|(fast)|(incapsula)|(photon)|(cachefly)|(wppronto)|(softlayer)|(incapsula)|(jsdelivr)|(akamai)", re.I)
cloudflare_pattern = re.compile(r"cloudflare", re.I)
if re.search(pattern, result):
if re.search(cloudflare_pattern, result):
print("has_cdn=1 from ns,and cdn is cloudflare")
return {'has_cdn': 1, 'is_cloud_flare': 1}
else:
print("has_cdn=1 from ns")
return {'has_cdn': 1, 'is_cloud_flare': 0}
else:
# 下面通过a记录个数来判断,如果a记录个数>1个,认为有cdn
result = get_string_from_command("dig a %s +short" % self.domain)
find_a_record_pattern = re.findall(r"((\\d{1,3}\\.){3}\\d{1,3})", result)
if find_a_record_pattern:
ip_count = 0
for each in find_a_record_pattern:
ip_count += 1
if ip_count > 1:
has_cdn = 1
return {'has_cdn': 1, 'is_cloud_flare': 0}
return {'has_cdn': 0, 'is_cloud_flare': 0}
def get_domain_actual_ip_from_phpinfo(self):
# 从phpinfo页面尝试获得真实ip
CLIOutput().good_print("现在尝试从domain:%s可能存在的phpinfo页面获取真实ip" % self.domain)
phpinfo_page_list = ["info.php", "phpinfo.php", "test.php", "l.php"]
for each in phpinfo_page_list:
url = self.http_or_https + "://" + self.domain + "/" + each
CLIOutput().good_print("现在访问%s" % url)
visit = get_request(url,'seleniumPhantomJS')
code = visit['code']
content = visit['content']
pattern = re.compile(r"remote_addr", re.I)
if code == 200 and re.search(pattern, content):
print(each)
actual_ip = re.search(r"REMOTE_ADDR[^\\.\\d]+([\\d\\.]{7,15})[^\\.\\d]+", content).group(1)
return actual_ip
# return 0代表没有通过phpinfo页面得到真实ip
return 0
def flush_dns(self):
# 这个函数用来刷新本地dns cache
# 要刷新dns cache才能让修改hosts文件有效
CLIOutput().good_print("现在刷新系统的dns cache")
command = "service network-manager restart && /etc/init.d/networking force-reload"
os.system(command)
import time
time.sleep(3)
def modify_hosts_file_with_ip_and_domain(self,ip):
# 这个函数用来修改hosts文件
CLIOutput().good_print("现在修改hosts文件")
exists_domain_line = False
with open("/etc/hosts", "r+") as f:
file_content = f.read()
if re.search(r"%s" % self.domain.replace(".", "\\."), file_content):
exists_domain_line = True
if exists_domain_line == True:
os.system("sed -ri 's/.*%s.*/%s %s/' %s" % (self.domain.replace(".", "\\."), ip, self.domain, "/etc/hosts"))
else:
os.system("echo %s %s >> /etc/hosts" % (ip, self.domain))
def check_if_ip_is_actual_ip_of_domain(self,ip以上是关于信息搜集方法小结(持续更新)的主要内容,如果未能解决你的问题,请参考以下文章