时间轮原理及其在框架中的应用
Posted vivo 互联网技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了时间轮原理及其在框架中的应用相关的知识,希望对你有一定的参考价值。
一、时间轮简介
1.1 为什么要使用时间轮
在平时开发中,经常会与定时任务打交道。下面举几个定时任务处理的例子。
1)心跳检测。在Dubbo中,需要有心跳机制来维持Consumer与Provider的长连接,默认的心跳间隔是60s。当Provider在3次心跳时间内没有收到心跳响应,会关闭连接通道。当Consumer在3次心跳时间内没有收到心跳响应,会进行重连。Provider侧和Consumer侧的心跳检测机制都是通过定时任务实现的,而且是本篇文章要分析的时间轮HashedWheelTimer处理的。
2)超时处理。在Dubbo中发起RPC调用时,通常会配置超时时间,当消费者调用服务提供者出现超时进行一定的逻辑处理。那么怎么检测任务调用超时了呢?我们可以利用定时任务,每次创建一个Future,记录这个Future的创建时间与超时时间,后台有一个定时任务进行检测,当Future到达超时时间并且没有被处理时,就需要对这个Future执行超时逻辑处理。
3)Redisson分布式锁续期。在分布式锁处理中,通常会指定分布式锁的超时时间,同样会在finally块里释放分布式锁。但是有一个问题时,通常分布式锁的超时时间不好判断,如果设置短了业务却没执行完成就把锁释放掉了,或者超时时间设置很长,同样也会存在一些问题。Redisson提供了一种看门狗机制,通过时间轮定时给分布式锁续期,也就是延长分布式锁的超时时间。
可以看到,上述几个例子都与定时任务有关,那么传统的定时任务有什么缺点呢?为什么要使用时间轮来实现?
假如使用普通的定时任务处理机制来处理例2)中的超时情况:
1)简单地,可以针对每一次请求创建一个线程,然后Sleep到超时时间,之后若判断超时则进行超时逻辑处理。存在的问题是如果面临是高并发请求,针对每个请求都要去创建线程,这样太耗费资源了。
2)针对方案1的不足,可以改成一个线程来处理所有的定时任务,比如这个线程可以每隔50ms扫描所有需要处理的超时任务,如果发现有超时任务,则进行处理。但是,这样也存在一个问题,可能一段时间内都没有任务达到超时时间,那么就让CPU多了很多无用的轮询遍历操作。
针对上述方案的不足,可以采用时间轮来进行处理。下面先来简单介绍下时间轮的概念。
1.2 单层时间轮
我们先以单层时间轮为例,假设时间轮的周期是1秒,时间轮中有10个槽位,则每个槽位代表100ms。假设我们现在有3个任务,分别是任务A(220ms后执行)、B(410ms之后运行)、C(1930ms之后运行)。则这三个任务在时间轮所处的槽位如下图,可以看到任务A被放到了槽位2,任务B被放到了槽位4,任务C被放到了槽位9。
当时间轮转动到对应的槽时,就会从槽中取出任务判断是否需要执行。同时可以发现有一个剩余周期的概念,这是因为任务C的执行时间为1930ms,超过了时间轮的周期1秒,所以可以标记它的剩余周期为1,当时间轮第一次转动到它的位置时,发现它的剩余周期为1,表示还没有到要处理的时间,将剩余周期减1,时间轮继续转动,当下一次转动到C任务位置时,发现剩余周期为0,表示时间到了需要处理该定时任务了。Dubbo中采用的就是这种单层时间轮机制。

1.3 多层时间轮
既然有单层时间轮,那么自然而然可以想到利用多层时间轮来解决上述任务执行时间超出时间轮周期的情况。下面以两层时间轮为例,第一层时间轮周期为1秒,第二层时间轮周期为10秒。
还是以上述3个任务为例,可以看到任务A和B分布在第一层时间轮上,而任务C分布在第二层时间轮的槽1处。当第一层时间轮转动时,任务A和任务B会被先后执行。1秒钟之后,第一层时间轮完成了一个周期转动。从新开始第0跳,这时第二层时间轮从槽0跳到了槽1处,将槽1处的任务,也就是任务C取出放入到第一层时间轮的槽位9处,当第一层时间轮转动到槽位9处,任务C就会被执行。这种将第二层的任务取出放入第一层中称为降级,它是为了保证任务被处理的时间精度。Kafka内部就是采用的这种多层时间轮机制。

二、时间轮原理
下面先来看一下Dubbo中的时间轮的结构,可以看到,它和时钟很像,它被划分成了一个个Bucket,每个Bucket有一个头指针和尾指针,分别指向双向链表的头节点和尾节点,双向链表中存储的就是要处理的任务。时间轮不停转动,当指向Bucket0所负责维护的双向链表时,就将它所存储的任务遍历取出来处理。
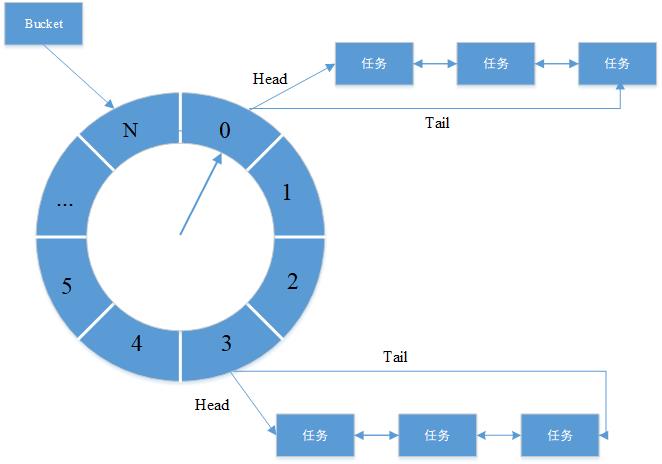
下面我们先来介绍下Dubbo中时间轮HashedWheelTimer所涉及到的一些核心概念,在讲解完这些核心概念之后,再来对时间轮的源码进行分析。
2.1 TimerTask
在Dubbo中,TimerTask封装了要执行的任务,它就是上图双向链表中节点所封装的任务。所有的定时任务都需要继承TimerTask接口。如下图,可以看到Dubbo中的心跳任务HeartBeatTask、注册失败重试任务FailRegisteredTask等都实现了TimerTask接口。
public interface TimerTask
void run(Timeout timeout) throws Exception;

2.2 Timeout
TimerTask中run方法的入参是Timeout,Timeout与TimerTask一一对应,Timeout的唯一实现类HashedWheelTimeout中就封装了TimerTask属性,可以理解为HashedWheelTimeout就是上述双向链表的一个节点,因此它也包含两个HashedWheelTimeout类型的指针,分别指向当前节点的上一个节点和下一个节点。
public interface Timeout
// Timer就是定时器, 也就是Dubbo中的时间轮
Timer timer();
// 获取该节点要执行的任务
TimerTask task();
// 判断该节点封装的任务有没有过期、被取消
boolean isExpired();
boolean isCancelled();
// 取消该节点的任务
boolean cancel();
HashedWheelTimeout是Timeout的唯一实现,它的作用有两个:
-
它是时间轮槽所维护的双向链表的节点,其中封装了实际要执行的任务TimerTask。
-
通过它可以查看定时任务的状态、对定时任务进行取消、从双向链表中移除等操作。
下面来看一下Timeout的实现类HashedWheelTimeout的核心字段与实现。
1) int ST_INIT = 0、int ST_CANCELLED = 1、int ST_EXPIRED = 2
HashedWheelTimeout里定义了三种状态,分别表示任务的初始化状态、被取消状态、已过期状态
2) STATE_UPDATER
用于更新定时任务的状态
3) HashedWheelTimer timer
指向时间轮对象
4) TimerTask task
实际要执行的任务
5) long deadline
指定时任务执行的时间,这个时间是在创建 HashedWheelTimeout 时指定的
计算公式是: currentTime(创建 HashedWheelTimeout 的时间) + delay(任务延迟时间)
- startTime(HashedWheelTimer 的启动时间),时间单位为纳秒
6) int state = ST_INIT
任务初始状态
7) long remainingRounds
指当前任务剩余的时钟周期数. 时间轮所能表示的时间长度是有限的, 在任务到期时间与当前时刻
的时间差超过时间轮单圈能表示的时长,就出现了套圈的情况,需要该字段值表示剩余的时钟周期
8) HashedWheelTimeout next、HashedWheelTimeout prev
分别对应当前定时任务在链表中的前驱节点和后继节点,这也验证了时间轮中每个槽所对应的任务链表是
一个双链表
9) HashedWheelBucket bucket
时间轮中的一个槽,对应时间轮圆圈的一个个小格子,每个槽维护一个双向链表,当时间轮指针转到当前
槽时,就会从槽所负责的双向链表中取出任务进行处理
HashedWheelTimeout提供了remove操作,可以从双向链表中移除当前自身节点,并将当前时间轮所维护的定时任务数量减一。
void remove()
// 获取当前任务属于哪个槽
HashedWheelBucket bucket = this.bucket;
if (bucket != null)
// 从槽中移除自己,也就是从双向链表中移除节点,
// 分析bucket的方法时会分析
bucket.remove(this);
else
// pendingTimeouts表示当前时间轮所维护的定时任务的数量
timer.pendingTimeouts.decrementAndGet();
HashedWheelTimeout提供了cancel操作,可以取消时间轮中的定时任务。当定时任务被取消时,它会首先被暂存到canceledTimeouts队列中。在时间轮转动到槽进行任务处理之前和时间轮退出运行时都会调用cancel,而cancel会调用remove,从而清理该队列中被取消的定时任务。
@Override
public boolean cancel()
// 通过CAS进行状态变更
if (!compareAndSetState(ST_INIT, ST_CANCELLED))
return false;
// 任务被取消时,时间轮会将它暂存到时间轮所维护的canceledTimeouts队列中.
// 在时间轮转动到槽进行任务处理之前和时间轮退出运行时都会调用cancel,而
// cancel会调用remove,从而清理该队列中被取消的定时任务
timer.cancelledTimeouts.add(this);
return true;
HashedWheelTimeout提供了expire操作,当时间轮指针转动到某个槽时,会遍历该槽所维护的双向链表,判断节点的状态,如果发现任务已到期,会通过remove方法移除,然后调用expire方法执行该定时任务。
public void expire()
// 修改定时任务状态为已过期
if (!compareAndSetState(ST_INIT, ST_EXPIRED))
return;
try
// 真正的执行定时任务所要代表的逻辑
task.run(this);
catch (Throwable t)
// 打印日志,可以看到当时间轮中定时任务执行异常时,
// 不会抛出异常,影响到时间轮中其他定时任务执行
2.3 HashedWheelBucket
前面也介绍过了,它是时间轮中的槽,它内部维护了双向链表的首尾指针。下面我们来看一下它内部的核心资源和实现。
1) HashedWheelTimeout head、HashedWheelTimeout tail
指向该槽所维护的双向链表的首节点和尾节点
HashedWheelBucket提供了addTimeout方法,用于添加任务到双向链表的尾节点。
void addTimeout(HashedWheelTimeout timeout)
// 添加之前判断一下该任务当前没有被被关联到一个槽上
assert timeout.bucket == null;
timeout.bucket = this;
if (head == null)
head = tail = timeout;
else
tail.next = timeout;
timeout.prev = tail;
tail = timeout;
HashedWheelBucket提供了remove方法,用于从双向链表中删除指定节点。核心逻辑如下图所示,根据要删除的节点找到其前置节点和后置节点,然后分别调整前置节点的next指针和后置节点的prev指针。删除过程中需要考虑一些边界情况。删除之后将pendingTimeouts,也就是当前时间轮的待处理任务数减一。remove代码逻辑较简单,这边就不贴代码了。

HashedWheelBucket提供了expireTimeouts方法,当时间轮指针转动到某个槽时,通过该方法处理该槽上双向链表的定时任务,分为3种情况:
-
定时任务已到期,则会通过remove方法取出,并调用其expire方法执行任务逻辑。
-
定时任务已被取消,则通过remove方法取出直接丢弃。
-
定时任务还未到期,则会将remainingRounds(剩余时钟周期)减一。
void expireTimeouts(long deadline)
HashedWheelTimeout timeout = head;
// 时间轮指针转到某个槽时从双向链表头节点开始遍历
while (timeout != null)
HashedWheelTimeout next = timeout.next;
// remainingRounds <= 0表示到期了
if (timeout.remainingRounds <= 0)
// 从链表中移除该节点
next = remove(timeout);
// 判断该定时任务确实是到期了
if (timeout.deadline <= deadline)
// 执行该任务
timeout.expire();
else
// 抛异常
else if (timeout.isCancelled())
// 任务被取消,移除后直接丢弃
next = remove(timeout);
else
// 剩余时钟周期减一
timeout.remainingRounds--;
// 继续判断下一个任务节点
timeout = next;
HashedWheelBucket也提供了clearTimeouts方法,该方法会在时间轮停止的时候被使用,它会遍历并移除所有双向链表中的节点,并返回所有未超时和未被取消的任务。
2.4 Worker
Worker实现了Runnable接口,时间轮内部通过Worker线程来处理放入时间轮中的定时任务。下面先来看一下它的核心字段和run方法逻辑。
1) Set<Timeout> unprocessedTimeouts
当时间轮停止时,用于存放时间轮中未过期的和未被取消的任务
2) long tick
时间轮指针,指向时间轮中某个槽,当时间轮转动时该tick会自增

public void run()
// 初始化startTime, 所有任务的的deadline都是相对于这个时间点
startTime = System.nanoTime();
// 唤醒阻塞在start()的线程
startTimeInitialized.countDown();
// 只要时间轮的状态为WORKER_STATE_STARTED, 就循环的转动tick,
// 处理槽中的定时任务
do
// 判断是否到了处理槽的时间了,还没到则sleep一会
final long deadline = waitForNextTick();
if (deadline > 0)
// 获取tick对应的槽索引
int idx = (int) (tick & mask);
// 清理用户主动取消的定时任务, 这些定时任务在用户取消时,
// 会记录到 cancelledTimeouts 队列中. 在每次指针转动
// 的时候,时间轮都会清理该队列
processCancelledTasks();
// 根据当前指针定位对应槽
HashedWheelBucket bucket = wheel[idx];
// 将缓存在 timeouts 队列中的定时任务转移到时间轮中对应的槽中
transferTimeoutsToBuckets();
// 处理该槽位的双向链表中的定时任务
bucket.expireTimeouts(deadline);
tick++;
// 检测时间轮的状态, 如果时间轮处于运行状态, 则循环执行上述步骤,
// 不断执行定时任务
while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this)
== WORKER_STATE_STARTED);
// 这里应该是时间轮停止了, 清除所有槽中的任务, 并加入到未处理任务列表,
// 以供stop()方法返回
for (HashedWheelBucket bucket : wheel)
bucket.clearTimeouts(unprocessedTimeouts);
// 将还没有加入到槽中的待处理定时任务队列中的任务取出, 如果是未取消
// 的任务, 则加入到未处理任务队列中, 以供stop()方法返回
for (; ; )
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null)
break;
if (!timeout.isCancelled())
unprocessedTimeouts.add(timeout);
// 最后再次清理 cancelledTimeouts 队列中用户主动取消的定时任务
processCancelledTasks();
下面对run方法中涉及到的一些方法进行介绍:
1)waitForNextTick
逻辑比较简单,它会判断有没有到达处理下一个槽任务的时间了,如果还没有到达则sleep一会。
2)processCancelledTasks
遍历cancelledTimeouts,获取被取消的任务并从双向链表中移除。
private void processCancelledTasks()
for (; ; )
HashedWheelTimeout timeout = cancelledTimeouts.poll();
if (timeout == null)
// all processed
break;
timeout.remove();
3)transferTimeoutsToBuckets
当调用newTimeout方法时,会先将要处理的任务缓存到timeouts队列中,等时间轮指针转动时统一调用transferTimeoutsToBuckets方法处理,将任务转移到指定的槽对应的双向链表中,每次转移10万个,以免阻塞时间轮线程。
private void transferTimeoutsToBuckets()
// 每次tick只处理10w个任务, 以免阻塞worker线程
for (int i = 0; i < 100000; i++)
HashedWheelTimeout timeout = timeouts.poll();
// 没有任务了直接跳出循环
if (timeout == null)
// all processed
break;
// 还没有放入到槽中就取消了, 直接略过
if (timeout.state() == HashedWheelTimeout.ST_CANCELLED)
continue;
// 计算任务需要经过多少个tick
long calculated = timeout.deadline / tickDuration;
// 计算任务的轮数
timeout.remainingRounds = (calculated - tick) / wheel.length;
// 如果任务在timeouts队列里面放久了, 以至于已经过了执行时间, 这个时候
// 就使用当前tick, 也就是放到当前bucket, 此方法调用完后就会被执行.
final long ticks = Math.max(calculated, tick);
int stopIndex = (int) (ticks & mask);
// 将任务加入到相应的槽中
HashedWheelBucket bucket = wheel[stopIndex];
bucket.addTimeout(timeout);
2.5 HashedWheelTimer
最后,我们来分析时间轮HashedWheelTimer,它实现了Timer接口,提供了newTimeout方法可以向时间轮中添加定时任务,该任务会先被暂存到timeouts队列中,等时间轮转动到某个槽时,会将该timeouts队列中的任务转移到某个槽所负责的双向链表中。它还提供了stop方法用于终止时间轮,该方法会返回时间轮中未处理的任务。它也提供了isStop方法用于判断时间轮是否终止了。
先来看一下HashedWheelTimer的核心字段。
1) HashedWheelBucket[] wheel
该数组就是时间轮的环形队列,数组每个元素都是一个槽,一个槽负责维护一个双向链表,用于存储定时
任务。它会被在构造函数中初始化,当指定为n时,它实际上会取最靠近n的且为2的幂次方值。
2) Queue<HashedWheelTimeout> timeouts
timeouts用于缓存外部向时间轮提交的定时任务
3) Queue<HashedWheelTimeout> cancelledTimeouts
cancelledTimeouts用于暂存被取消的定时任务,时间轮会在处理槽负责的双向链表之前,先处理这两
个队列中的数据。
4) Worker worker
时间轮处理定时任务的逻辑
5) Thread workerThread
时间轮处理定时任务的线程
6) AtomicLong pendingTimeouts
时间轮剩余的待处理的定时任务数量
7) long tickDuration
时间轮每个槽所代表的时间长度
8) int workerState
时间轮状态,可选值有init、started、shut down
下面来看一下时间轮的构造函数,用于初始化一个时间轮。首先它会对传入参数ticksPerWheel进行转换处理,返回大于该值的2的幂次方,它表示时间轮上有多少个槽,默认是512个。然后创建大小为该值的HashedWheelBucket[]数组。接着通过传入的tickDuration对时间轮的tickDuration赋值,默认是100ms。节通过threadFactory创建workerThread工作线程,该线程就是负责处理时间轮中的定时任务的线程。
public HashedWheelTimer(ThreadFactory threadFactory,
long tickDuration, TimeUnit unit,
int ticksPerWheel,
long maxPendingTimeouts)
// 圆环上一共有多少个时间间隔, HashedWheelTimer对其正则化
// 将其换算为大于等于该值的2^n
wheel = createWheel(ticksPerWheel);
// 这用来快速计算任务应该呆的槽
mask = wheel.length - 1;
// 时间轮每个槽的时间间隔
this.tickDuration = unit.toNanos(tickDuration);
// threadFactory是创建线程的线程工厂对象
workerThread = threadFactory.newThread(worker);
// 最多允许多少个任务等待执行
this.maxPendingTimeouts = maxPendingTimeouts;
private static HashedWheelBucket[] createWheel(int ticksPerWheel)
// 计算真正应当创建多少个槽
ticksPerWheel = normalizeTicksPerWheel(ticksPerWheel);
// 初始化时间轮数组
HashedWheelBucket[] wheel = new HashedWheelBucket[ticksPerWheel];
for (int i = 0; i < wheel.length; i++)
wheel[i] = new HashedWheelBucket();
return wheel;
初始化时间轮之后,就可以向其中提交定时任务了,可以通过时间轮提供的newTimeout方法来完成。首先将待处理的任务数量加1,然后启动时间轮线程,这时worker的run方法就会被系统调度运行。然后将该定时任务封装成HashedWheelTimeout加入到timeouts队列中。start之后,时间轮就开始运行起来了,直到外界调用stop方法终止退出。
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit)
// 待处理的任务数量加1
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
// 启动时间轮
start();
// 计算该定时任务的deadline
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// 创建一个HashedWheelTimeout对象,它首先会被暂存到timeouts队列中
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
timeouts.add(timeout);
return timeout;
public void start()
/**
* 判断当前时间轮的状态
* 1) 如果是初始化, 则启动worker线程, 启动整个时间轮
* 2) 如果已经启动则略过
* 3) 如果是已经停止,则报错
*/
switch (WORKER_STATE_UPDATER.get(this))
case WORKER_STATE_INIT:
// 使用cas来判断启动时间轮
if (WORKER_STATE_UPDATER.compareAndSet(this,
WORKER_STATE_INIT, WORKER_STATE_STARTED))
workerThread.start();
break;
case WORKER_STATE_STARTED:
break;
case WORKER_STATE_SHUTDOWN:
// 抛异常
default:
throw new Error("Invalid WorkerState");
// 等待worker线程初始化时间轮的启动时间
while (startTime == 0)
try
// 这里使用countDownLatch来确保调度的线程已经被启动
startTimeInitialized.await();
catch (InterruptedException ignore)
// Ignore - it will be ready very soon.
三、时间轮应用
到这里,Dubbo中的时间轮原理就分析完了。接下来呼应本文开头的三个例子,结合它们来分析下时间轮在Dubbo或Redisson中是如何使用的。
1)HeartbeatTimerTask
在Dubbo的HeaderExchangeClient类中会向时间轮中提交该心跳任务。
private void startHeartBeatTask(URL url)
// Client的具体实现决定是否启动该心跳任务
if (!client.canHandleIdle())
AbstractTimerTask.ChannelProvider cp =
() -> Collections.singletonList(HeaderExchangeClient.this);
// 计算心跳间隔, 最小间隔不能低于1s
int heartbeat = getHeartbeat(url);
long heartbeatTick = calculateLeastDuration(heartbeat);
// 创建心跳任务
this.heartBeatTimerTask =
new HeartbeatTimerTask(cp, heartbeatTick, heartbeat);
// 提交到IDLE_CHECK_TIMER这个时间轮中等待执行, 等时间到了时间轮就会去取出该任务进行调度执行
IDLE_CHECK_TIMER.newTimeout(heartBeatTimerTask, heartbeatTick, TimeUnit.MILLISECONDS);
// 上面用到的IDLE_CHECK_TIMER就是我们本文的分析的时间轮
private static final HashedWheelTimer IDLE_CHECK_TIMER =
new HashedWheelTimer(new NamedThreadFactory("dubbo-client-idleCheck", true), 1, TimeUnit.SECONDS, TICKS_PER_WHEEL);
// 上述创建心跳任务时, 创建了一个HeartbeatTimerTask对象, 可以看下该任务具体要做什么
@Override
protected void doTask(Channel channel)
try
// 获取最后一次读写时间
Long lastRead = lastRead(channel);
Long lastWrite = lastWrite(channel);
if ((lastRead != null && now() - lastRead > heartbeat)
|| (lastWrite != null && now() - lastWrite > heartbeat))
// 最后一次读写时间超过心跳时间, 就会发送心跳请求
Request req = new Request();
req.setVersion(Version.getProtocolVersion());
req.setTwoWay(true);
// 表明它是一个心跳请求
req.setEvent(HEARTBEAT_EVENT);
channel.send(req);
catch (Throwable t)
2)Redisson锁续期机制
当获取锁成功后,Redisson会封装一个锁续期任务放入时间轮中,默认10s检查一下,用于对获取到的锁进行续期,延长持有锁的时间。如果业务机器宕机了,那么该续期的定时任务也就没法跑了,就没法续期了,那等加锁时间到了锁就自动释放了。逻辑封装在RedissonLock中的renewExpiration()方法中。

private void renewExpiration()
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null)
return;
// 这边newTimeout点进去发现就是往时间轮中提交了一个任务
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask()
@Override
public void run(Timeout timeout) throws Exception
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null)
return;
Long threadId = ent.getFirstThreadId();
if (threadId == null)
return;
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) ->
if (e != null)
log.error("Can\'t update lock " + getName() + " expiration", e);
return;
if (res)
// 续期成功后继续调度, 又往时间轮中放一个续期任务
renewExpiration();
);
, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
protected RFuture<Boolean> renewExpirationAsync(long threadId)
// 通过lua脚本对锁进行续期
return evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call(\'hexists\', KEYS[1], ARGV[2]) == 1) then " +
"redis.call(\'pexpire\', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getName()),
internalLockLeaseTime, getLockName(threadId));
3)超时重试
使用方式和HeartbeatTimerTask方式类似,读者可以自己动手去分析下它是在哪里被引入的。
四、总结
在本篇文章中,先是举了3个例子来论述为什么需要使用时间轮,使用时间轮的优点,在文末处也分别对这3个例子在Dubbo或Redisson中的使用做了介绍。接着通过画图讲解了单层时间轮与多层时间轮机制,让读者对时间轮算法有了一个简单的认识。在第二部分,依次讲解了Dubbo时间轮中涉及到的TimerTask、Timeout、HashedWheelBucket、Worker、HashedWheelTimer,分析了它们的原理与源码实现。
作者:vivo互联网服务器团队-Li Wanghong
以上是关于时间轮原理及其在框架中的应用的主要内容,如果未能解决你的问题,请参考以下文章
SpringBoot定时任务 - 经典定时任务设计:时间轮(Timing Wheel)案例和原理
精华推荐 |算法数据结构专题「延时队列算法」史上非常详细分析和介绍如何通过时间轮(TimingWheel)实现延时队列的原理指南