时间轮原理及其在框架中的应用
Posted vivo互联网技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了时间轮原理及其在框架中的应用相关的知识,希望对你有一定的参考价值。
作者:vivo互联网服务器团队-Li Wanghong
一、时间轮简介
1.1 为什么要使用时间轮
在平时开发中,经常会与定时任务打交道。下面举几个定时任务处理的例子。
1)心跳检测。在Dubbo中,需要有心跳机制来维持Consumer与Provider的长连接,默认的心跳间隔是60s。当Provider在3次心跳时间内没有收到心跳响应,会关闭连接通道。当Consumer在3次心跳时间内没有收到心跳响应,会进行重连。Provider侧和Consumer侧的心跳检测机制都是通过定时任务实现的,而且是本篇文章要分析的时间轮HashedWheelTimer处理的。
2)超时处理。在Dubbo中发起RPC调用时,通常会配置超时时间,当消费者调用服务提供者出现超时进行一定的逻辑处理。那么怎么检测任务调用超时了呢?我们可以利用定时任务,每次创建一个Future,记录这个Future的创建时间与超时时间,后台有一个定时任务进行检测,当Future到达超时时间并且没有被处理时,就需要对这个Future执行超时逻辑处理。
3)Redisson分布式锁续期。在分布式锁处理中,通常会指定分布式锁的超时时间,同样会在finally块里释放分布式锁。但是有一个问题时,通常分布式锁的超时时间不好判断,如果设置短了业务却没执行完成就把锁释放掉了,或者超时时间设置很长,同样也会存在一些问题。Redisson提供了一种看门狗机制,通过时间轮定时给分布式锁续期,也就是延长分布式锁的超时时间。
可以看到,上述几个例子都与定时任务有关,那么传统的定时任务有什么缺点呢?为什么要使用时间轮来实现?
假如使用普通的定时任务处理机制来处理例2)中的超时情况:
1)简单地,可以针对每一次请求创建一个线程,然后Sleep到超时时间,之后若判断超时则进行超时逻辑处理。存在的问题是如果面临是高并发请求,针对每个请求都要去创建线程,这样太耗费资源了。
2)针对方案1的不足,可以改成一个线程来处理所有的定时任务,比如这个线程可以每隔50ms扫描所有需要处理的超时任务,如果发现有超时任务,则进行处理。但是,这样也存在一个问题,可能一段时间内都没有任务达到超时时间,那么就让CPU多了很多无用的轮询遍历操作。
针对上述方案的不足,可以采用时间轮来进行处理。下面先来简单介绍下时间轮的概念。
Exception; ST_INIT = ST_CANCELLED = ST_EXPIRED = HashedWheelTimeout里定义了三种状态,分别表示任务的初始化状态、被取消状态、已过期状态 用于更新定时任务的状态 指向时间轮对象 实际要执行的任务deadline 指定时任务执行的时间,这个时间是在创建 HashedWheelTimeout 时指定的 计算公式是: currentTime(创建 HashedWheelTimeout 的时间) + delay(任务延迟时间) - startTime(HashedWheelTimer 的启动时间),时间单位为纳秒state = ST_INIT 任务初始状态remainingRounds 指当前任务剩余的时钟周期数. 时间轮所能表示的时间长度是有限的, 在任务到期时间与当前时刻 的时间差超过时间轮单圈能表示的时长,就出现了套圈的情况,需要该字段值表示剩余的时钟周期 分别对应当前定时任务在链表中的前驱节点和后继节点,这也验证了时间轮中每个槽所对应的任务链表是 一个双链表 时间轮中的一个槽,对应时间轮圆圈的一个个小格子,每个槽维护一个双向链表,当时间轮指针转到当前 槽时,就会从槽所负责的双向链表中取出任务进行处理
HashedWheelTimeout提供了remove操作,可以从双向链表中移除当前自身节点,并将当前时间轮所维护的定时任务数量减一。
HashedWheelBucket bucket = (bucket != bucket.timer.pendingTimeouts.decrementAndGet();boolean cancel()(!compareAndSetState(ST_INIT, ST_CANCELLED))timer.cancelledTimeouts.add((!compareAndSetState(ST_INIT, ST_EXPIRED))task.run( (Throwable t)指向该槽所维护的双向链表的首节点和尾节点
HashedWheelBucket提供了addTimeout方法,用于添加任务到双向链表的尾节点。
timeout.bucket == timeout.bucket = (head == head = tail = timeout;tail.next = timeout;timeout.prev = tail;tail = timeout;deadline)HashedWheelTimeout timeout = head;(timeout != HashedWheelTimeout next = timeout.next;(timeout.remainingRounds <= next = (timeout.deadline <= deadline)timeout.expire();(timeout.isCancelled())next =timeout.remainingRounds--;timeout = next;当时间轮停止时,用于存放时间轮中未过期的和未被取消的任务tick时间轮指针,指向时间轮中某个槽,当时间轮转动时该tick会自增
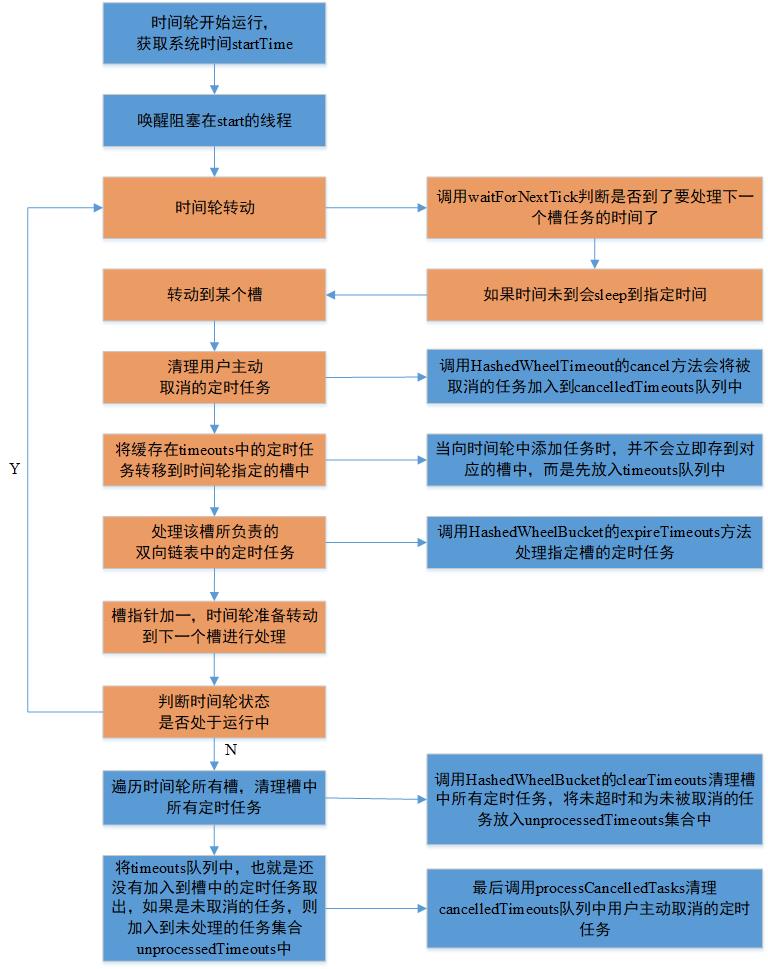
startTime = System.nanoTime();startTimeInitialized.countDown();final deadline = waitForNextTick();(deadline > idx = (processCancelledTasks();HashedWheelBucket bucket = wheel[idx];transferTimeoutsToBuckets();bucket.expireTimeouts(deadline);tick++;(WORKER_STATE_UPDATER. == WORKER_STATE_STARTED);(HashedWheelBucket bucket : wheel)bucket.clearTimeouts(unprocessedTimeouts);(; ; )HashedWheelTimeout timeout = timeouts.poll();(timeout ==(!timeout.isCancelled())unprocessedTimeouts.processCancelledTasks();(; ; )HashedWheelTimeout timeout = cancelledTimeouts.poll();(timeout ==timeout.(i = HashedWheelTimeout timeout = timeouts.poll();(timeout ==(timeout.state() == HashedWheelTimeout.ST_CANCELLED)calculated = timeout.deadline / tickDuration;timeout.remainingRounds = (calculated - tick) / wheel.length;ticks = Math.max(calculated, tick);stopIndex = (HashedWheelBucket bucket = wheel[stopIndex];bucket.addTimeout(timeout);该数组就是时间轮的环形队列,数组每个元素都是一个槽,一个槽负责维护一个双向链表,用于存储定时任务。它会被在构造函数中初始化,当指定为n时,它实际上会取最靠近n的且为timeouts用于缓存外部向时间轮提交的定时任务cancelledTimeouts用于暂存被取消的定时任务,时间轮会在处理槽负责的双向链表之前,先处理这两个队列中的数据。时间轮处理定时任务的逻辑时间轮处理定时任务的线程时间轮剩余的待处理的定时任务数量tickDuration时间轮每个槽所代表的时间长度workerState时间轮状态,可选值有init、started、shut down
下面来看一下时间轮的构造函数,用于初始化一个时间轮。首先它会对传入参数ticksPerWheel进行转换处理,返回大于该值的2的幂次方,它表示时间轮上有多少个槽,默认是512个。然后创建大小为该值的HashedWheelBucket[]数组。接着通过传入的tickDuration对时间轮的tickDuration赋值,默认是100ms。节通过threadFactory创建workerThread工作线程,该线程就是负责处理时间轮中的定时任务的线程。
tickDuration, TimeUnit unit,ticksPerWheel,maxPendingTimeouts)wheel = createWheel(ticksPerWheel);mask = wheel.length -workerThread = threadFactory.newThread(worker);HashedWheelBucket[] ticksPerWheel)ticksPerWheel = normalizeTicksPerWheel(ticksPerWheel);HashedWheelBucket[] wheel = HashedWheelBucket[ticksPerWheel];(i = wheel[i] = HashedWheelBucket();wheel;Timeout delay, TimeUnit unit)pendingTimeoutsCount = pendingTimeouts.incrementAndGet();start();deadline = System.nanoTime() + unit.toNanos(delay) - startTime;HashedWheelTimeout timeout = HashedWheelTimeout( timeouts. timeout;* 判断当前时间轮的状态* 1) 如果是初始化, 则启动worker线程, 启动整个时间轮* 2) 如果已经启动则略过* 3) 如果是已经停止,则报错*/(WORKER_STATE_UPDATER. WORKER_STATE_INIT:(WORKER_STATE_UPDATER.compareAndSet( WORKER_STATE_INIT, WORKER_STATE_STARTED))workerThread.start();WORKER_STATE_STARTED:WORKER_STATE_SHUTDOWN:Error((startTime ==startTimeInitialized. (InterruptedException ignore)(!client.canHandleIdle())AbstractTimerTask.ChannelProvider cp =() -> Collections.singletonList(HeaderExchangeClient. heartbeat = getHeartbeat(url);heartbeatTick = calculateLeastDuration(heartbeat);HeartbeatTimerTask(cp, heartbeatTick, heartbeat);IDLE_CHECK_TIMER.newTimeout(heartBeatTimerTask, heartbeatTick, TimeUnit.MILLISECONDS);HashedWheelTimer IDLE_CHECK_TIMER =HashedWheelTimer(NamedThreadFactory(Long lastRead = lastRead(channel);Long lastWrite = lastWrite(channel);((lastRead != && now() - lastRead > heartbeat)|| (lastWrite != && now() - lastWrite > heartbeat))Request req = Request();req.setVersion(Version.getProtocolVersion());req.setTwoWay( req.setEvent(HEARTBEAT_EVENT);channel.send(req);(Throwable t)void renewExpiration()ExpirationEntry ee = EXPIRATION_RENEWAL_MAP. (ee ==Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask()void run(Timeout timeout) throws ExceptionExpirationEntry ent = EXPIRATION_RENEWAL_MAP. (ent ==threadId = ent.getFirstThreadId();(threadId ==RFuture< future.onComplete((res, e) ->(e != log.error(+ getName() +(res)renewExpiration(););, internalLockLeaseTime /ee.setTimeout(task);RFuture<Boolean> threadId)evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,++++Collections.singletonList(getName()),internalLockLeaseTime, getLockName(threadId));
源码解读Dubbo分层设计思想
详解Apache Dubbo的SPI实现机制
SPI 在 Dubbo中 的应用
视频LSTM神经网络架构和原理及其在Python中的预测应用|数据分享
原文链接:http://tecdat.cn/?p=23544
长短期记忆网络——通常称为“LSTM”——是一种特殊的RNN递归神经网络,能够学习长期依赖关系。
视频:LSTM神经网络架构和工作原理及其在Python中的预测应用
LSTM神经网络架构和原理及其在Python中的预测应用
什么是依赖关系?
假设您在观看视频时记得前一个场景,或者在阅读一本书时您知道前一章发生了什么。
传统的神经网络无法做到这一点,这是一个主要缺点。例如,假设您想对电影中每一点发生的事件进行分类。目前尚不清楚传统的神经网络如何利用电影中先前事件来推理后来的事件。
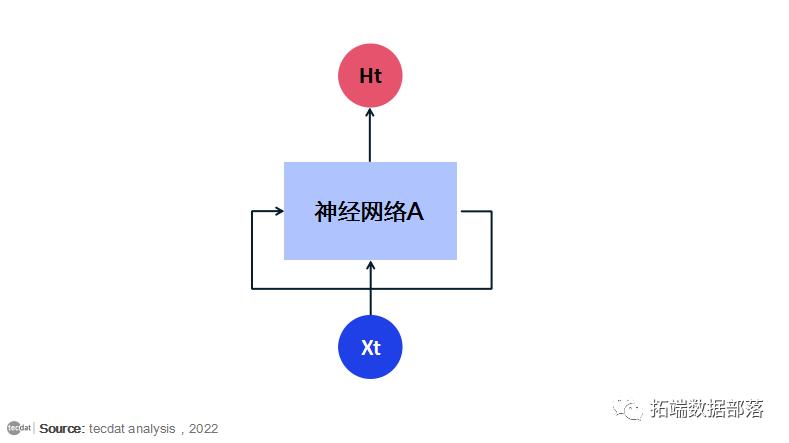
递归神经网络解决了这个问题。它们是带有循环的网络,允许信息持续存在。循环神经网络有循环。
在上图中,一大块神经网络,查看一些输入x并输出一个值h. 循环允许信息从网络的一个步骤传递到下一个步骤。
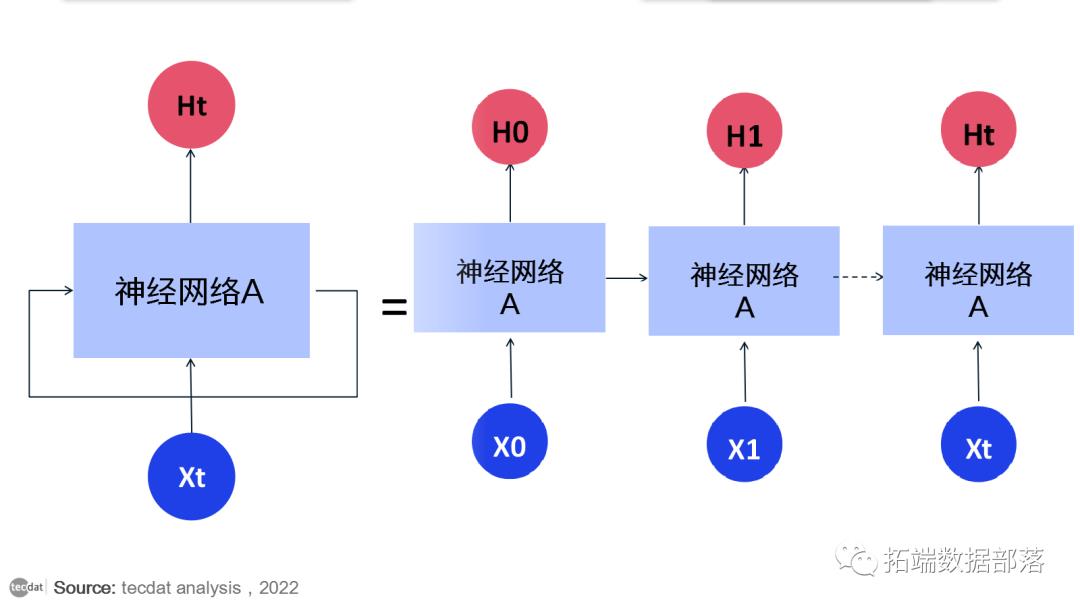
这些循环使循环神经网络看起来有点神秘。然而,如果你想得更多,就会发现它们与普通的神经网络并没有什么不同。循环神经网络可以被认为是同一网络的多个副本,每个副本都将消息传递给后继者。考虑一下如果我们展开循环会发生什么:
这种链状性质表明循环神经网络与序列和列表密切相关。它们是用于此类数据的神经网络的自然架构。在过去的几年里,将 RNN 应用于各种问题取得了令人难以置信的成功:语音识别、语言建模、翻译、图像字幕……不胜枚举。这些成功的关键是使用“LSTM”,这是一种非常特殊的循环神经网络,几乎所有基于循环神经网络的令人兴奋的结果都是用它们实现的。本文将探讨的正是这些 LSTM。
长期依赖问题
下面是一个关于如何使用循环神经网络(RNN)来拟合语言模型的例子。
RNN 的吸引力之一是它们可能能够将先前的信息与当前任务联系起来,例如使用先前的视频帧可能会告知对当前帧的理解。如果 RNN 可以做到这一点,它们将非常有用。但他们可以吗?
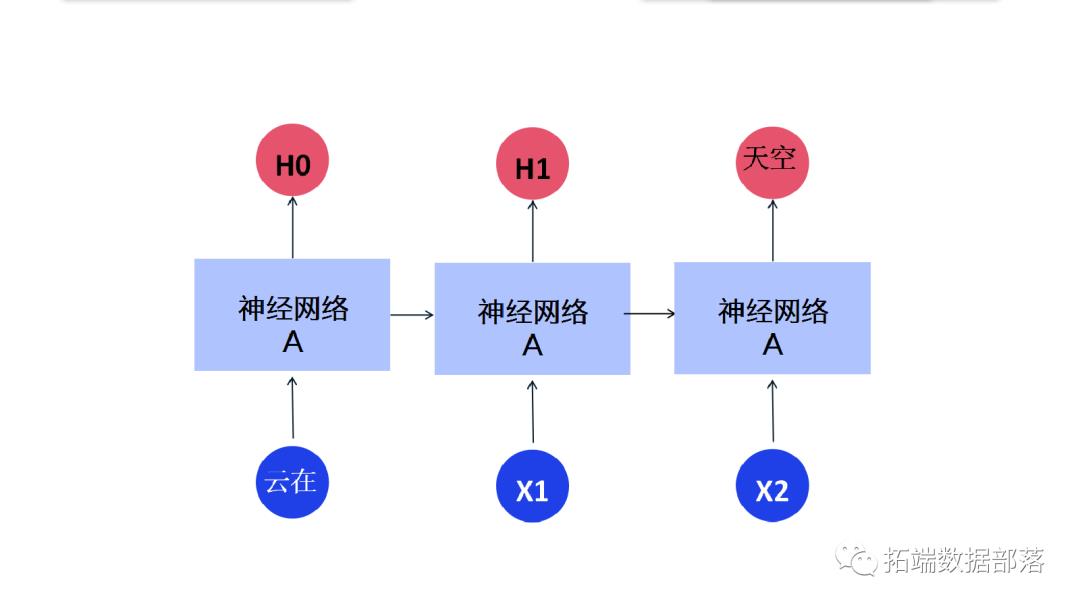
有时,我们只需要查看最近的信息即可执行当前任务。例如,考虑一个语言模型试图根据之前的单词预测下一个单词。如果我们试图预测“云在天空”中的最后一个词,我们不需要任何进一步的上下文——很明显下一个词将是天空。在这种情况下,相关信息与所需位置之间的差距很小,RNN 可以学习使用过去的信息。
但也有我们需要更多上下文的情况。考虑尝试预测文本“我在中国长大……我说地道的中文”中的最后一个词。最近的信息表明,下一个词可能是一种语言的名称,但如果我们想缩小哪种语言的范围,我们需要中国的上下文,从更远的地方。相关信息和需要的点之间的差距完全有可能变得非常大。
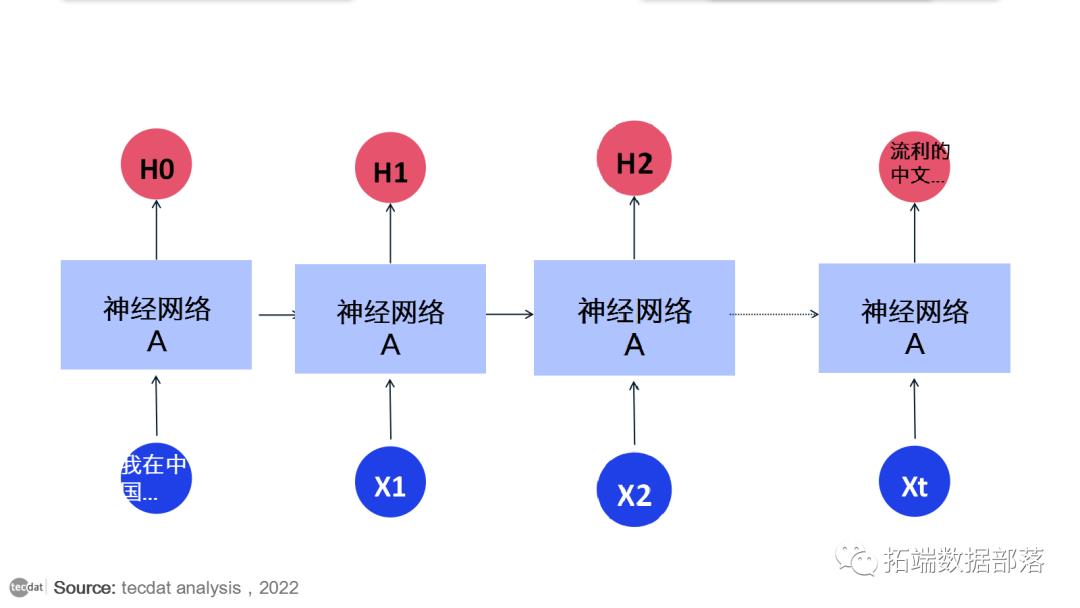
随着差距的扩大,RNN 变得无法学习连接信息。
LSTM 网络
长短期记忆网络——通常称为“LSTM”——是一种特殊的 RNN,能够学习长期依赖关系。它们在解决各种各样的问题时表现出色,现在被广泛使用。LSTM 被明确设计为避免长期依赖问题。长时间记住信息实际上是他们的默认行为,而不是他们难以学习的东西!
所有循环神经网络都具有神经网络的重复模块链的形式。在标准 RNN 中,此重复模块将具有非常简单的结构,例如单个 tanh 层。
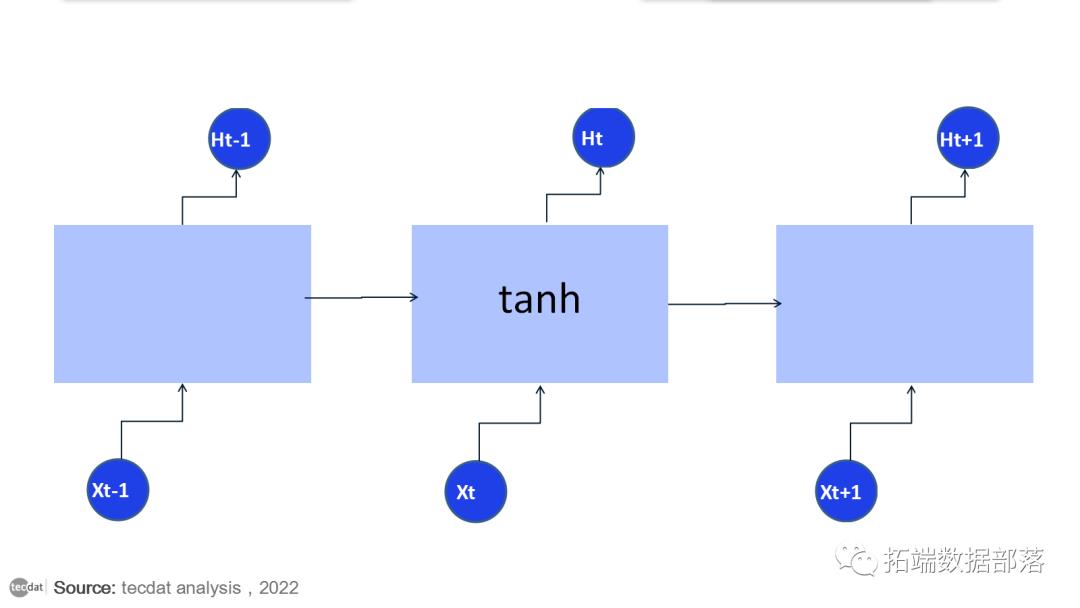
LSTM 也有这种链状结构,但重复模块有不同的结构。不是只有一个神经网络层,而是三个部分组成,以一种非常特殊的方式进行交互。

LSTM 的工作方式非常类似于 RNN 单元。这是 LSTM 网络的内部功能。LSTM 由三个部分组成,如图所示,每个部分执行一个单独的功能。第一部分选择来自前一个时间戳的信息是被记住还是不相关并且可以被遗忘。在第二部分中,单元尝试从该单元的输入中学习新信息。最后,在第三部分,单元将更新的信息从当前时间戳传递到下一个时间戳。LSTM 单元的这三个部分称为门。第一部分称为忘记门或遗忘门,第二部分称为输入门,最后一部分称为输出门。
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
每年的降雨量数据可能是相当不平稳的。与温度不同,温度通常在四季中表现出明显的趋势,而雨量作为一个时间序列可能是相当不平稳的。夏季的降雨量与冬季的降雨量一样多是很常见的。
下面是某地区2020年11月降雨量数据(查看文末了解数据获取方式)的图解。
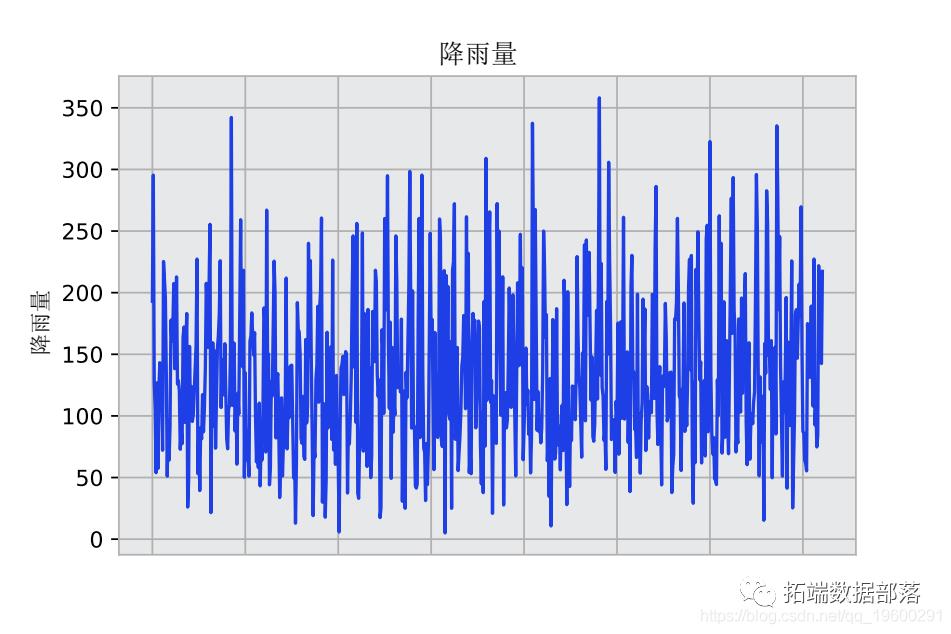
作为一个连续的神经网络,LSTM模型可以证明在解释时间序列的波动性方面有优势。
使用Ljung-Box检验,小于0.05的p值表明这个时间序列中的残差表现出随机模式,表明有明显的波动性。
>>> sm.stats.acorr_ljungbox(res.resid, lags=\\[10\\])
Ljung-Box检验
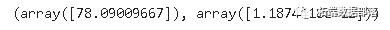
Dickey-Fuller 检验
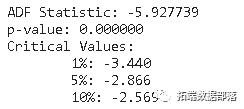
数据操作和模型配置
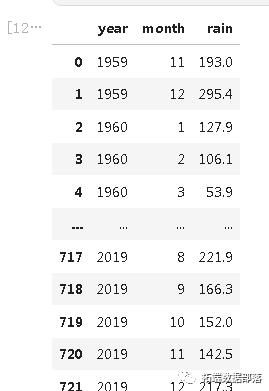
该数据集由722个月的降雨量数据组成。
选择712个数据点用于训练和验证,即用于建立LSTM模型。然后,过去10个月的数据被用来作为测试数据,与LSTM模型的预测结果进行比较。
下面是数据集的一个片段。
然后形成一个数据集矩阵,将时间序列与过去的数值进行回归。
# 形成数据集矩阵 for i in range(len(df)-previous-1): a = df\\[i:(i+previous), 0\\] dataX.append(a) dataY.append(df\\[i + previous, 0\\])
然后用MinMaxScaler对数据进行标准化处理。

将前一个参数设置为120,训练和验证数据集就建立起来了。作为参考,previous = 120说明模型使用从t - 120到t - 1的过去值来预测时间t的雨量值。
前一个参数的选择要经过试验,但选择120个时间段是为了确保识别到时间序列的波动性或极端值。
# 训练和验证数据的划分 train_size = int(len(df) * 0.8) val\\_size = len(df) - train\\_size train, val = df\\[0:train\\_size,:\\], df\\[train\\_size:len(df),:\\]# 前期的数量 previous = 120
然后,输入被转换为样本、时间步骤、特征的格式。
# 转换输入为\\[样本、时间步骤、特征\\]。 np.reshape(X_train, (shape\\[0\\], 1, shape\\[1\\]))
模型训练和预测
该模型在100个历时中进行训练,并指定了712个批次的大小(等于训练和验证集中的数据点数量)。
# 生成LSTM网络 model = tf.keras.Sequential() # 列出历史中的所有数据 print(history.history.keys()) # 总结准确度变化 plt.plot(history.history\\['loss'\\])
下面是训练集与验证集的模型损失的关系图。
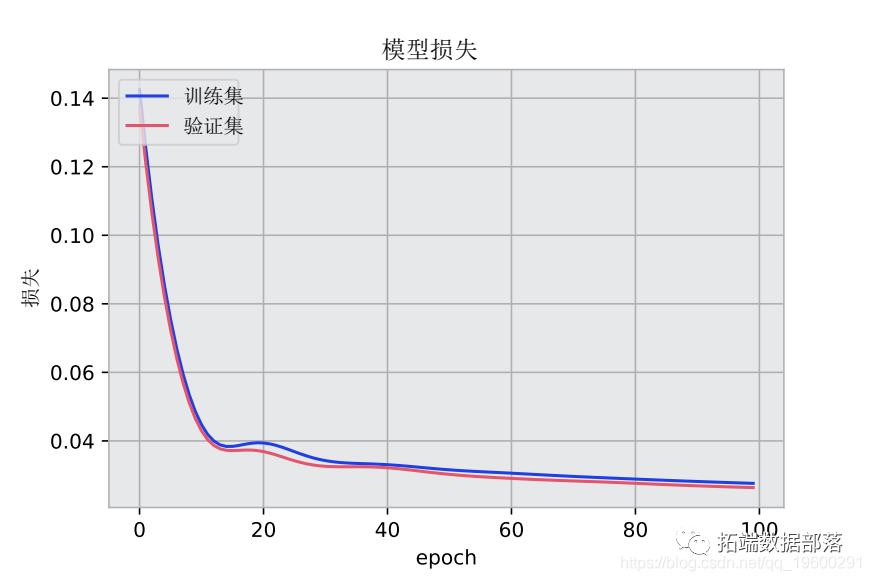
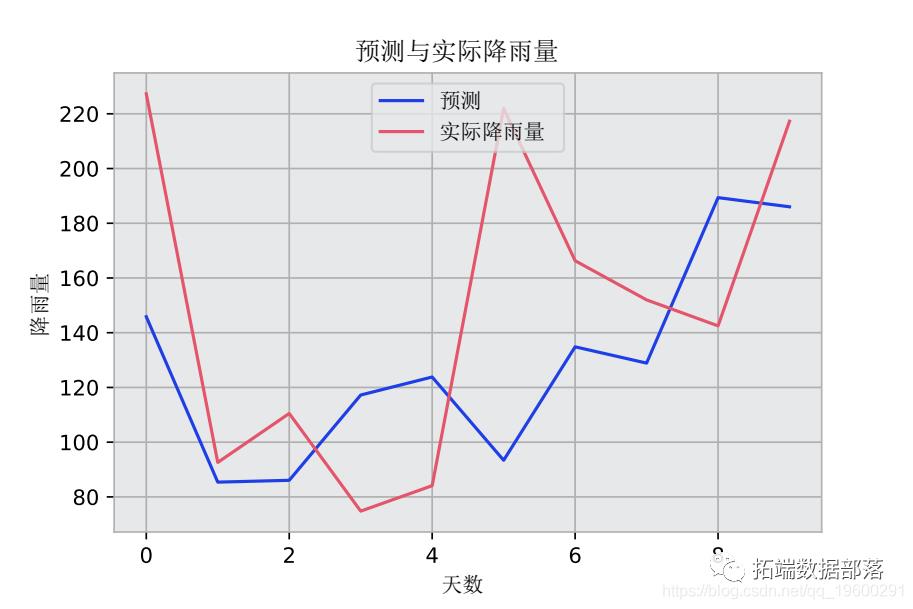
预测与实际降雨量的关系图也被生成。
# 绘制所有预测图 plt.plot(valpredPlot)

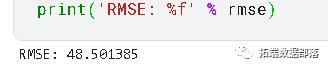
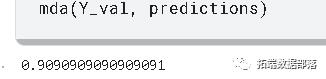
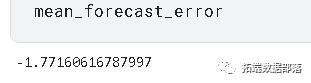
预测结果在平均方向准确性(MDA)、平均平方根误差(RMSE)和平均预测误差(MFE)的基础上与验证集进行比较。
mda(Y_val, predictions)0.9090909090909091 >>> mse = mean\\_squared\\_error(Y_val, predictions) >>> rmse = sqrt(mse) >>> forecast_error >>> mean\\_forecast\\_error = np.mean(forecast_error)
-
MDA: 0.909
-
RMSE: 48.5
-
MFE: -1.77
针对测试数据进行预测
虽然验证集的结果相当可观,但只有将模型预测与测试(或未见过的)数据相比较,我们才能对LSTM模型的预测能力有合理的信心。
如前所述,过去10个月的降雨数据被用作测试集。然后,LSTM模型被用来预测未来10个月的情况,然后将预测结果与实际值进行比较。
至t-120的先前值被用来预测时间t的值。
# 测试(未见过的)预测 np.array(\\[tseries.iloctseries.iloc,t
获得的结果如下
-
MDA: 0.8
-
RMSE: 49.57
-
MFE: -6.94
过去10个月的平均降雨量为148.93毫米,预测精度显示出与验证集相似的性能,而且相对于整个测试集计算的平均降雨量而言,误差很低。
结论
在这个例子中,你已经看到:
-
如何准备用于LSTM模型的数据
-
构建一个LSTM模型
-
如何测试LSTM的预测准确性
-
使用LSTM对不稳定的时间序列进行建模的优势
数据获取
在下面公众号后台回复“降雨量数据”,可获取完整数据。

本文摘选《Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析》,点击“阅读原文”获取全文完整资料。
点击标题查阅往期内容
深度学习实现自编码器Autoencoder神经网络异常检测心电图ECG时间序列
Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
欲获取全文文件,请点击左下角“阅读原文”。
以上是关于时间轮原理及其在框架中的应用的主要内容,如果未能解决你的问题,请参考以下文章