华为云MRS基于Hudi和HetuEngine构建实时数据湖最佳实践
Posted 华为云官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了华为云MRS基于Hudi和HetuEngine构建实时数据湖最佳实践相关的知识,希望对你有一定的参考价值。
数据湖与实时数据湖是什么?
各个行业企业都在构建企业级数据湖,将企业内多种格式数据源汇聚的大数据平台,通过严格的数据权限和资源管控,将数据和算力开放给各种使用者。一份数据支持多种分析,是数据湖最大的特点。如果数据湖的数据,从数据源产生后,可以在1分钟以内实时进入到数据湖存储,支持各种交互式分析,这种数据湖通常叫做实时数据湖,如果可以做到15分钟之内,也可称为准实时数据湖。构建实时数据湖,正在成为5G和IOT时代,支撑各个企业实时分析业务的数据湖新目标。
华为MRS实时数据湖方案介绍
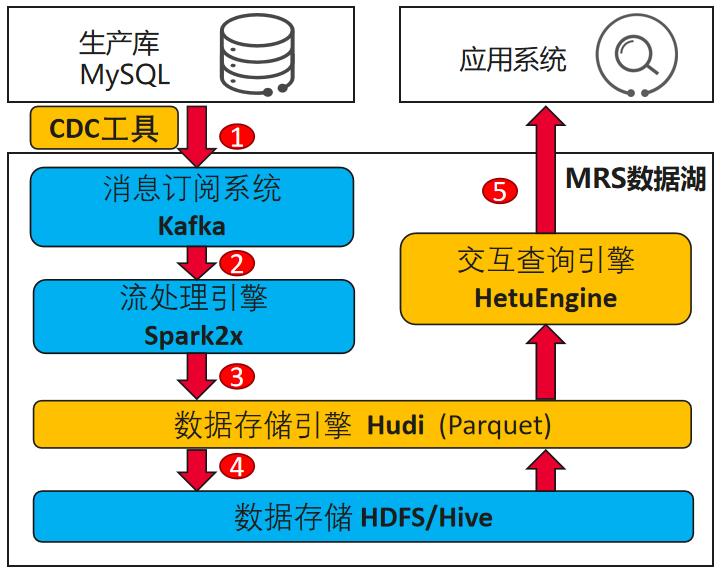
- 生产库数据通过CDC工具(debezium)实时录入到MRS集群中Kafka的指定topic里;
- 在MRS集群启动一个SparkStreaming任务,实时读取Kafka指定topic里的数据;
- 同时该SparkStreaming任务将读取到的数据进行解析处理并写入到一张hudi表中;
- 写入hudi表的同时可以指定该数据也写入hive表;
- 通过MRS提供的交互式查询引擎HetuEngine对数据进行快速的交互式查询。
使用华为MRS实时数据湖方案的优势:
- ACID事务能力得以保证,湖内一份数据满足所有的分析业务需求,减少数据搬迁,减少数据冗余;
- 数据一致性保证,保证增量数据与入湖后数据一致性检测;
- 数据加工流转,在一个存储层内闭环,数据流动更高效;
- 基于HetuEngine引擎实现交互式查询,性能不降低。
下面会针对方案的三个关键组件:CDC工具,数据存储引擎Hudi,交互式查询引擎HetuEngine进行详细的介绍
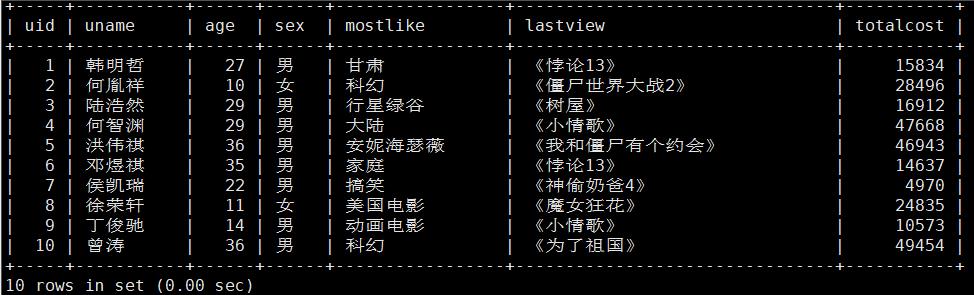
样例数据简介
生产库MySQL原始数据(前10条,共1000条):
CDC工具
简介
CDC(changed data capture)为动态数据抓取,常见的方式分为同步和异步。同步CDC主要是采用触发器记录新增数据,基本能够做到实时增量抽取。而异步CDC则是通过分析已经commit的日志记录来得到增量数据信息。常见的CDC工具有Canal, DataBus, Maxwell, Debezium, OGG等。本方案采用debezium作为CDC工具
对接步骤
具体参考:https://fusioninsight.github.io/ecosystem/zh-hans/Data_Integration/DEBEZIUM/
完成对接后,针对MySQL生产库分别做增、改、删除操作对应的kafka消息
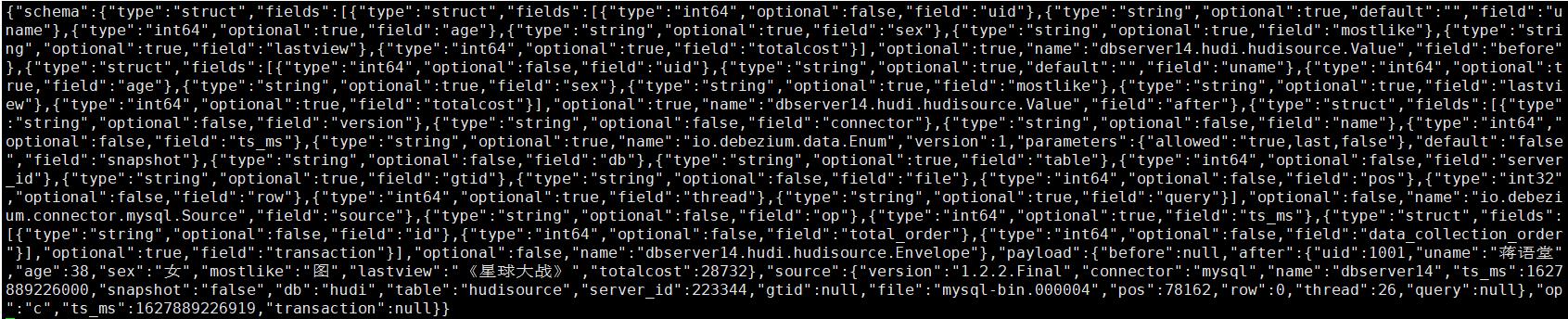
增加操作: insert into hudi.hudisource values (1001,“蒋语堂”,38,“女”,“图”,"《星球大战》",28732);
对应kafka消息体:
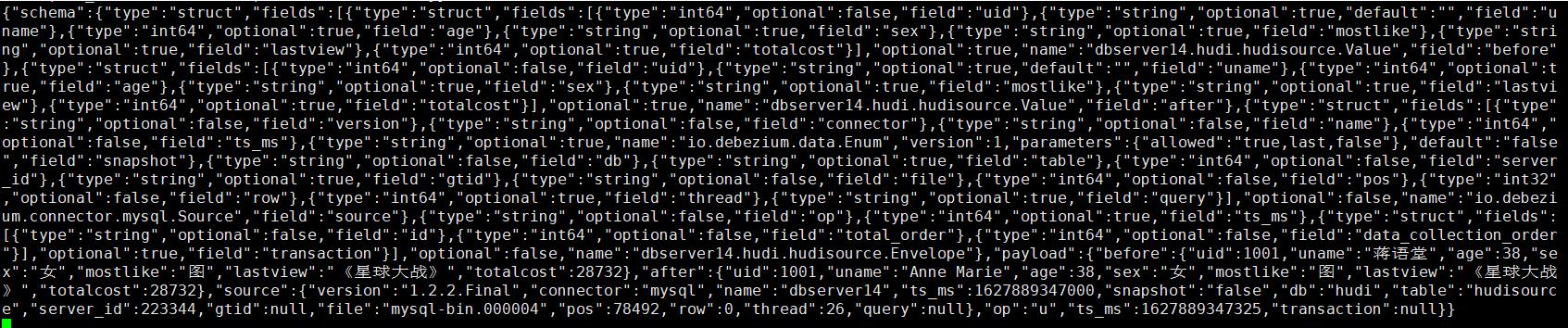
更改操作: UPDATE hudi.hudisource SET uname=‘Anne Marie’ WHERE uid=1001;
对应kafka消息体:
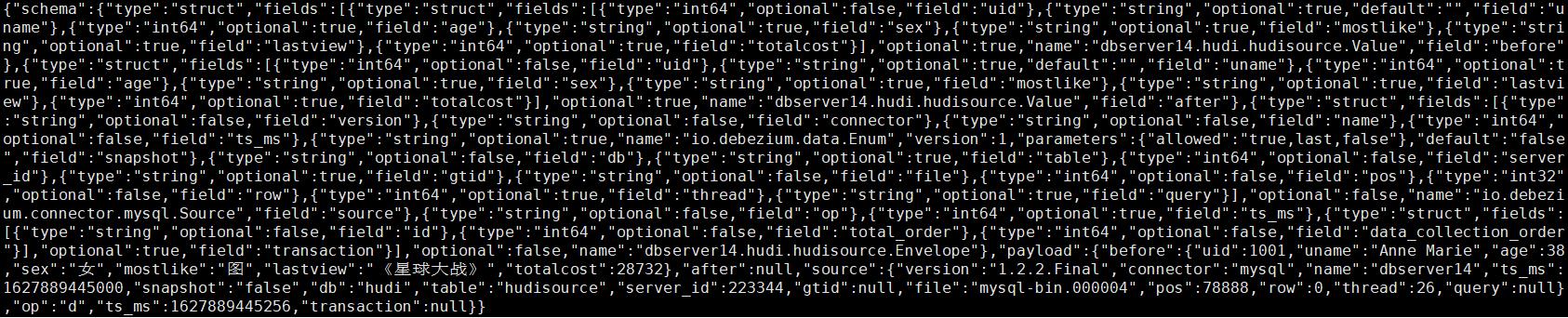
删除操作: delete from hudi.hudisource where uid=1001;
对应kafka消息体:
Hudi
简介
Apache Hudi是一个Data Lakes的开源方案,Hudi是Hadoop Updates and Incrementals的简写。具有以下的特性
- ACID事务能力,支持实时入湖和批量入湖。
- 多种视图能力(读优化视图/增量视图/实时视图),支持快速数据分析。
- MVCC设计,支持数据版本回溯。
- 自动管理文件大小和布局,以优化查询性能准实时摄取,为查询提供最新数据。
- 支持并发读写,基于snapshot的隔离机制实现写入时可读取。
- 支持原地转表,将存量的历史表转换为Hudi数据集。
样例代码解析
使用Hudi实时入湖的样例代码分三个部分
- Kafka数据消费
- 数据内容解析、处理
- 解析后数据的写入
Kafka数据消费部分样例代码:
String savePath = "hdfs://hacluster/huditest2/";
String groupId = "group1";
System.out.println("groupID is: " + groupId);
String brokerList = "172.16.5.51:21005";
System.out.println("brokerList is: " + brokerList);
String topic = "hudisource";
System.out.println("topic is: " + topic);
String interval = "5";
HashMap<String, Object> kafkaParam = new HashMap<>();
kafkaParam.put("bootstrap.servers", brokerList);
kafkaParam.put("group.id", groupId);
kafkaParam.put("auto.offset.reset", "earliest");
kafkaParam.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaParam.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
HashSet<String> topics = new HashSet<>();
topics.add(topic);
String[] topicArray = topic;
Set<String> topicSet = new HashSet<String>(Arrays.asList(topicArray));
ConsumerStrategy consumerStrategy = ConsumerStrategies.Subscribe(topicSet, kafkaParam);
//本地调试
SparkConf conf = new SparkConf()
.setMaster("local[*]")
.setAppName("hudi-java-demo");
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
conf.set("spark.streaming.kafka.maxRatePerPartition", "10");
conf.set("spark.streaming.backpressure.enabled", "true");
JavaInputDStream<ConsumerRecord<String, String>> directStream = KafkaUtils.createDirectStream(jssc,
LocationStrategies.PreferConsistent(),
consumerStrategy);
数据内容解析、处理部分样例代码:
JavaDStream<List> lines =
directStream.filter(
//过滤空行和脏数据
new Function<ConsumerRecord<String, String>, Boolean>()
public Boolean call(ConsumerRecord<String, String> v1) throws Exception
if (v1.value() == null)
return false;
try
String op = debeziumJsonParser.getOP(v1.value());
catch (Exception e)
return false;
return true;
).map(
new Function<ConsumerRecord<String, String>, List>()
public List call(ConsumerRecord<String, String> v1) throws Exception
//将debezium接进来的数据解析写进List
String op = debeziumJsonParser.getOP(v1.value());
JSONObject json_obj = JSON.parseObject(v1.value());
Boolean is_delete = false;
String out_str = "";
if(op.equals("c"))
out_str = json_obj.getJSONObject("payload").get("after").toString();
else if(op.equals("u"))
out_str = json_obj.getJSONObject("payload").get("after").toString();
else
is_delete = true;
out_str = json_obj.getJSONObject("payload").get("before").toString();
LinkedHashMap<String, String> jsonMap = JSON.parseObject(out_str, new TypeReference<LinkedHashMap<String, String>>()
);
int cnt =0;
List out_list = new ArrayList();
for (Map.Entry<String, String> entry : jsonMap.entrySet())
out_list.add(entry.getValue());
cnt++;
out_list.add(is_delete);
String commitTime = Long.toString(System.currentTimeMillis());
out_list.add(commitTime);
System.out.println(out_list);
out_list.add(op);
return out_list;
);
debezium更新字段解析样例代码:
public class debeziumJsonParser
public static String getOP(String message)
JSONObject json_obj = JSON.parseObject(message);
String op = json_obj.getJSONObject("payload").get("op").toString();
return op;
解析后数据的写入hudi表,hive表样例代码:
lines.foreachRDD(new VoidFunction<JavaRDD<List>>()
@Override
public void call(JavaRDD<List> stringJavaRDD) throws Exception
if (!stringJavaRDD.isEmpty())
System.out.println("stringJavaRDD collect---"+stringJavaRDD.collect());
List<Row> rowList =new ArrayList<>();
//把数据上一步数据写进stringJavaRdd
for(List row: stringJavaRDD.collect())
String uid = row.get(0).toString();
String name = row.get(1).toString();
String age = row.get(2).toString();
String sex = row.get(3).toString();
String mostlike = row.get(4).toString();
String lastview = row.get(5).toString();
String totalcost = row.get(6).toString();
Boolean _hoodie_is_deleted = Boolean.valueOf(row.get(7).toString());
String commitTime = row.get(8).toString();
String op = row.get(9).toString();
Row returnRow = RowFactory.create(uid, name, age, sex, mostlike, lastview, totalcost, _hoodie_is_deleted, commitTime, op);
rowList.add(returnRow);
JavaRDD<Row> stringJavaRdd = jsc.parallelize(rowList);
//写入表的字段schema设计
List<StructField> fields = new ArrayList<>();
fields.add(DataTypes.createStructField("uid", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("name", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("age", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("sex", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("mostlike", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("lastview", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("totalcost", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("_hoodie_is_deleted", DataTypes.BooleanType, true));
fields.add(DataTypes.createStructField("commitTime", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("op", DataTypes.StringType, true));
StructType schema = DataTypes.createStructType(fields);
Dataset<Row> dataFrame = sqlContext.createDataFrame(stringJavaRdd, schema);
Dataset<Row> rowDataset = dataFrame.withColumn("ts", dataFrame.col("commitTime"))
.withColumn("uuid", dataFrame.col("uid"));
//将数据写入hudi表以及hive表
rowDataset.write().format("org.apache.hudi")
.option("PRECOMBINE_FIELD_OPT_KEY", "ts")
.option("RECORDKEY_FIELD_OPT_KEY", "uuid")
.option("hoodie.datasource.write.keygenerator.class", "org.apache.hudi.keygen.NonpartitionedKeyGenerator")
.option("hoodie.table.name", "huditesttable")
.option("hoodie.upsert.shuffle.parallelism", "10")
.option("hoodie.delete.shuffle.parallelism", "10")
.option("hoodie.insert.shuffle.parallelism", "10")
.option("hoodie.bulkinsert.shuffle.parallelism", "10")
.option("hoodie.finalize.write.parallelism", "10")
.option("hoodie.cleaner.parallelism", "10")
.option("hoodie.datasource.write.operation", "upsert")
.option("hoodie.datasource.hive_sync.enable", "true")
.option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.NonPartitionedExtractor")
.option("hoodie.datasource.hive_sync.database", "default")
.option("hoodie.datasource.hive_sync.table", "hudidebezium")
.option("hoodie.datasource.hive_sync.use_jdbc", "false")
.mode(SaveMode.Append)
.save(savePath);
);
jssc.start();
jssc.awaitTermination();
jssc.close();
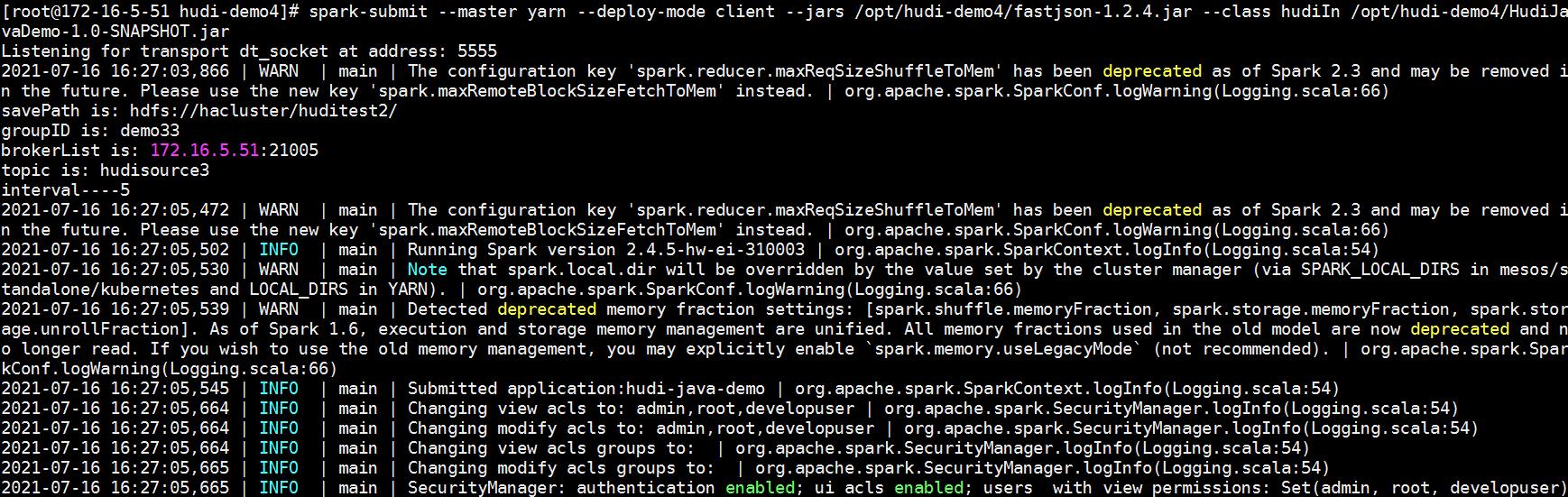
Hudi任务提交命令
source /opt/client/bigdata_env
source /opt/client/Hudi/component_env
spark-submit --master yarn --deploy-mode client --jars /opt/hudi-demo4/fastjson-1.2.4.jar --class hudiIn /opt/hudi-demo4/HudiJavaDemo-1.0-SNAPSHOT.jar
HetuEngine
简介
HetuEngine是华为FusionInsight MRS提供的高性能分布式SQL查询、数据虚拟化引擎。能与大数据生态无缝融合,实现海量数据秒级查询;支持多源异构协同,提供数据湖内一站式SQL融合分析。
同时HetuEngine拥有开放的接口,能够支持各报表、分析软件对接,具体可参考生态地图:https://fusioninsight.github.io/ecosystem/zh-hans/
下面我们以帆软FineBI为例进行查询、分析。
配置FineBI对接HetuEngine

JDBC URL: jdbc:presto://172.16.5.51:29860,172.16.5.52:29860/hive/default?serviceDiscoveryMode=hsbroker&tenant=default
查看初始同步数据:

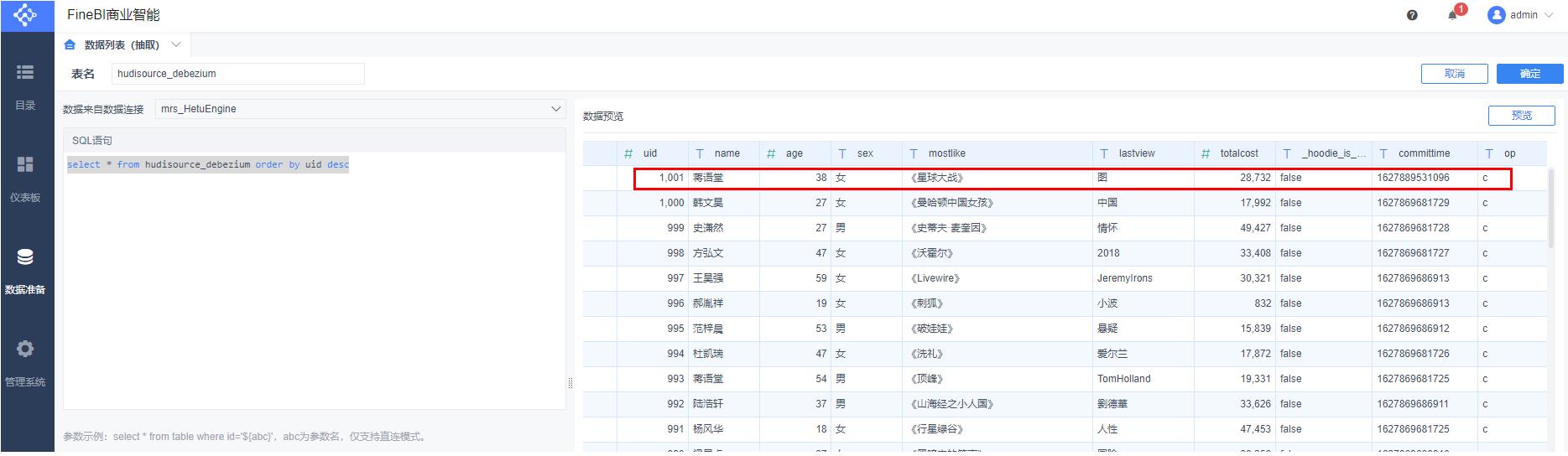
通过HetuEngine检查增、改、删除操作
Mysql增加操作对应hive表结果:
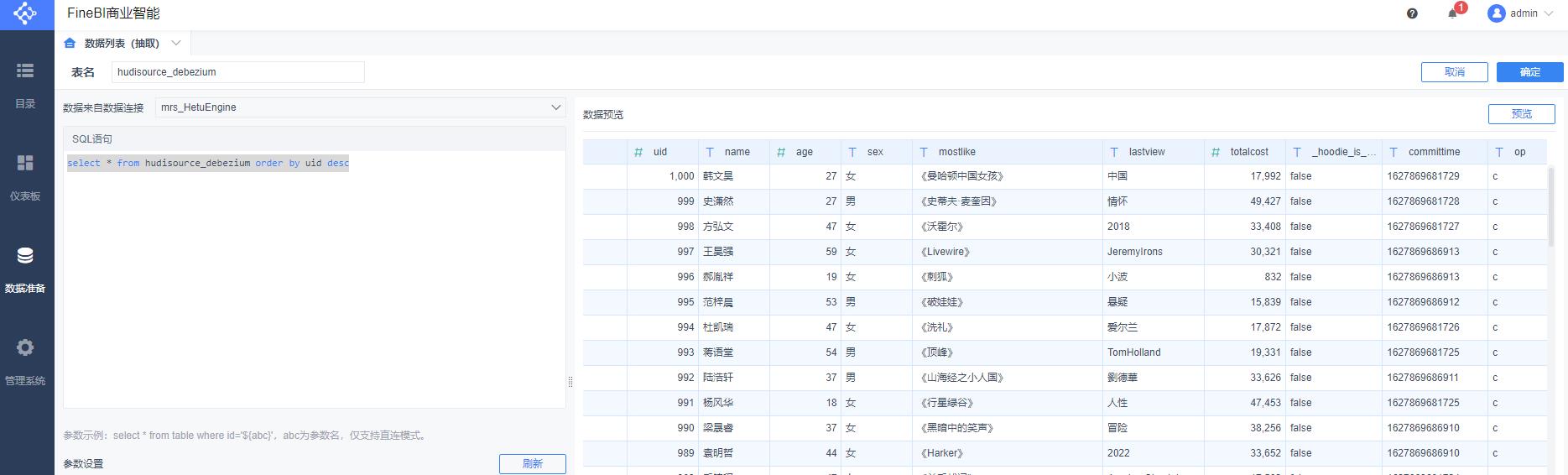
Mysql更改操作对应hive表结果:

Mysql删除操作对应hive表结果:
报表:
电影喜爱度分析:
电影标签喜爱度分析:

以上是关于华为云MRS基于Hudi和HetuEngine构建实时数据湖最佳实践的主要内容,如果未能解决你的问题,请参考以下文章
一文带你体验MRS HetuEngine如何实现跨源跨域分析
FusionInsight MRS Flink DataStream API读写Hudi实践