MRS HetuEgine的数据虚拟化实践
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MRS HetuEgine的数据虚拟化实践相关的知识,希望对你有一定的参考价值。
摘要:华为MRS云原生数据湖平台的HetuEngine就是一款解决大数据时代跨源跨域问题的数据虚拟化引擎。
本文分享自华为云社区《基于华为云原生数据湖MRS HetuEgine的数据虚拟化实践》,作者: 前锋 。
数据虚拟化是指一种数据管理方式,允许应用在不关心数据源的数据格式及物理存储位置的情况下以一种统一的方式获取和使用整个组织中所有的数据。与数据虚拟化方式对应的一种方式是传统的ETL方式,数据经过抽取、转换和装载的过程,将不同系统的数据收集到一个统一的物理系统中,并经过标准化处理进行格式的统一。数据虚拟化的特点是不改变数据存储位置,实时访问。根据Gartner发布的数据管理技术成熟度曲线,数据虚拟化技术已经进入了生产成熟期,相关理论和技术也已经成熟,如果企业正在受困于各系统或者各部门数据无法高效打通的问题,可以考虑采用数据虚拟化技术。
早期的一种数据虚拟化实践是数据库联邦,在不同的数据库之间建立JDBC/ODBC连接的方式,以标准SQL的方式跨数据库进行数据实时访问。这种方式在传统数据库模式下一定程度上解决了跨数据源实时数据访问的问题。但是在大数据时代,数据的存储和访问方式已经完全不同,每种数据处理组件只解决一个特定的场景问题,具有不同的数据存储方式、组织方式和访问方式。如Hdoop用于解决大规模数据的批量计算,Hbase用于海量数据的实时精确检索,ElasticSearch用于海量数据的综合检索,还有MPP数据库、图数据库、内存数据库、时序数据库等等,百花齐放,百家争鸣,共同形成了大数据时代的数据处理技术栈,解决各个场景下的大规模数据处理问题。在实际的应用中,为了满足业务不同维度的需求,往往在同一个业务中同时使用了不同的处理组件,甚至是分布在不同地域的不同数据处理组件,造成了业务复杂度高,数据冗余,访问效率低等问题。
大数据时代的数据虚拟化技术就是要解决这种跨源跨域场景下的数据高效访问问题,以一种统一的接口,接近原生系统的性能,跨地域的方式进行数据访问。而要满足上述要求,一个数据虚拟化产品需要具备下面的四个功能:
- 统一元数据管理。具备全局数据的统一视图,包括数据承载的组件、数据的Schema、数据存储的格式、存储位置等。
- 抽象数据访问层。提供数据访问的抽象层,屏蔽不同数据源的接口差异,在访问层以一种统一的接口面向应用层。
- 统一的安全管控。全局统一安全管控策略,所有数据的访问在安全管控的框架下进行,避免数据越权访问。
- 多源结果集合并。来自不同集群,不同组件的结果数据可以关联、合并,以一个完整的结果集返回给应用层。
华为MRS云原生数据湖平台的HetuEngine就是一款解决大数据时代跨源跨域问题的数据虚拟化引擎。如下图是MRS云原生数据湖平台基于HetuEngine构建的逻辑数据湖平台架构。HetuEngine可以跨Hadoop平台、MPP数据库、数据集市(包括Hbase、ElasticSearch、Clickhouse等)进行跨源访问,并提供统一的SQL接口供上层应用进行数据访问。HetuEngine还支持跨集群数据访问,实现高性能的跨数据湖、数据仓库、数据集市的分析查询。适用多个数据湖或者数据平台联合分析,支持用户间资源隔离,支持全局数据权限管理。
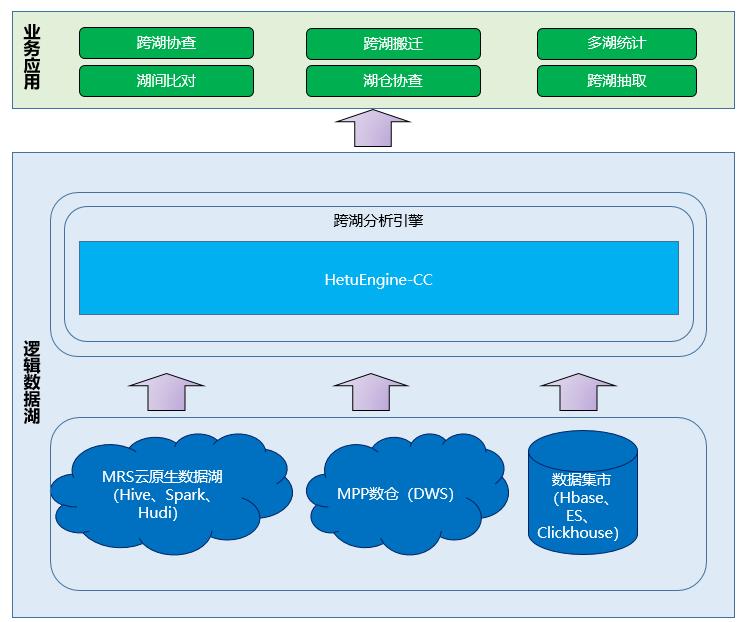
现在,HetuEngine已经帮助众多政企客户解决了在大数据场景下面临的用数难,取数难的问题。某大型国企就利用了HetuEngine的跨域分析能力解决了困扰其很长时间的全域数据实时访问的问题。
该大型国企有众多下属省公司,分布在全国各地,每个省公司都建设有自己的数据湖平台,用于支撑省公司内部的数字业务。各省公司每天要将自己的数据上报给集团公司,集团公司再对全国数据进行统一汇总加工处理,用于支撑集团层面的业务决策。这种方式面临以下几个问题:(1)数据上报不完整。由于带宽限制,只能上报部分结果数据,无法将全部的明细数据上报,部分需要明细数据的业务无法在集团层面开展。(2)数据上报延迟。子公司将数据加工后,分批上报集团公司,数据延迟在小时级别,无法支撑集团实时业务的开展。(3)资源投入太大。随着业务的发展,集团需要的数据越来越多,资源池原来越大,投入和产出无法匹配。(4)数据需求响应不及时。新的数据需求只能通过对分公司提数据需求,重新开发数据流程上报的方式满足,效率太低,无法支撑业务的时效性需求。
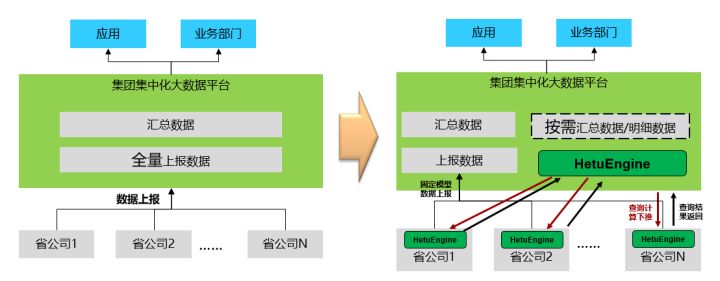
如上图所示,在旧模式下,所有的数据只能通过定时上报的方式收集到集团集中化大数据平台,再进行分析,供上层业务使用。引入HetuEngine后,上报的数据只是每天固定模型加工的数据,明细数据和临时汇总数据均可以通过HetuEngine进行实时的查询。通过HetuEngine不仅实现了高效的实时数据查询,还可以通过HetuEngine进行跨省公司的数据关联分析,打破了省公司之间的数据墙,大大提高了跨域数据分析的效率。
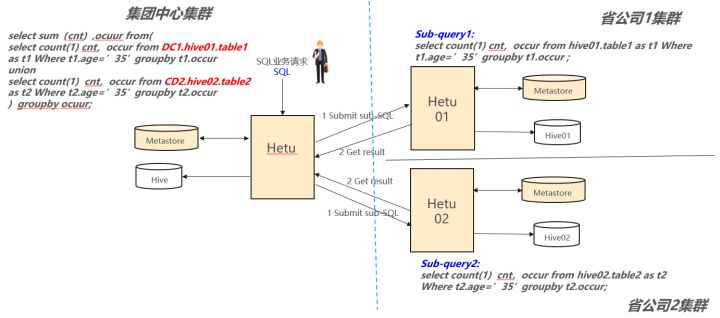
HetuEgine通过自己的跨域查询引擎,可以将一个复杂的跨域查询任务根据数据所在的位置将查询下发到数据所在的集群执行,充分利用边缘集群的算力,提高数据分析的效率和整体的资源利用率。如下图的一个场景,要统计年龄为35岁,在两个省同时开户的用户。可以通过一个SQL同时查询两个省公司的数据。HetuEngine将这个SQL下推到两个省公司集群执行,并将执行结果返回给集团公司进行统一汇总,直接向业务层返回最终的汇总结果。整个过程都是自动实时的进行,并且充分利用了边缘集群的算力,集团公司只需要消耗少量的带宽和算力就完成了整个计算过程。
HetuEngine在跨域场景下也充分考虑了整个计算过程的可靠性和安全性。数据访问遵循统一的安全管控模型,对远程数据访问进行细粒度的管控。数据传输过程采用加密传输,保障数据传输过程中的安全。考虑到跨地域的查询通常是传输带宽受限的场景,HetuEngine支持流量管控,防止由于查询结果集过大导致占满传输带宽,影响其他业务。此外,HetuEngine还综合采用了抗网络抖动、断点续传、压缩传输、级联查询等手段提高跨域查询的稳定性和效率。
最终,借助HetuEngine提供的数据虚拟化能力,该集团公司打造了一套高效的全域数据统一查询分析平台。首先,实现了全域数据在集团层面真正的统一,利用HetuEngine可随时访问集团所有省公司的数据。其次,减少了集团公司集群的压力,将大量的数据分析任务下发给省公司集群完成,充分利用省公司边缘集群的算力。然后,提高端到端的数据访问时延,数据由之前的小时级的延迟到现在可以秒级查询省公司集群数据。最后,借助HetuEgine跨源跨域查询能力,可以直接将分布在不同省不同存储组件中的数据在HetuEngine中进行关联分析,打破了数据之间的隔离,带来了很多新的数据应用场景,进一步挖掘了数据的价值。
以上是关于MRS HetuEgine的数据虚拟化实践的主要内容,如果未能解决你的问题,请参考以下文章
FusionInsight MRS Flink DataStream API读写Hudi实践