图解大数据 | 基于Spark RDD的大数据处理分析
Posted ShowMeAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解大数据 | 基于Spark RDD的大数据处理分析相关的知识,希望对你有一定的参考价值。
 RDD(弹性分布式数据集合)是Spark的基本数据结构,Spark中的所有数据都是通过RDD的形式进行组织。本文讲解RDD的属性、创建方式、广播与累加器等重要知识点,并图解RDD高频算子。
RDD(弹性分布式数据集合)是Spark的基本数据结构,Spark中的所有数据都是通过RDD的形式进行组织。本文讲解RDD的属性、创建方式、广播与累加器等重要知识点,并图解RDD高频算子。

作者:韩信子@ShowMeAI
教程地址:http://www.showmeai.tech/tutorials/84
本文地址:http://www.showmeai.tech/article-detail/174
声明:版权所有,转载请联系平台与作者并注明出处
1.RDD介绍
要掌握基于Spark的大数据处理操作,大家首先要了解Spark中的一个核心数据概念:RDD。
1)RDD介绍
RDD,全称为Resilient Distributed Datasets(弹性分布式数据集合),是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。

RDD(弹性分布式数据集合)是Spark的基本数据结构,Spark中的所有数据都是通过RDD的形式进行组织。
- RDD是不可变的数据集合,每个分区数据是只读的。
- RDD数据集要做逻辑分区(类似hadoop中的逻辑切片split),每个分区可以单独在集群节点进行计算。
- RDD数据集中的数据类型可以包含任何java类型、scala类型、python类型或者自定义的类型。
- RDD擅长的领域:迭代式的数据处理,比如机器学习。
2)RDD的5个属性
每个RDD有5个主要的属性:
- 一组分片(partition),数据集的基本组成单位。
- 一个函数,计算每个分片。
- 对parent RDD的依赖,描述RDD之间的lineage。
- 一个Partitioner,对于key-value的RDD。
- 一个列表,存储存取每个partition的preferred位置。例如对于一个HDFS文件来说,存储每个partition所在的块的位置。

3)RDD与Spark任务
在Spark分布式数据处理任务中,RDD提供数据,供任务处理。很多时候hadoop和Spark结合使用:hadoop提供hdfs的分布式存储,Spark处理hdfs中的数据。
我们以 sc.textFile("hdfs://path/to/file") 形式生成RDD时,Spark就已经算好了数据的各个切片(也叫分区),并把分区信息放在了一个列表(名单)里,这个名单就属于RDD自带的其中一个属性。
-
RDD不包含实际要处理的数据,而是在RDD中的分区名单中载明切片的信息。
-
数据已经在Hadoop的数据节点上了,只要在RDD中标明分区对应的数据所在位置、偏移量、数据长度即可,就类似元数据。
RDD在被分发到每个执行计算的任务节点后,每个任务节点会根据元数据信息获取自身节点负责计算的分区数据,并把数据放到本节点的内存当中,然后对数据进行计算。
- 每个分区由一个节点来计算,换句话说就是每个任务只计算RDD的其中一个分区。
一般我们会把数据所在的节点和Spark的计算节点配成同一个主机,这样就实现了数据本地化。
- 在worker节点将要运行Spark的计算任务时,只需要从本地加载数据,再对数据运用Spark的计算函数,就不需要从别处(例如远程主机)通过网络传输把需要计算的数据拿过来,从而避免了昂贵的网络传输成本。“宁可移动函数,也不要移动数据”。
2.RDD创建方式
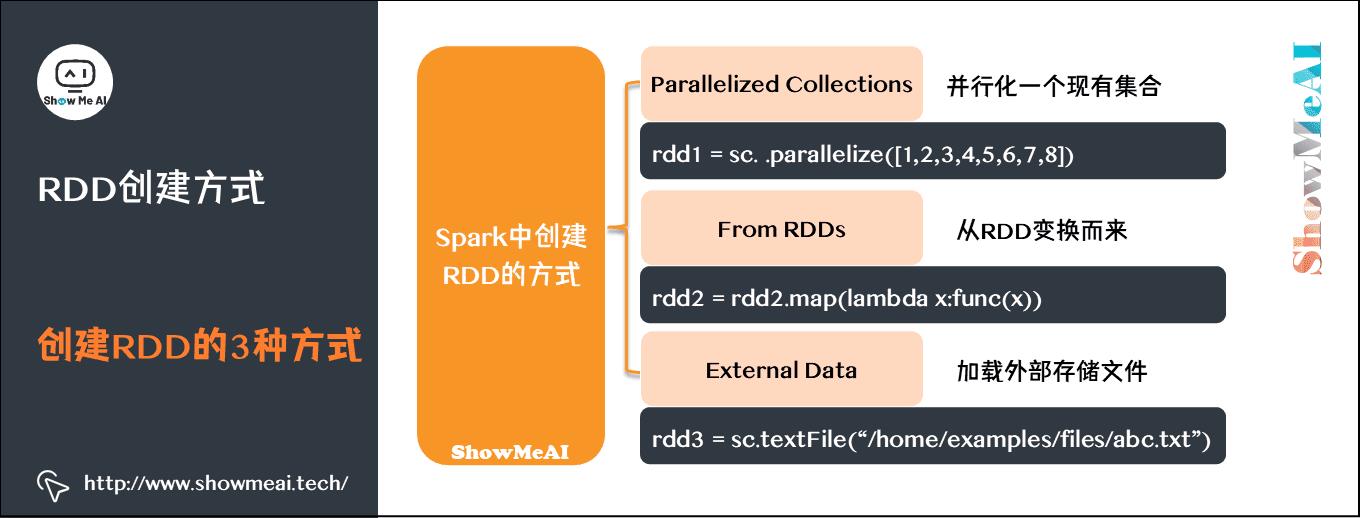
1)创建RDD的3种方式
RDD的3种创建方式如下图所示(以pyspark代码为例):
2)从外部数据创建RDD
spark也支持从多种外部数据源读取数据,包括HDFS、S3、Hbase、MongoDB等,如下图所示:

3.RDD广播与累加器
1)共享变量
在Spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。
这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。
通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:
- 广播变量(broadcast variable)
- 累加器(accumulator)
2)广播变量
为什么要将变量定义成广播变量?

在分布式计算中,由Driver端分发大对象(如字典、集合、黑白名单等),一般,如果这个变量不是广播变量,那么每个task就会分发一份。在task数目十分多的情况下,Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源。
如果将这个变量声明为广播变量,那么知识每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源
3)累加器
为什么要将变量定义为累加器?

在Spark应用程序中,异常监控、调试、记录符合某特性的数据数目,这些需求都需要用到计数器。
如果变量不被声明为累加器,那么被改变时不在Driver端进行全局汇总。即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值。
但是,当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
4.RDD transformation与action
要对大数据进行处理,我们需要使用到一系列Spark RDD上可以变换与操作的算子,我们来重点理解一下spark的RDD transformation和action。
1)transformation与action

transformation操作针对已有的RDD创建一个新的RDD。
- 例如,map就是一种transformation操作。它用于将已有RDD的每个元素传入一个自定义的函数,并获取一个新的元素,然后将所有新元素组成一个新的RDD。
action主要是对RDD进行最后的操作(如遍历、reduce、保存到文件等),并可以返回结果给Driver程序。
- 例如,reduce就是一种action操作。它用于对RDD中的所有元素进行聚合操作,并获取一个最终的结果,然后返回给Driver程序。

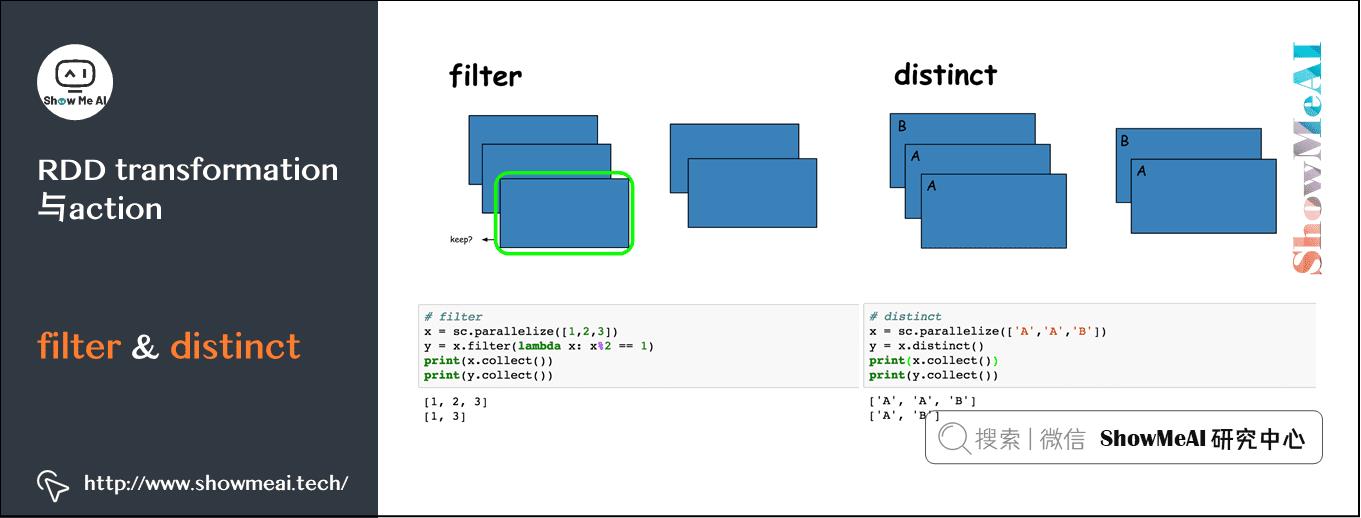
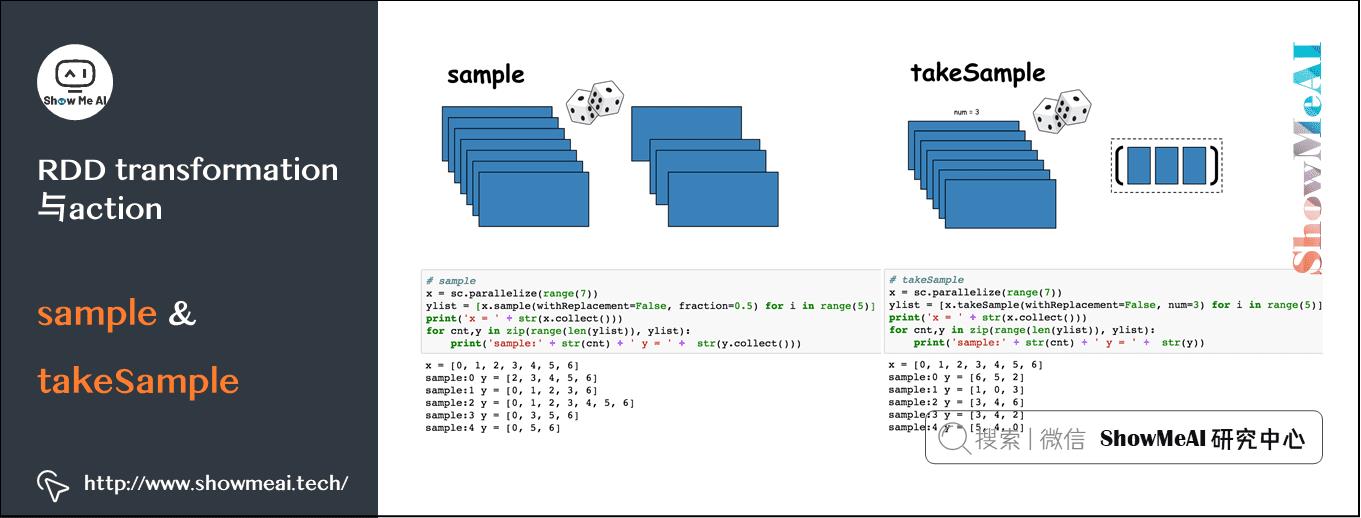
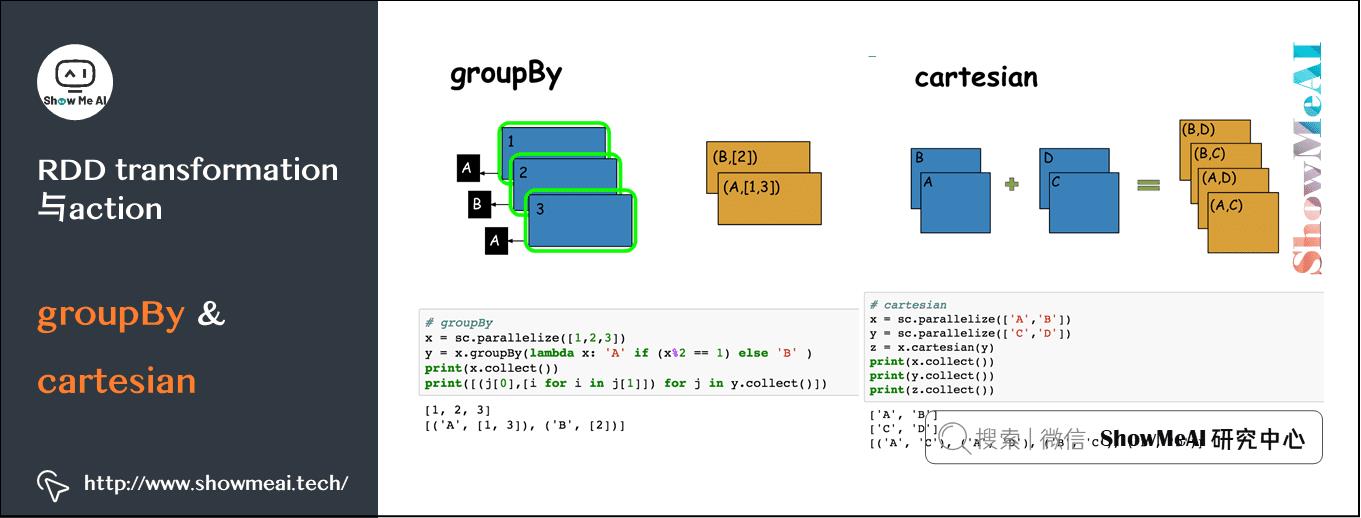
2)高频RDD算子图解
map与flatMap

filter与distinct
sort与sortBy

sample与takeSample
union与intersection

groupby与cartesian
join与glom

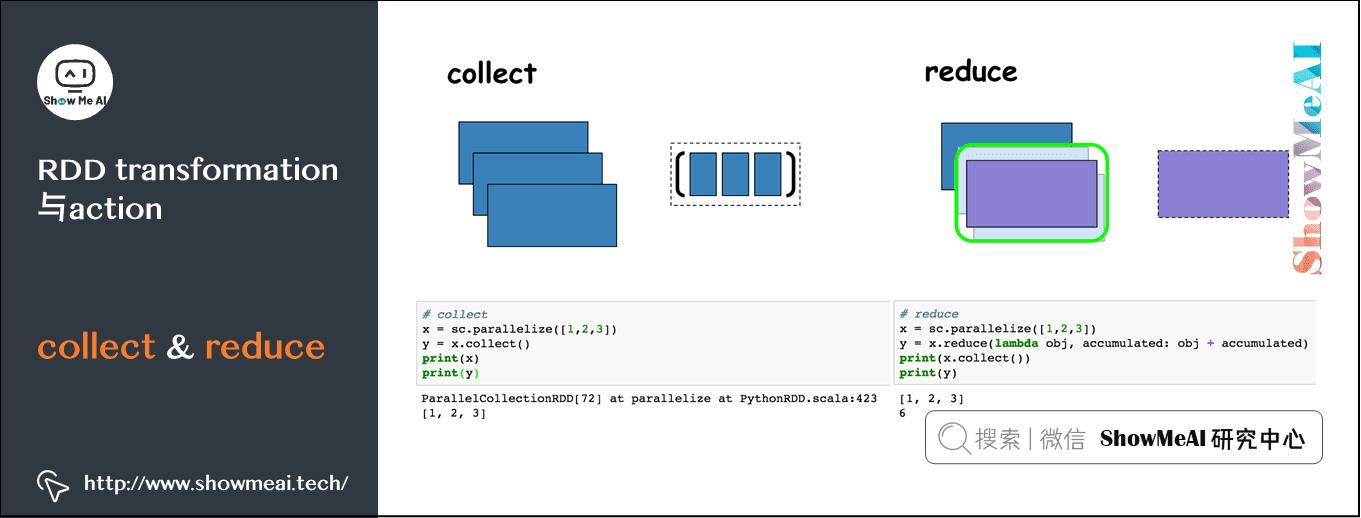
collect与reduce
top与count

takeOrdered与take

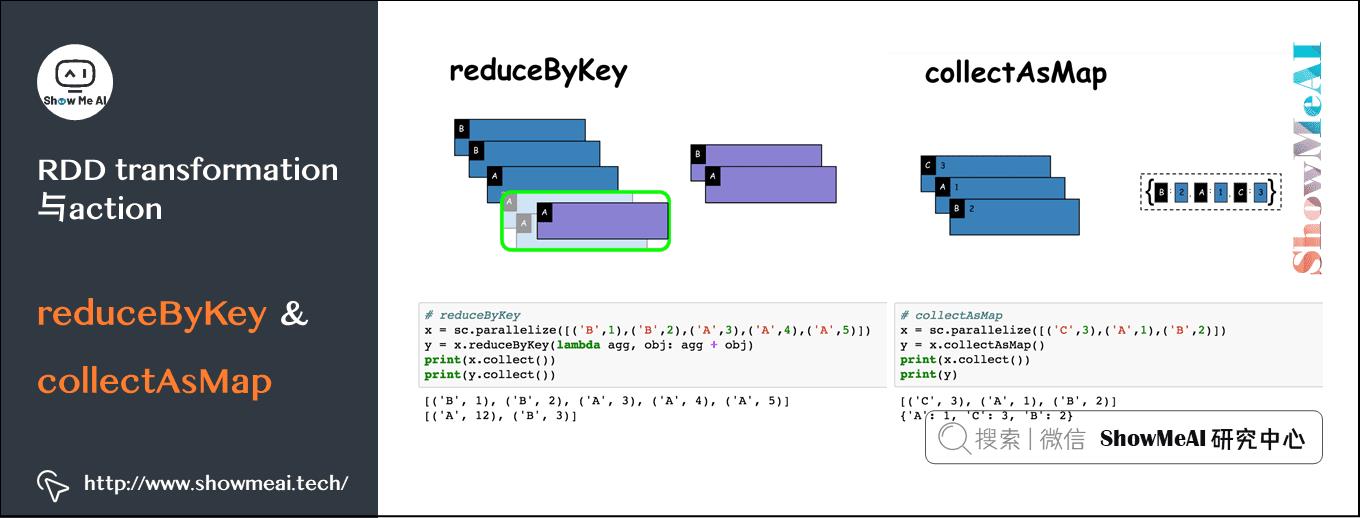
reduceByKey与collectAsMap
5.参考资料
- 数据科学工具速查 | Spark使用指南(RDD版) http://www.showmeai.tech/article-detail/106
- 数据科学工具速查 | Spark使用指南(SQL版) http://www.showmeai.tech/article-detail/107
- 耿嘉安,Spark内核设计的艺术:架构设计与实现, 机械工业出版社,2018
- 郭景瞻,图解Spark:核心技术与案例实战,电子工业出版社
- Spark的基本数据结构RDD介绍: https://blog.csdn.net/qq_31598113/article/details/70832701
- Spark RDD(Resilient Distributed Datasets)论文:http://spark.apachecn.org/paper/zh/spark-rdd.html
ShowMeAI相关文章推荐
- 图解大数据 | 导论:大数据生态与应用
- 图解大数据 | 分布式平台:Hadoop与Map-reduce详解
- 图解大数据 | 实操案例:Hadoop系统搭建与环境配置
- 图解大数据 | 实操案例:应用map-reduce进行大数据统计
- 图解大数据 | 实操案例:Hive搭建与应用案例
- 图解大数据 | 海量数据库与查询:Hive与HBase详解
- 图解大数据 | 大数据分析挖掘框架:Spark初步
- 图解大数据 | Spark操作:基于RDD的大数据处理分析
- 图解大数据 | Spark操作:基于Dataframe与SQL的大数据处理分析
- 图解大数据 | 综合案例:使用spark分析美国新冠肺炎疫情数据
- 图解大数据 | 综合案例:使用Spark分析挖掘零售交易数据
- 图解大数据 | 综合案例:使用Spark分析挖掘音乐专辑数据
- 图解大数据 | 流式数据处理:Spark Streaming
- 图解大数据 | Spark机器学习(上)-工作流与特征工程
- 图解大数据 | Spark机器学习(下)-建模与超参调优
- 图解大数据 | Spark GraphFrames:基于图的数据分析挖掘
ShowMeAI系列教程推荐

以上是关于图解大数据 | 基于Spark RDD的大数据处理分析的主要内容,如果未能解决你的问题,请参考以下文章