Spark介绍及基于YARN模式的Spark集群部署
Posted Hsia运维笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark介绍及基于YARN模式的Spark集群部署相关的知识,希望对你有一定的参考价值。
Spark最初由美国加州伯克利大学的AMP实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。
Spark基本概念
RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系;Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据;应用:用户编写的Spark应用程序;任务:运行在Executor上的工作单元;作业:一个作业包含多个RDD及作用于相应RDD上的各种操作;阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”。
Spark主要特点:
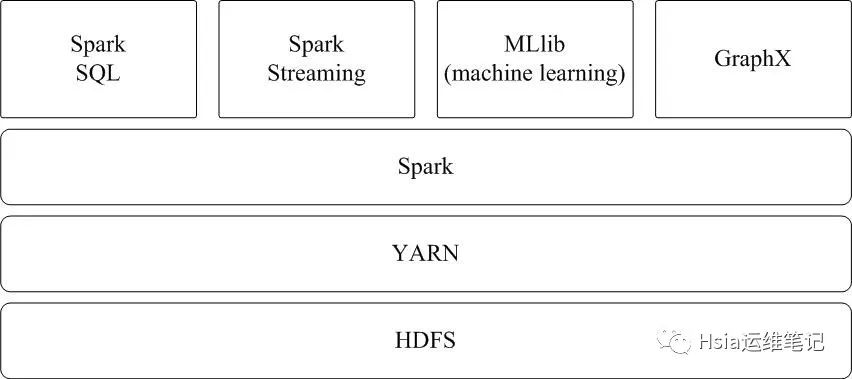
运行速度快:Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;容易使用:Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程;通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;运行模式多样:Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
Spark结构设计:
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
Spark各种概念之间的关系:
在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
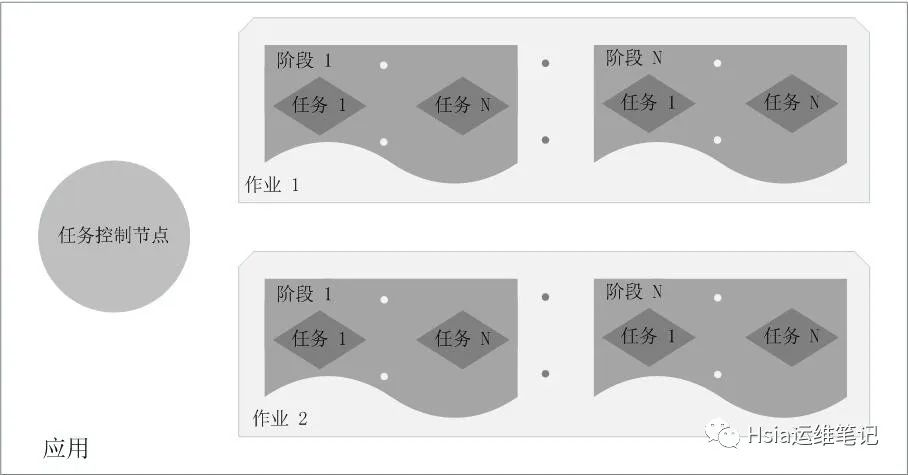
Executor的优点:
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:1.利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动开销;2.Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到HDFS等文件系统里,因而有效减少了IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写IO性能。
Spark的基本运行流程:
1.当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源;2.资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上;3.SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor;4.任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
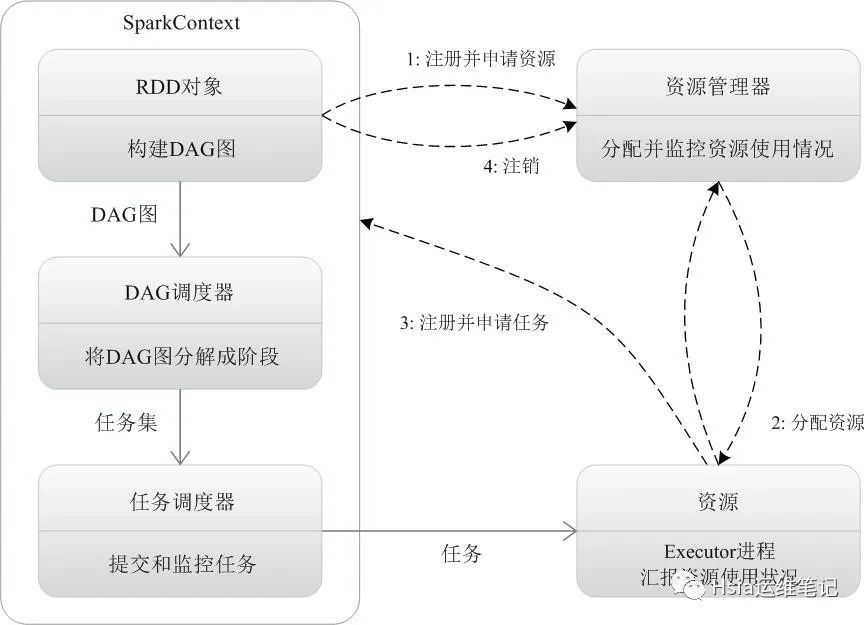
Spark三种部署方式
Spark应用程序在集群上部署运行时,可以由不同的组件为其提供资源管理调度服务(资源包括CPU、内存等)。比如,可以使用自带的独立集群管理器(standalone),或者使用YARN,也可以使用Mesos。因此,Spark包括三种不同类型的集群部署方式,包括standalone、Spark on Mesos和Spark on YARN。
1.standalone模式
与MapReduce1.0框架类似,Spark框架本身也自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。在架构的设计上,Spark与MapReduce1.0完全一致,都是由一个Master和若干个Slave构成,并且以槽(slot)作为资源分配单位。不同的是,Spark中的槽不再像MapReduce1.0那样分为Map 槽和Reduce槽,而是只设计了统一的一种槽提供给各种任务来使用。
2.Spark on Mesos模式
Mesos是一种资源调度管理框架,可以为运行在它上面的Spark提供服务。Spark on Mesos模式中,Spark程序所需要的各种资源,都由Mesos负责调度。由于Mesos和Spark存在一定的血缘关系,因此,Spark这个框架在进行设计开发的时候,就充分考虑到了对Mesos的充分支持,因此,相对而言,Spark运行在Mesos上,要比运行在YARN上更加灵活、自然。目前,Spark官方推荐采用这种模式,所以,许多公司在实际应用中也采用该模式。
3.Spark on YARN模式
Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,其架构如xia图所示,资源管理和调度依赖YARN,分布式存储则依赖HDFS。
SPARK on YARN 模式集群部署
集群环境:3节点 master slave1 slave2master负责任务的分发,与集群状态的显示slaves运行具体的Worker任务,最后交由Executor执行任务代码集群搭建之前,必须满足如下条件:1、集群主机名和hosts文件映射一一对应[root@master zookeeper-3.4.5]# cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4192.168.10.10 master192.168.10.11 slave1192.168.10.12 slave22、集群ssh免密登录配置3、集群每个节点防火墙、selinux关闭4、JDK正确安装[root@master zookeeper-3.4.5]# java -versionjava version "1.8.0_171"Java(TM) SE Runtime Environment (build 1.8.0_171-b11)Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)5、Scala正确安装[root@master zookeeper-3.4.5]# scalaWelcome to Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171).Type in expressions to have them evaluated.Type :help for more information.scala>6、Hadoop集群安装,因为Spark存储层要用到HDFS,所以应该至少保证HDFS服务的正常运行,hadoop集群可以在yarn上,也可以由zookeeper协调,这个都没问题,最重要的是hadoop集群能正常运行。
spark版本:spark-1.6.3-bin-hadoop2.6hadoop版本:hadoop-2.6.5zookeeper版本:zookeeper-3.4.5
hadoop配置修改
修改hadoop配置文件yarn-site.xml
[root@master sbin]# vim /usr/local/src/hadoop-2.6.5/etc/hadoop/yarn-site.xml<property><!--是否启动一个线程检查任务使用的虚拟内存量,如超过分配值则会被中断,默认true--><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description>Whether virtual memory limits will be enforced for containers</description></property><property><!--是否启动一个线程检查任务使用的物理内存量,如超过分配值则会被中断,默认true--><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value><description>Whether phyical memory limits will be enforced for containers</description></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>4</value><description>Ratio between virtual memory to physical memory when setting memory limits for containers</description></property>
//主要是为了确保在基于yarn调度spark任务的时候,不会因为刚开始分配的资源不足导致任务中断或被拒绝。
分发hadoop配置文件到slave1和slave2节点
[root@master hadoop]# scp yarn-site.xml slave1:/usr/local/src/hadoop-2.6.5/etc/hadoop/[root@master hadoop]# scp yarn-site.xml slave2:/usr/local/src/hadoop-2.6.5/etc/hadoop/
//需要重启hadoop服务生效
[root@master zookeeper-3.4.5]# cd /usr/local/src/hadoop-2.6.5/sbin/[root@master sbin]# ./stop-all.sh[root@master sbin]# ./start-all.sh
spark配置修改
修改spark配置文件spark-env.sh,新增如下
[root@master sbin]# vim /usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/spark-env.shexport JAVA_HOME=/usr/local/src/jdk1.8.0_152export SCALA_HOME=/usr/local/src/scala-2.10.5export HADOOP_HOME=/usr/local/src/hadoop-2.6.5export HADOOP_CONF_DIR=/usr/local/src/hadoop-2.6.5/etc/hadoopexport YARN_CONF_DIR=/usr/local/src/hadoop-2.6.5/etc/hadoopexport SPARK_HOME=/usr/local/src/spark-1.6.3-bin-hadoop2.6export SPARK_MASTER_IP=192.168.10.10export SPARK_MASTER_HOST=192.168.10.10export SPARK_LOCAL_IP=192.168.10.10export SPARK_WORKER_MEMORY=1gexport SPARK_WORKER_CORES=1export SPARK_DIST_CLASSPATH=$(${HADOOP_HOME}/bin/hadoop classpath)
//yarn作为hadoop组件,对于基于yarn部署的spark集群,任务资源 是yarn分配的,添加上面配置是为了让spark发现并读取hadoop相关配置
修改slaves文件,本文同时将master作为worker节点提供服务,生产中则不建议
[root@master sbin]# vim /usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/slavesmasterslave1slave2
分发spark配置文件spark-env.sh和slaves到slave1和slave2节点
[root@master sbin]# scp ../conf/spark-env.sh slave1:/usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/[root@master sbin]# scp ../conf/spark-env.sh slave2:/usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/[root@master sbin]# scp ../conf/slaves slave1:/usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/[root@master sbin]# scp ../conf/slaves slave2:/usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/
部署spark的历史服务history server
编辑spark-defaults.conf文件新增内容
[root@master conf]# more spark-defaults.conf#开启历史任务spark.eventLog.enabled true#分布式运行任务,日志存放目录,需要共享存储目录spark.eventLog.dir hdfs://master:9000/logs/spark#开启历史日志压缩spark.eventLog.compress true
在hdfs中创建/logs/spark目录,不然spark.eventLog.dir属性不会生效
[root@master conf]# hadoop fs -mkdir -p /logs/spark在spark-env.sh文件添加配置SPARK_HISTORY_OPTS
[root@master conf]# vim /usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/spark-env.shexport SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://master:9000/logs/spark \-Dspark.history.retained-Applications=3 -Dspark.history.ui.port=4000"
-Dspark.history.retained-Applications=3表示内存中允许存放日志个数3个,超过则会将旧日志从内存删除,但不会从hdfs中删除-Dspark.history.fs.logDirectory表示告诉history server哪个目录存放着任务的日志信息
分发配置文件到到slave1和slave2节点
[root@master conf]# pwd/usr/local/src/spark-1.6.3-bin-hadoop2.6/conf[root@master conf]# scp spark-defaults.conf slave1:/usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/[root@master conf]# scp spark-defaults.conf slave2:/usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/[root@master conf]# scp spark-env.sh slave1:/usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/
启动spark历史服务
[root@master conf]# cd -/usr/local/src/spark-1.6.3-bin-hadoop2.6/sbin[root@master sbin]# ./start-all.shstarting org.apache.spark.deploy.master.Master, logging to /usr/local/src/spark-1.6.3-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.outslave2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark-1.6.3-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.outslave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark-1.6.3-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.out[root@master sbin]# ./start-history-server.shstarting org.apache.spark.deploy.history.HistoryServer, logging to /usr/local/src/spark-1.6.3-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-master.out
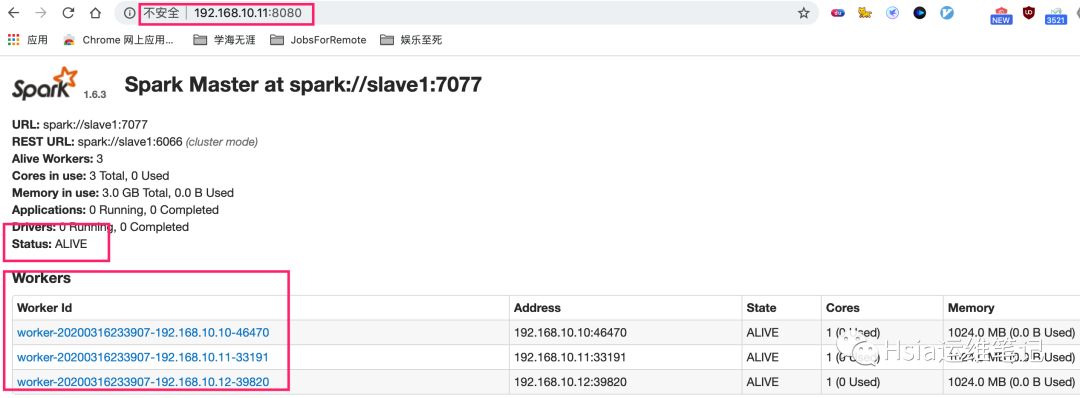
spark集群查看
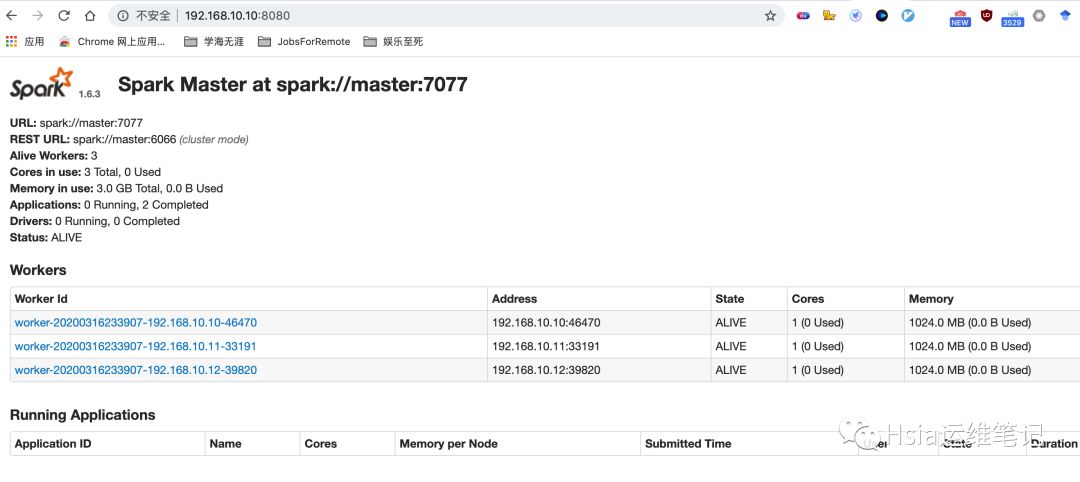
spark历史服务查看
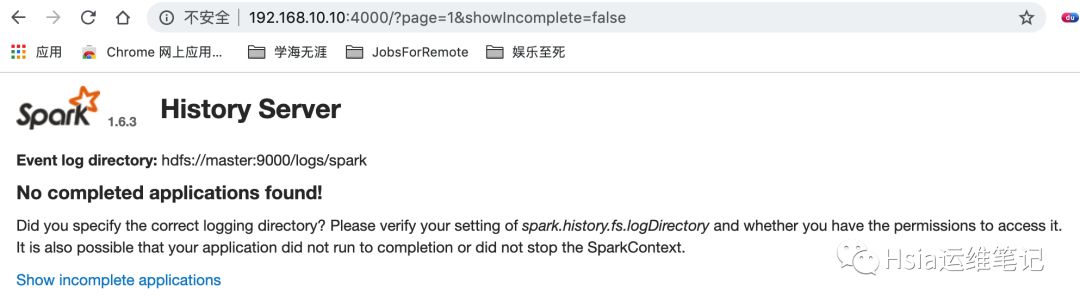
ops!!不要怕 !!!
!!!
其实这个没有问题,是因为现在没有执行任何任务,所以页面中不会有任务记录~~~
目前为止基于yarn模式的spark集群已经部署完成,但是有个小问题,master服务并非高可用,容易产生单点故障,生产中最好部署高可用的master服务
spark集群配置高可用master服务
高可用依赖部署zookeeper,zookeeper集群搭建过程暂略
修改spark-env.sh,注释SPARK_MASTER_IP,SPARK_MASTER_HOST,SPARK_LOCAL_IP
#export SPARK_MASTER_IP=192.168.10.10#export SPARK_MASTER_HOST=192.168.10.10#export SPARK_LOCAL_IP=192.168.10.10
新增SPARK_DAEMON_JAVA_OPTS
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/spark"-Dspark.deploy.recoveryMode=ZOOKEEPER 代表发生故障使用zookeeper服务
-Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 zookeeper集群节点
-Dspark.deploy.zookeeper.dir=/spark spark要在zookeeper上写数据时的保存目录
重新分发配置文件到slave1和slave2节点
[root@master conf]# scp spark-env.sh slave2:/usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/[root@master conf]# scp spark-env.sh slave1:/usr/local/src/spark-1.6.3-bin-hadoop2.6/conf/
master上重启spark和history服务
[root@master sbin]# ./stop-all.sh[root@master sbin]# ./stop-history-server.sh[root@master sbin]# ./start-all.shstarting org.apache.spark.deploy.master.Master, logging to /usr/local/src/spark-1.6.3-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.outslave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark-1.6.3-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.outslave2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark-1.6.3-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.out[root@master sbin]# ./start-history-server.shstarting org.apache.spark.deploy.history.HistoryServer, logging to /usr/local/src/spark-1.6.3-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-master.out[root@master sbin]# jps7841 QuorumPeerMain11923 SecondaryNameNode12469 Master12645 Jps12072 ResourceManager12585 HistoryServer11742 NameNode
查看日志,启动成功
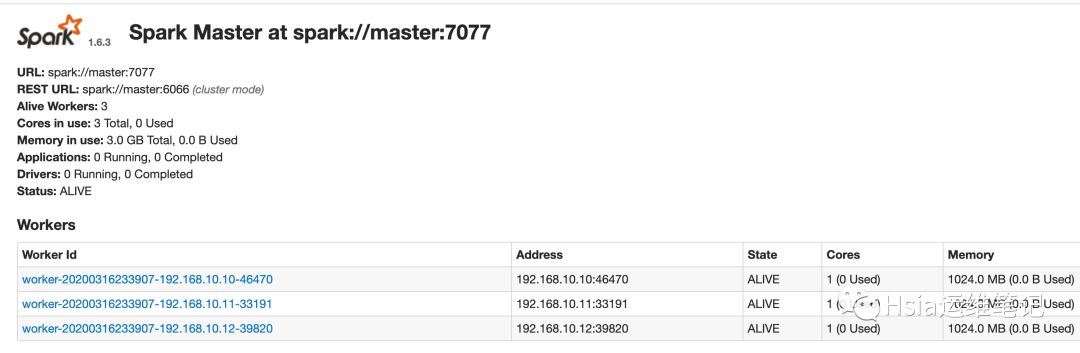
UI界面查看,ALIVE表示处于活跃状态
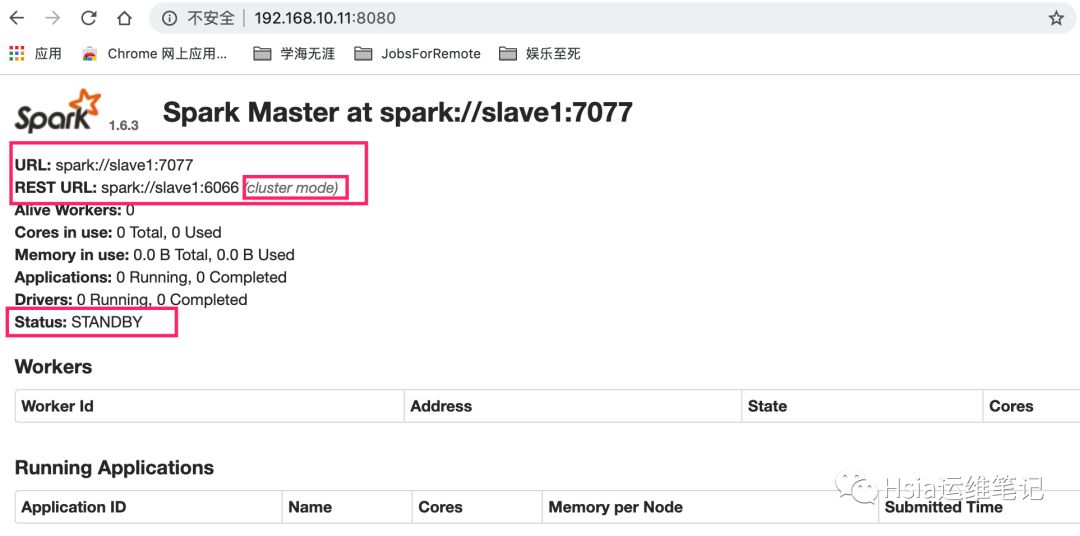
slave1再单独启动Spark master
[root@slave1 sbin]# ./start-master.sh UI界面查看查看,可以看到standby,salve1已处于待命状态
模拟master宕机,停掉master节点的master服务
[root@master sbin]# jps7841 QuorumPeerMain11923 SecondaryNameNode13493 Worker13366 Master12072 ResourceManager13613 HistoryServer11742 NameNode13758 Jps[root@master sbin]# ./stop-master.shstopping org.apache.spark.deploy.master.Master
再次访问slave1 http://192.168.10.11:8080/,可以看到slave1的master服务会变成alive状态,集群状态正常
yarn模式的spark特点 就是依赖hadoop的yarn组件,由yarn调度可以方便集中地管理集群的计算资源。
简单测试,standlone模式求Pi的值
[root@master sbin]# spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://master:7077 \--executor-memory 1G \--total-executor-cores 2 \/usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/spark-examples-1.6.3-hadoop2.6.0.jar 10--class 表示入口类--total-executor-cores 集群中一共可以调度cpu内核,一个cpu同一时间只能运行一个任务。--executor-memory 灭一个executor进程的可用内存
[root@master sbin]# spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 1G --total-executor-cores 2 /usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/spark-examples-1.6.3-hadoop2.6.0.jar 10SLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/spark-assembly-1.6.3-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]20/03/16 23:56:54 INFO spark.SparkContext: Running Spark version 1.6.320/03/16 23:56:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable20/03/16 23:56:55 INFO spark.SecurityManager: Changing view acls to: root20/03/16 23:56:55 INFO spark.SecurityManager: Changing modify acls to: root20/03/16 23:56:55 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)20/03/16 23:56:55 INFO util.Utils: Successfully started service 'sparkDriver' on port 35426.20/03/16 23:56:56 INFO slf4j.Slf4jLogger: Slf4jLogger started20/03/16 23:56:56 INFO Remoting: Starting remoting20/03/16 23:56:56 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.10.10:38154]20/03/16 23:56:56 INFO util.Utils: Successfully started service 'sparkDriverActorSystem' on port 38154.20/03/16 23:56:56 INFO spark.SparkEnv: Registering MapOutputTracker20/03/16 23:56:56 INFO spark.SparkEnv: Registering BlockManagerMaster20/03/16 23:56:56 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-4353a42e-8fe1-4e83-ab5b-f47307b0602320/03/16 23:56:56 INFO storage.MemoryStore: MemoryStore started with capacity 511.1 MB20/03/16 23:56:56 INFO spark.SparkEnv: Registering OutputCommitCoordinator20/03/16 23:56:56 INFO server.Server: jetty-8.y.z-SNAPSHOT20/03/16 23:56:56 INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:404020/03/16 23:56:56 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.20/03/16 23:56:56 INFO ui.SparkUI: Started SparkUI at http://192.168.10.10:404020/03/16 23:56:56 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-f5ee342d-03b8-4108-9485-451393ceb1ac/httpd-a397d136-5ced-4524-b0b0-14c3616a365220/03/16 23:56:56 INFO spark.HttpServer: Starting HTTP Server20/03/16 23:56:56 INFO server.Server: jetty-8.y.z-SNAPSHOT20/03/16 23:56:56 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:3888720/03/16 23:56:56 INFO util.Utils: Successfully started service 'HTTP file server' on port 38887.20/03/16 23:56:56 INFO spark.SparkContext: Added JAR file:/usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/spark-examples-1.6.3-hadoop2.6.0.jar at http://192.168.10.10:38887/jars/spark-examples-1.6.3-hadoop2.6.0.jar with timestamp 158437421694520/03/16 23:56:57 INFO client.AppClient$ClientEndpoint: Connecting to master spark://master:7077...20/03/16 23:56:57 INFO cluster.SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20200316235657-000120/03/16 23:56:57 INFO client.AppClient$ClientEndpoint: Executor added: app-20200316235657-0001/0 on worker-20200316233907-192.168.10.10-46470 (192.168.10.10:46470) with 1 cores20/03/16 23:56:57 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20200316235657-0001/0 on hostPort 192.168.10.10:46470 with 1 cores, 1024.0 MB RAM20/03/16 23:56:57 INFO client.AppClient$ClientEndpoint: Executor added: app-20200316235657-0001/1 on worker-20200316233907-192.168.10.12-39820 (192.168.10.12:39820) with 1 cores20/03/16 23:56:57 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20200316235657-0001/1 on hostPort 192.168.10.12:39820 with 1 cores, 1024.0 MB RAM20/03/16 23:56:57 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 36583.20/03/16 23:56:57 INFO netty.NettyBlockTransferService: Server created on 3658320/03/16 23:56:57 INFO storage.BlockManagerMaster: Trying to register BlockManager20/03/16 23:56:57 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.10.10:36583 with 511.1 MB RAM, BlockManagerId(driver, 192.168.10.10, 36583)20/03/16 23:56:57 INFO storage.BlockManagerMaster: Registered BlockManager20/03/16 23:56:57 INFO client.AppClient$ClientEndpoint: Executor updated: app-20200316235657-0001/0 is now RUNNING20/03/16 23:56:57 INFO client.AppClient$ClientEndpoint: Executor updated: app-20200316235657-0001/1 is now RUNNING20/03/16 23:56:59 INFO scheduler.EventLoggingListener: Logging events to hdfs://master:9000/logs/spark/app-20200316235657-0001.snappy20/03/16 23:56:59 INFO cluster.SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.020/03/16 23:57:00 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:3620/03/16 23:57:00 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:36) with 10 output partitions20/03/16 23:57:00 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:36)20/03/16 23:57:00 INFO scheduler.DAGScheduler: Parents of final stage: List()20/03/16 23:57:00 INFO scheduler.DAGScheduler: Missing parents: List()20/03/16 23:57:00 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32), which has no missing parents20/03/16 23:57:00 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1904.0 B, free 511.1 MB)20/03/16 23:57:00 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1218.0 B, free 511.1 MB)20/03/16 23:57:00 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.10.10:36583 (size: 1218.0 B, free: 511.1 MB)20/03/16 23:57:00 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:100620/03/16 23:57:00 INFO scheduler.DAGScheduler: Submitting 10 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32)20/03/16 23:57:00 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 10 tasks20/03/16 23:57:01 INFO cluster.SparkDeploySchedulerBackend: Registered executor NettyRpcEndpointRef(null) (slave2:35566) with ID 120/03/16 23:57:01 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, slave2, partition 0,PROCESS_LOCAL, 2156 bytes)20/03/16 23:57:01 INFO storage.BlockManagerMasterEndpoint: Registering block manager slave2:39216 with 517.4 MB RAM, BlockManagerId(1, slave2, 39216)20/03/16 23:57:01 INFO cluster.SparkDeploySchedulerBackend: Registered executor NettyRpcEndpointRef(null) (master:59474) with ID 020/03/16 23:57:01 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, master, partition 1,PROCESS_LOCAL, 2156 bytes)20/03/16 23:57:01 INFO storage.BlockManagerMasterEndpoint: Registering block manager master:35928 with 511.1 MB RAM, BlockManagerId(0, master, 35928)20/03/16 23:57:02 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on slave2:39216 (size: 1218.0 B, free: 517.4 MB)20/03/16 23:57:02 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, slave2, partition 2,PROCESS_LOCAL, 2156 bytes)20/03/16 23:57:02 INFO scheduler.TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, slave2, partition 3,PROCESS_LOCAL, 2156 bytes)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1895 ms on slave2 (1/10)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 220 ms on slave2 (2/10)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, slave2, partition 4,PROCESS_LOCAL, 2156 bytes)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 240 ms on slave2 (3/10)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5, slave2, partition 5,PROCESS_LOCAL, 2156 bytes)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 91 ms on slave2 (4/10)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6, slave2, partition 6,PROCESS_LOCAL, 2156 bytes)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 94 ms on slave2 (5/10)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Starting task 7.0 in stage 0.0 (TID 7, slave2, partition 7,PROCESS_LOCAL, 2156 bytes)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 79 ms on slave2 (6/10)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Starting task 8.0 in stage 0.0 (TID 8, slave2, partition 8,PROCESS_LOCAL, 2156 bytes)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Finished task 7.0 in stage 0.0 (TID 7) in 93 ms on slave2 (7/10)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Starting task 9.0 in stage 0.0 (TID 9, slave2, partition 9,PROCESS_LOCAL, 2156 bytes)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Finished task 8.0 in stage 0.0 (TID 8) in 184 ms on slave2 (8/10)20/03/16 23:57:03 INFO scheduler.TaskSetManager: Finished task 9.0 in stage 0.0 (TID 9) in 111 ms on slave2 (9/10)20/03/16 23:57:03 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on master:35928 (size: 1218.0 B, free: 511.1 MB)20/03/16 23:57:05 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 3390 ms on master (10/10)20/03/16 23:57:05 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:36) finished in 4.180 s20/03/16 23:57:05 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool20/03/16 23:57:05 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:36, took 4.770039 sPi is roughly 3.1399991399991420/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/api,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/static,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}20/03/16 23:57:05 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}20/03/16 23:57:05 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.10.10:404020/03/16 23:57:06 INFO cluster.SparkDeploySchedulerBackend: Shutting down all executors20/03/16 23:57:06 INFO cluster.SparkDeploySchedulerBackend: Asking each executor to shut down20/03/16 23:57:06 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!20/03/16 23:57:06 INFO storage.MemoryStore: MemoryStore cleared20/03/16 23:57:06 INFO storage.BlockManager: BlockManager stopped20/03/16 23:57:06 INFO storage.BlockManagerMaster: BlockManagerMaster stopped20/03/16 23:57:06 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!20/03/16 23:57:06 INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.20/03/16 23:57:06 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.20/03/16 23:57:06 INFO spark.SparkContext: Successfully stopped SparkContext20/03/16 23:57:06 INFO util.ShutdownHookManager: Shutdown hook called20/03/16 23:57:06 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-f5ee342d-03b8-4108-9485-451393ceb1ac20/03/16 23:57:06 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-f5ee342d-03b8-4108-9485-451393ceb1ac/httpd-a397d136-5ced-4524-b0b0-14c3616a365220/03/16 23:57:06 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remoting shut down.[root@master sbin]#
88行可以看到 已求得 Pi is roughly 3.13999913999914
历史任务查看,此时也已经有了数据
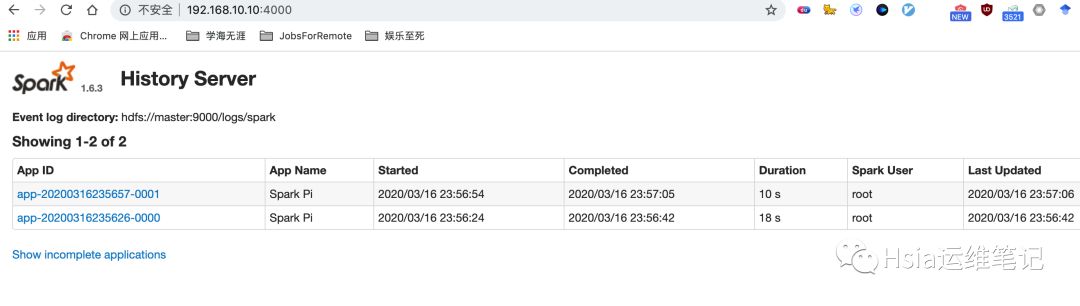
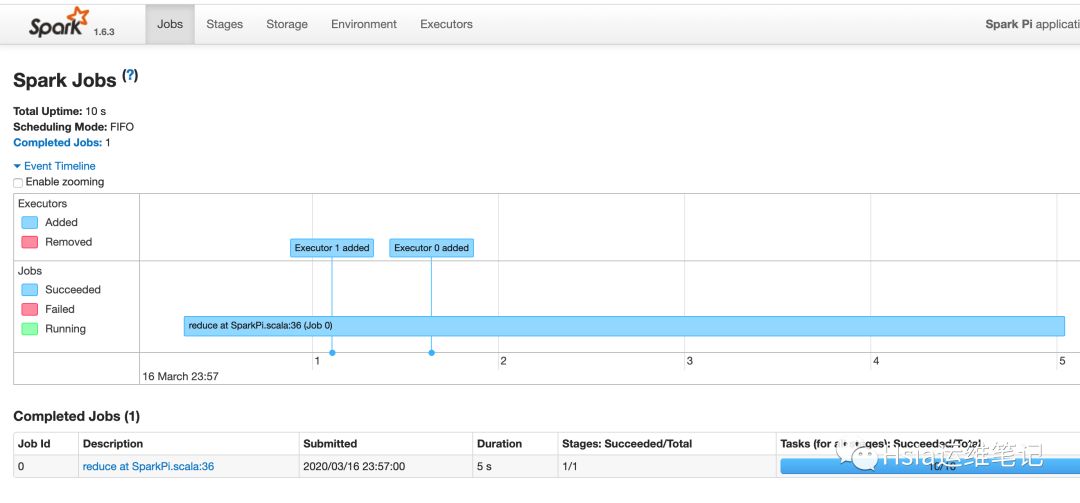
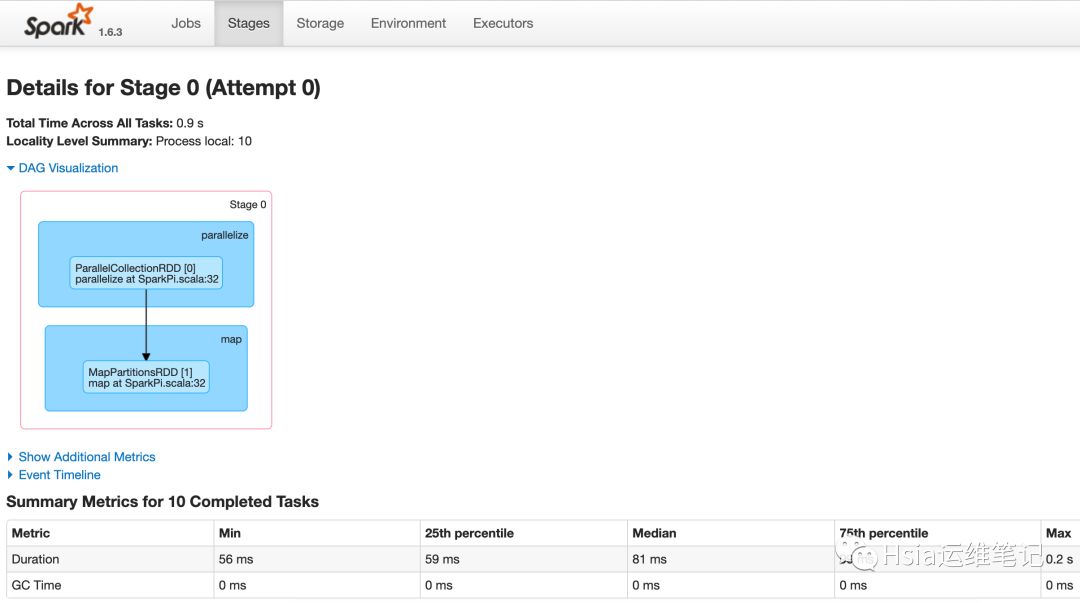
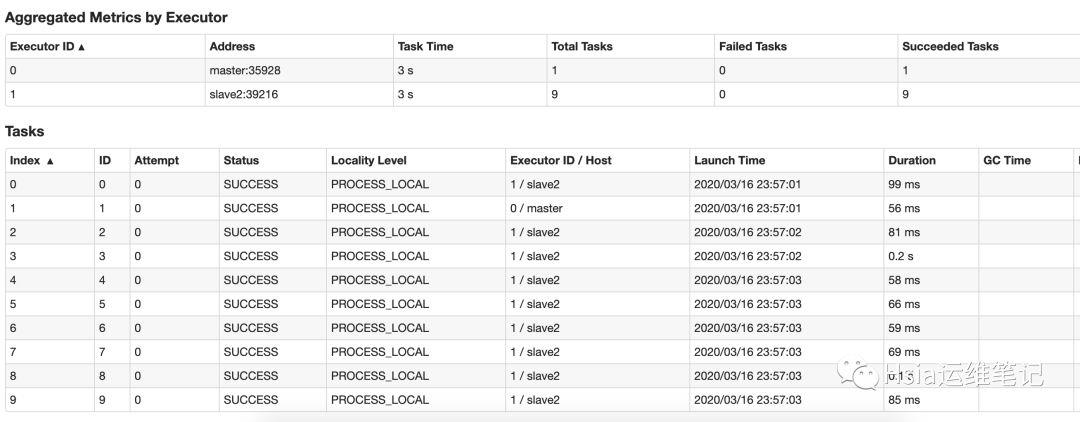
yarn-client模式测试-调试推荐
以client模式连接到yarn集群,该方式driver是在client上运行的。
[root@master sbin]# spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn --deploy-mode=client \--executor-memory 1G --total-executor-cores 2 \/usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/spark-examples-1.6.3-hadoop2.6.0.jar 10
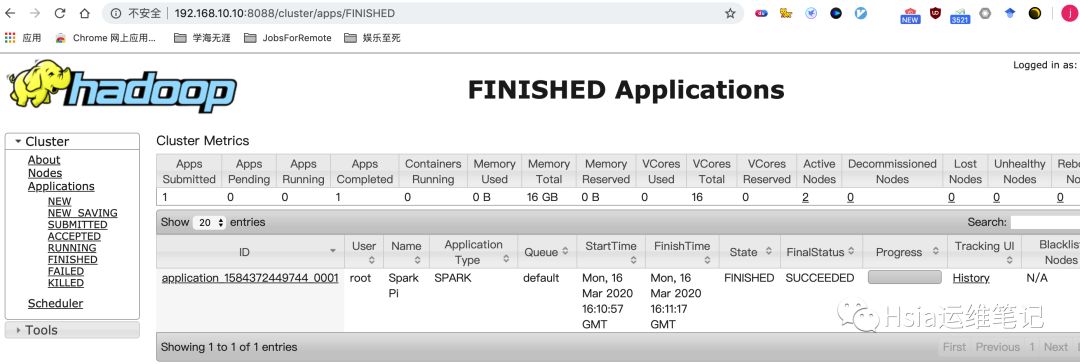
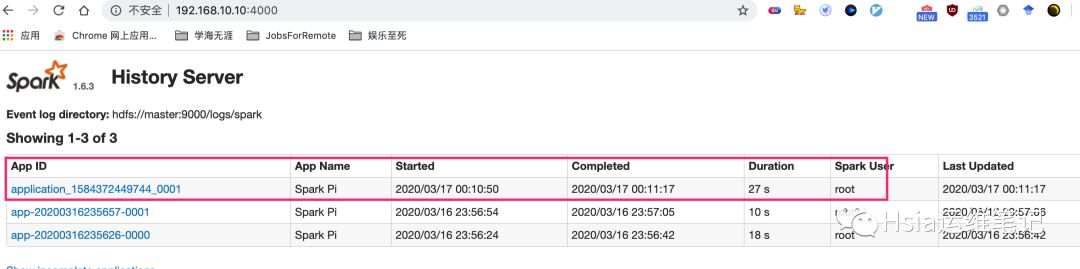
yarn-cluster模式-生产推荐
以cluster模式连接到yarn集群,该方式driver运行在worker节点上.
[root@master sbin]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --executor-memory 1G --total-executor-cores 3 /usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/spark-examples-1.6.3-hadoop2.6.0.jar 10SLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/spark-assembly-1.6.3-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]20/03/17 00:20:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable20/03/17 00:20:45 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.10.10:803220/03/17 00:20:46 INFO yarn.Client: Requesting a new application from cluster with 2 NodeManagers20/03/17 00:20:46 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)20/03/17 00:20:46 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead20/03/17 00:20:46 INFO yarn.Client: Setting up container launch context for our AM20/03/17 00:20:46 INFO yarn.Client: Setting up the launch environment for our AM container20/03/17 00:20:46 INFO yarn.Client: Preparing resources for our AM container20/03/17 00:20:46 INFO yarn.Client: Uploading resource file:/usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/spark-assembly-1.6.3-hadoop2.6.0.jar -> hdfs://master:9000/user/root/.sparkStaging/application_1584372449744_0002/spark-assembly-1.6.3-hadoop2.6.0.jar20/03/17 00:20:48 INFO yarn.Client: Uploading resource file:/usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/spark-examples-1.6.3-hadoop2.6.0.jar -> hdfs://master:9000/user/root/.sparkStaging/application_1584372449744_0002/spark-examples-1.6.3-hadoop2.6.0.jar20/03/17 00:20:49 INFO yarn.Client: Uploading resource file:/tmp/spark-7befe4c8-7cdb-4bb7-854e-72ceb2e35ba5/__spark_conf__2106094435745232503.zip -> hdfs://master:9000/user/root/.sparkStaging/application_1584372449744_0002/__spark_conf__2106094435745232503.zip20/03/17 00:20:49 INFO spark.SecurityManager: Changing view acls to: root20/03/17 00:20:49 INFO spark.SecurityManager: Changing modify acls to: root20/03/17 00:20:49 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)20/03/17 00:20:49 INFO yarn.Client: Submitting application 2 to ResourceManager20/03/17 00:20:49 INFO impl.YarnClientImpl: Submitted application application_1584372449744_000220/03/17 00:20:50 INFO yarn.Client: Application report for application_1584372449744_0002 (state: ACCEPTED)20/03/17 00:20:50 INFO yarn.Client:client token: N/Adiagnostics: N/AApplicationMaster host: N/AApplicationMaster RPC port: -1queue: defaultstart time: 1584375649601final status: UNDEFINEDtracking URL: http://master:8088/proxy/application_1584372449744_0002/user: root20/03/17 00:20:51 INFO yarn.Client: Application report for application_1584372449744_0002 (state: ACCEPTED)20/03/17 00:20:52 INFO yarn.Client: Application report for application_1584372449744_0002 (state: ACCEPTED)20/03/17 00:20:53 INFO yarn.Client: Application report for application_1584372449744_0002 (state: ACCEPTED)20/03/17 00:20:54 INFO yarn.Client: Application report for application_1584372449744_0002 (state: ACCEPTED)20/03/17 00:20:55 INFO yarn.Client: Application report for application_1584372449744_0002 (state: ACCEPTED)20/03/17 00:20:56 INFO yarn.Client: Application report for application_1584372449744_0002 (state: ACCEPTED)20/03/17 00:20:57 INFO yarn.Client: Application report for application_1584372449744_0002 (state: ACCEPTED)20/03/17 00:20:58 INFO yarn.Client: Application report for application_1584372449744_0002 (state: ACCEPTED)20/03/17 00:20:59 INFO yarn.Client: Application report for application_1584372449744_0002 (state: RUNNING)20/03/17 00:20:59 INFO yarn.Client:client token: N/Adiagnostics: N/AApplicationMaster host: 192.168.10.11ApplicationMaster RPC port: 0queue: defaultstart time: 1584375649601final status: UNDEFINEDtracking URL: http://master:8088/proxy/application_1584372449744_0002/user: root20/03/17 00:21:00 INFO yarn.Client: Application report for application_1584372449744_0002 (state: RUNNING)20/03/17 00:21:01 INFO yarn.Client: Application report for application_1584372449744_0002 (state: RUNNING)20/03/17 00:21:02 INFO yarn.Client: Application report for application_1584372449744_0002 (state: RUNNING)20/03/17 00:21:03 INFO yarn.Client: Application report for application_1584372449744_0002 (state: RUNNING)20/03/17 00:21:04 INFO yarn.Client: Application report for application_1584372449744_0002 (state: RUNNING)20/03/17 00:21:05 INFO yarn.Client: Application report for application_1584372449744_0002 (state: RUNNING)20/03/17 00:21:06 INFO yarn.Client: Application report for application_1584372449744_0002 (state: RUNNING)20/03/17 00:21:07 INFO yarn.Client: Application report for application_1584372449744_0002 (state: RUNNING)20/03/17 00:21:08 INFO yarn.Client: Application report for application_1584372449744_0002 (state: FINISHED)20/03/17 00:21:08 INFO yarn.Client:client token: N/Adiagnostics: N/AApplicationMaster host: 192.168.10.11ApplicationMaster RPC port: 0queue: defaultstart time: 1584375649601final status: SUCCEEDEDtracking URL: http://master:8088/proxy/application_1584372449744_0002/user: root20/03/17 00:21:08 INFO yarn.Client: Deleting staging directory .sparkStaging/application_1584372449744_000220/03/17 00:21:08 INFO util.ShutdownHookManager: Shutdown hook called20/03/17 00:21:08 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-7befe4c8-7cdb-4bb7-854e-72ceb2e35ba5[root@master sbin]#
在yarn的web界面,找到运行记录,logs中可以看已经求得Pi值3.1400671400671403
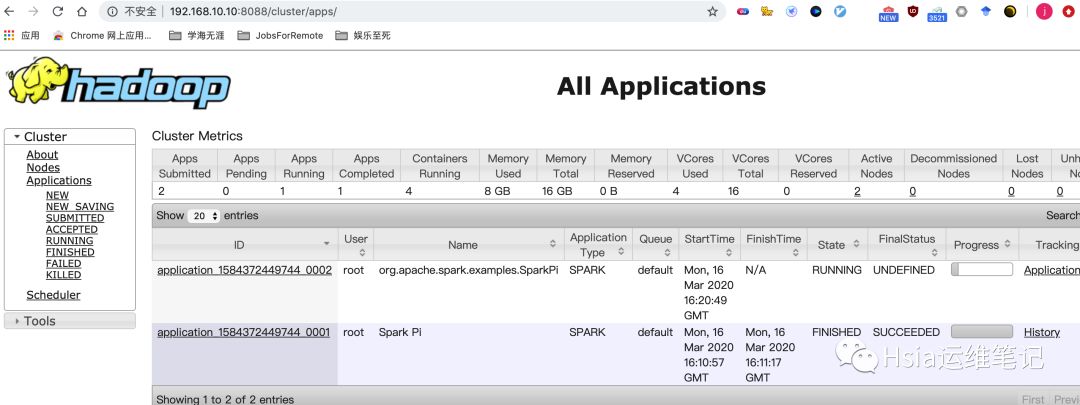
提交任务时的几个重要参数:
executor-cores 每个executor使用的内核数,默认为1num-executors 启动executor的数量,默认为2executor-memory executor的内存大小,默认为1Gdriver-cores driver使用的内核数,默认为1driver-memory driver的内存大小,默认为1Gqueue 指定了放在哪个队列里执行spark.default.parallelism //该参数用于设置每个stage的默认task数量。\这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适spark.storage.memoryFraction该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。spark.shuffle.memoryFraction该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。total-executor-cores 所有executor的总核数
几个重要的参数说明:
(1)executor_cores*num_executors表示的是能够并行执行Task的数目不宜太小或太大!一般不超过总队列 cores 的 25%,比如队列总 cores 400,最大不要超过100,最小不建议低于40,除非日志量很小。(2)executor_cores不宜为1!否则 work 进程中线程数过少,一般 2~4 为宜。(3)executor_memory一般 6~10g 为宜,最大不超过20G,否则会导致GC代价过高,或资源浪费严重。(4)driver-memorydriver 不做任何计算和存储,只是下发任务与yarn资源管理器和task交互,除非你是 spark-shell,否则一般 1-2g增加每个executor的内存量,增加了内存量以后,对性能的提升,有三点:(5)如果需要对RDD进行cache,那么更多的内存,就可以缓存更多的数据,将更少的数据写入磁盘,甚至不写入磁盘。减少了磁盘IO。(6)对于shuffle操作,reduce端,会需要内存来存放拉取的数据并进行聚合。如果内存不够,也会写入磁盘。如果给executor分配更多内存以后,就有更少的数据,需要写入磁盘,甚至不需要写入磁盘。减少了磁盘IO,提升了性能。(7)对于task的执行,可能会创建很多对象.如果内存比较小,可能会频繁导致JVM堆内存满了,然后频繁GC,垃圾回收 ,minor GC和full GC.(速度很慢).内存加大以后,带来更少的GC,垃圾回收,避免了速度变慢,性能提升。
参考链接:
http://spark.apache.org/docs/1.6.3/
https://blog.csdn.net/qq_17677907/article/details/88685705
以上是关于Spark介绍及基于YARN模式的Spark集群部署的主要内容,如果未能解决你的问题,请参考以下文章