15倍提升 & 40倍存储优化,TDengine在领益智造的实践
Posted 涛思数据TDengine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了15倍提升 & 40倍存储优化,TDengine在领益智造的实践相关的知识,希望对你有一定的参考价值。
 查询最近7天的数据,70倍的查询效率提升也如实映射为正常业务环境下的表现。
查询最近7天的数据,70倍的查询效率提升也如实映射为正常业务环境下的表现。
作者:张红朋
小T导读:广东领益智造股份有限公司是全球领先的智能制造平台企业,致力于以技术先进、质量可靠为核心竞争力,为客户提供“一站式”精密智造解决方案,实现精密、美观、高品质、低成本于一体的终端产品。业务涵盖消费电子、医疗器械、汽车零部件等多个行业,凭借先进的研发与制造能力,领益智造与世界知名企业建立了稳固的战略合作关系,综合实力位居全球同行业前三强。

在对生产设备的AOI全检数据进行质量分析时,我们对关系型数据库做了很多预处理运算,但是在计算正态分布、盒须图、尺寸分析及原始数据查询上遇到了致命的性能问题。此前我们选择的数据库服务器已达到较高的硬件配置(1.5T的内存、96逻辑核的CPU、全闪盘的专业存储),再想要通过提高服务器配置来实现响应速度的提升是非常困难的。即使数据库对查询做了相应的索引,选择一周的数据进行查询时,系统的响应时间仍然在20秒以上。
为了解决当下的问题,我们找了很多方案进行测试。首先使用Hadoop生成10亿的数据量进行查询的模拟测试,发现实时查询时的查询效率还没有关系型数据库好,因此排除了Hadoop替代方案。接着对杉岩的对像存储方案进行测试,因其对象存储的缘故,采用此方案的话才购买不久的服务器资源就无法使用了,同时还需要再投入软硬件费用,成本较高。
正当我们准备验证ClickHouse方案时,却在查询资料时无意中发现了TDengine,查看官方的性能报告后,我们决定对其进行测试。我们下载了2020年的TDengine社区版进行测试,发现在写入、查询时的效率很惊艳,随即开始展开其与业务匹配度的评估,确认了在计算正态分布、盒须图、尺寸分析时的匹配度均很高,而这些问题恰好又是我们现在所急需解决的。
最终我们决定使用关系型数据库和时序数据库同时保存两份数据,以此来满足不同的业务场景。
一、经验分享
结合数据特点和使用场景,我们开始构建超级表,以其中一张表为例,数据模型创建如下:
create table t_qualityproductdetail (ftime TIMESTAMP,fqualityproductid BINARY(32),fpromachineid BIGINT,fjobnumber BINARY(50),fsn BINARY(250),value FLOAT,standard FLOAT,max FLOAT,min FLOAT,createon TIMESTAMP,fisok INT) TAGS (fproductid BIGINT,fprocessesid BIGINT,faiid BIGINT,fmachineid BIGINT,fresult INT,fcount INT)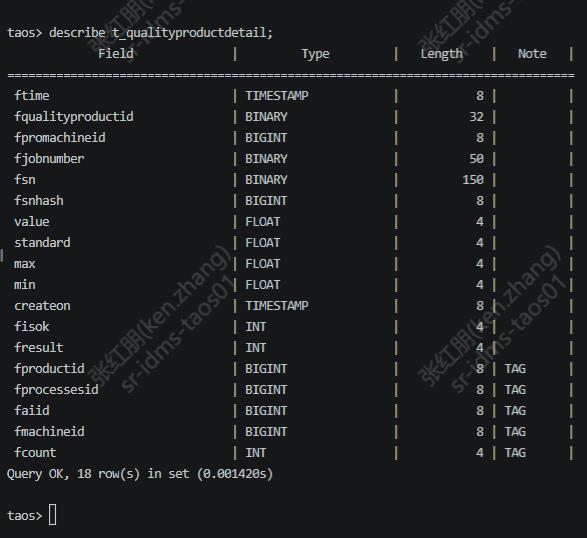
在引入TDengine时首先面临的就是时间戳的问题。因为我们每一个产品在同一个时间点会有多个数据产生,且这些数据是在同一台机器上产生的,按照官方文档,在一个超级表中一台机器一个子表的方式会造成“只能存储最后一条数据”的问题,经分析后最终我们决定把表拆到每个检测点的粒度,以此方式解决了此问题。
但由此也带来了一个新的问题,那就是表数量超限。在2.2以前的版本上,官方建议超级表的数量不应超过4万个,而我们的产品、生产机台号、检测机台号外加检测点的集合,按计算会远大于4万个,我们也很担心在上线后会对性能造成较大影响,但所幸新的2.2版本没有这一限制了。
通过与官方的沟通,我们在使用过程中接触到了更多TDengine的特性,将其应用到业务中支持更多的时序数据场景,目前TDengine已经被应用在中间表预处理、良率计算、通过序列号查询产品实例的测点明细等业务中,其中在良率计算上还用到了一些小技巧,在此给大家做一下经验分享。
在良率计算逻辑调整上,关系型数据库中是通过子查询的关联来进行每台机器的良率计算,判断良品是通过一个Fresult进行判断,结果为1(良品)、2(不良品)、3(重测),计算时采用以下方式:
select FProcessesID,FConmpyID,FMachineID,FProductID,FProMachineID,cast(FTime as date) FTime,FCount,count(0) FTotalCount,sum(case FRESULT when 1 then 1 else 0 end) FOKCount from [T_QualityProduct] t0 WITH (nolock) where FTime >=@currdate and FTime <@currenddate group by FProcessesID,FConmpyID,FMachineID,FProductID,FProMachineID,cast(FTime as date),FCount而TDengine不支持case when的运算,在处理时需要计算两次,先是通过以下方式来计算总数:
select FProMachineID,FCount,count(*) FTotalCount from [T_QualityProduct] where FTime >=@currdate and FTime <@currenddate group by FProcessesID,FConmpyID,FMachineID,FProductID,FProMachineID,FCount interval(1d)然后再通过以下方式计算良品数量:
select FProMachineID,FCount,count(*) FOKCount from [T_QualityProduct] where FTime >=@currdate and FTime <@currenddate and FRESULT =1 group by FProcessesID,FConmpyID,FMachineID,FProductID,FProMachineID,FCount interval(1d)算出结果后通过程序代码把上述多条件分组汇总的数据合并到一起。
以上这种计算方式有两个缺点,一是需要查询两次,效率不高;二是程序代码中需要做多条件的匹配汇总,代码改造工作量较大,效率低。经反复沟通后,最终我们决定增加一个fisok的Int类型的字段,良品用1,其余用0来展示,经此改造后,代码和执行效率有了质的提升。可以直接使用以下的代码来实现查询:
select FCount, count(*) FTotalCount,sum(fisok) FOKCount,sum(fisok)/count(*) yeild from [T_QualityProduct] where FTime >=@currdate and FTime <@currenddate group by FProcessesID,FConmpyID,FMachineID,FProductID,FProMachineID,FCount interval(1d)最终我们使用此方式成功计算出了良率,且性能远高于关系型数据库,程序代码也不用改动。
二、效果展示
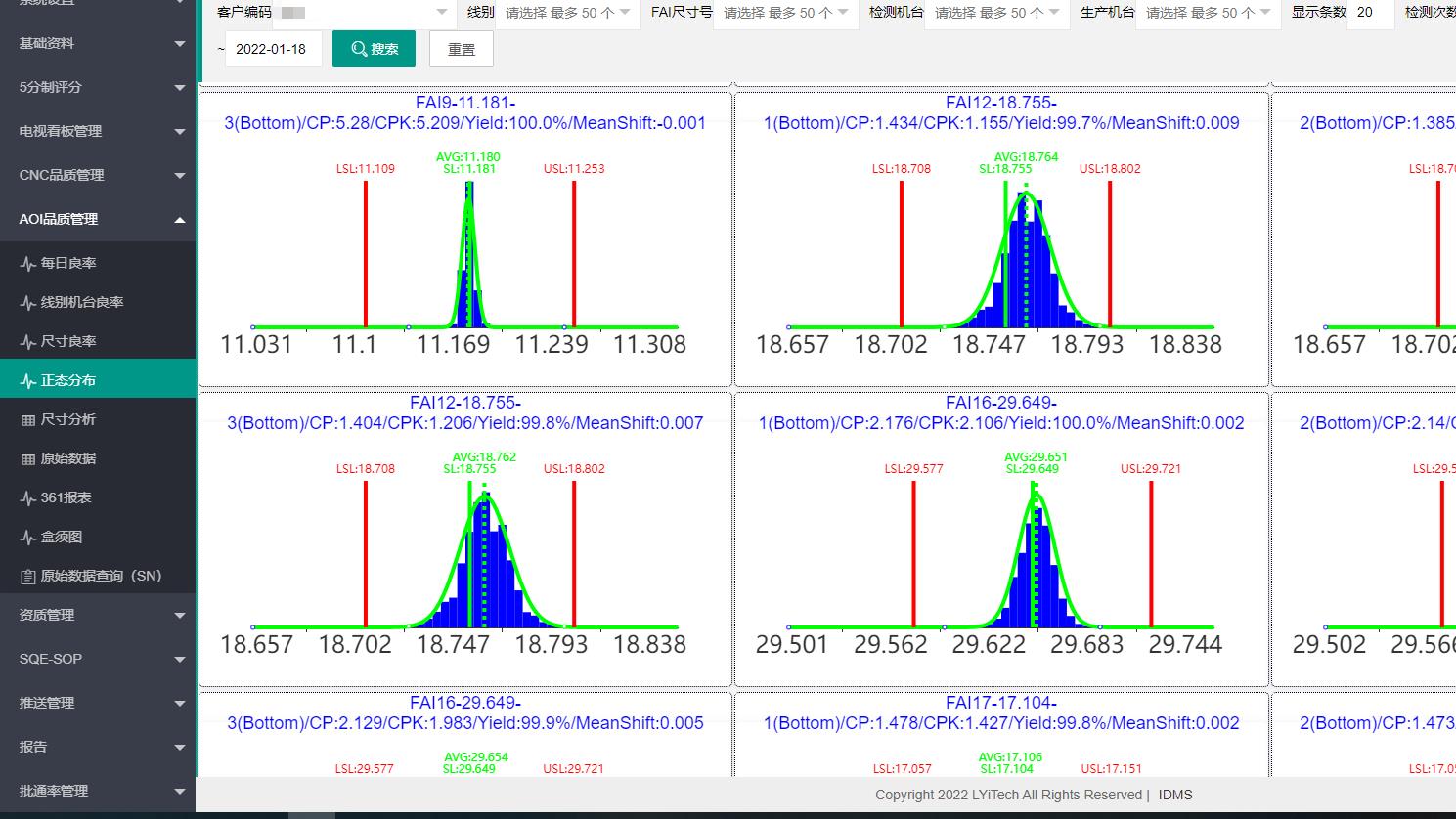
在TDengine成功上线接入后,我们将每日良率、线别机台良率、尺寸良率分析、正态分布、361分析、盒须图、原始数据查看等业务都移到了TDengine中,而TDengine在实际业务中也展现出了如测试时所表现的高效性能。
1. 存储容量对比
1)某关系型数据库的数据空间和索引空间大小,QualityProductDetail和QualityProduct两张表分别求和。
2)TDengine通过在CentOS执行du -sh /var/lib/taos查看文件夹大小。

2. 查询效率对比
- 通过正态分布语句进行查询对比
1)5天查询条件:FTime between \'2021-06-21 00:00:00.000000\' and \'2021-06-25 23:59:59.999999\' and FAIID=1693 and FProcessesID=1 and value<999 and FCount=1

2)3月查询条件:FTime between \'2021-06-01 20:00:00.000000\' and \'2021-09-01 19:59:59.999999\' and FAIID=1693 and FProcessesID=1 and value<999 and FCount=1

- 查询效率对比详细测试数据
1)5天数据
某关系型数据库——查询结果量414,995条,平均耗时328.13秒
TDengine——查询结果量413,180条,平均耗时4.61秒
2)3个月数据
某关系型数据库——查询结果量1,949,501条,平均耗时340.29秒
TDengine——查询结果量1,848,385条,平均耗时20.80秒
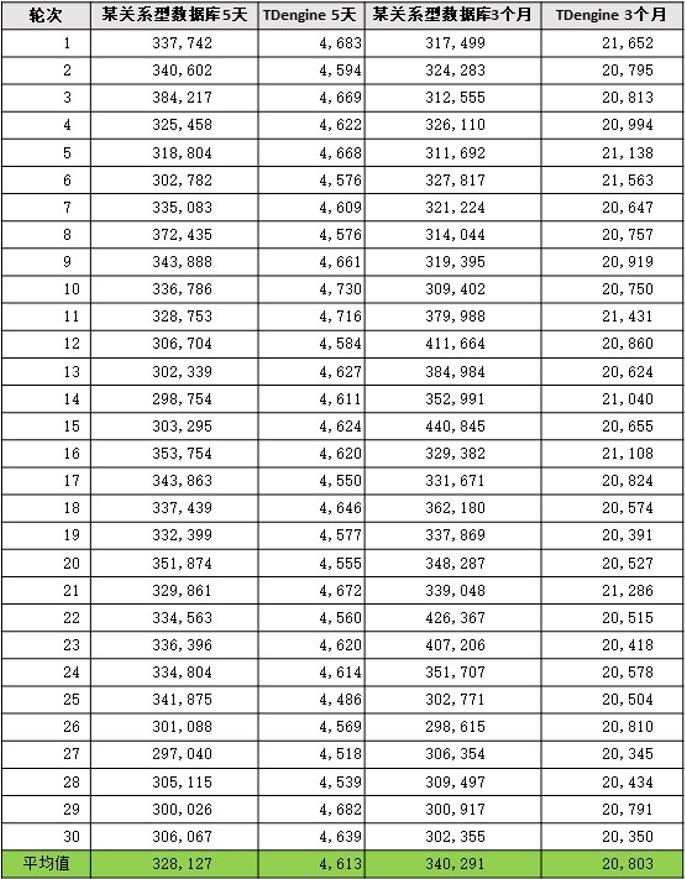
通过以上的对比测试,我们发现在同等条件下,查询最近5天的数据,某关系型数据库平均耗时328.13秒,而用TDengine则平均耗时4.61秒,用时为原来的70分之一,查询效率提升了70倍,把数据拉长到3个月,效率也有15倍的提升。在我们正常的业务场景下,80%的情况会查询最近7天的数据,70倍的查询效率提升也如实映射为正常业务环境下的表现。
我们使用原来的关系型数据库时,会建立大量的索引来提升查询速度,但发现进行原始数据查询计算时效率还是太低,响应时间以十秒为单位,故而采用了预处理的方案,把每日的良率提前按产品、机台进行混部,这样在查询时就可以有较快的查询速度,但同时也牺牲了空间和实时性。通过以上对比可以看出,在建好索引和中间表的情况下,同样的数据量级,某关系型数据库的空间使用是TDengine的40倍。
三、写在最后
伴随物联网技术终端和应用的跨越式发展,其背后巨大的市场空间和经济效益日益显现,作为一个大的技术趋势被科技企业广泛关注。在此背景下,TDengine作为一款专为物联网大数据场景而生的时序数据库,它所展现出的高效性能和成本管控能力都非常惊艳,成为科技企业抓住物联网机遇的一个有力抓手。
目前我们已着手把稼动率的项目迁移到TDengine上,同时集团在2021年底把物联部门提升为一级部门,后续将会有更多的设备联机数据需要存储和分析。
想了解更多TDengine的具体细节,欢迎大家在GitHub上查看相关源代码。
以上是关于15倍提升 & 40倍存储优化,TDengine在领益智造的实践的主要内容,如果未能解决你的问题,请参考以下文章