如何利用缓存机制实现JAVA类反射性能提升30倍
Posted 宜信技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何利用缓存机制实现JAVA类反射性能提升30倍相关的知识,希望对你有一定的参考价值。
一次性能提高30倍的JAVA类反射性能优化实践
文章来源:宜信技术学院 & 宜信支付结算团队技术分享第4期-支付结算部支付研发团队高级工程师陶红《JAVA类反射技术&优化》
分享者:宜信支付结算部支付研发团队高级工程师陶红
原文首发于宜信支付结算技术团队公号:野指针
在实际工作中的一些特定应用场景下,JAVA类反射是经常用到、必不可少的技术,在项目研发过程中,我们也遇到了不得不运用JAVA类反射技术的业务需求,并且不可避免地面临这个技术固有的性能瓶颈问题。
通过近两年的研究、尝试和验证,我们总结出一套利用缓存机制、大幅度提高JAVA类反射代码运行效率的方法,和没有优化的代码相比,性能提高了20~30倍。本文将与大家分享在探索和解决这个问题的过程中的一些有价值的心得体会与实践经验。
简述:JAVA类反射技术
首先,用最简短的篇幅介绍JAVA类反射技术。
如果用一句话来概述,JAVA类反射技术就是:
绕开编译器,在运行期直接从虚拟机获取对象实例/访问对象成员变量/调用对象的成员函数。
抽象的概念不多讲,用代码说话……举个例子,有这样一个类:
public class ReflectObj { private String field01; public String getField01() { return this.field01; } public void setField01(String field01) { this.field01 = field01; } }
如果按照下列代码来使用这个类,就是传统的“创建对象-调用”模式:
ReflectObj obj = new ReflectObj(); obj.setField01("value01"); System.out.println(obj.getField01());
如果按照如下代码来使用它,就是“类反射”模式:
// 直接获取对象实例 ReflectObj obj = ReflectObj.class.newInstance(); // 直接访问Field Field field = ReflectObj.class.getField("field01"); field.setAccessible(true); field.set(obj, "value01"); // 调用对象的public函数 Method method = ReflectObj.class.getMethod("getField01"); System.out.println((String) method.invoke(obj));
类反射属于古老而基础的JAVA技术,本文不再赘述。
从上面的代码可以看出:
- 相比较于传统的“创建对象-调用”模式,“类反射”模式的代码更抽象、一般情况下也更加繁琐;
- 类反射绕开了编译器的合法性检测——比如访问了一个不存在的字段、调用了一个不存在或不允许访问的函数,因为编译器设立的防火墙失效了,编译能够通过,但是运行的时候会报错;
- 实际上,如果按照标准模式编写类反射代码,效率明显低于传统模式。在后面的章节会提到这一点。
缘起:为什么使用类反射
前文简略介绍了JAVA类反射技术,在与传统的“创建对象-调用”模式对比时,提到了类反射的几个主要弱点。但是在实际工作中,我们发现类反射无处不在,特别是在一些底层的基础框架中,类反射是应用最为普遍的核心技术之一。最常见的例子:Spring容器。
这是为什么呢?我们不妨从实际工作中的具体案例出发,分析类反射技术的不可替代性。
大家几乎每天都和银行打交道,通过银行进行存款、转帐、取现等金融业务,这些动账操作都是通过银行核心系统(包括交易核心/账务核心/对外支付/超级网银等模块)完成的,因为历史原因造成的技术路径依赖,银行核心系统的报文几乎都是xml格式,而且以这种格式最为普遍:
<?xml version=\'1.0\' encoding=\'UTF-8\'?> <service> <sys-header> <data name="SYS_HEAD"> <struct> <data name="MODULE_ID"> <field type="string" length="2">RB</field> </data> <data name="USER_ID"> <field type="string" length="6">OP0001</field> </data> <data name="TRAN_TIMESTAMP"> <field type="string" length="9">003026975</field> </data> <!-- 其它字段略过 --> </struct> </data> </sys-header> <!-- 其它段落略过 --> <body> <data name="REF_NO"> <field type="string" length="23">OPS18112400302633661837</field> </data> </body> </service>
和常用的xml格式进行对比:
<?xml version="1.0" encoding="UTF-8"?> <recipe> <recipename>Ice Cream Sundae</recipename> <ingredlist> <listitem> <quantity>3</quantity> <itemdescription>chocolate syrup or chocolate fudge</itemdescription> </listitem> <listitem> <quantity>1</quantity> <itemdescription>nuts</itemdescription> </listitem> <listitem> <quantity>1</quantity> <itemdescription>cherry</itemdescription> </listitem> </ingredlist> <preptime>5 minutes</preptime> </recipe>
银行核心系统的xml报文不是用标签的名字区分元素,而是用属性(name属性)区分,在解析的时候,不管是用DOM、SAX,还是Digester或其它方案,都要用条件判断语句、分支处理,伪代码如下:
// …… 接口类实例 obj = new 接口类(); List<Node> nodeList = 获取xml标签列表 for (Node node: nodeList) { if (node.getProperty("name") == "张三") obj.set张三 (node.getValue()); else if (node.getProperty("name") == "李四") obj.set李四 (node.getValue()); // …… } // ……
显而易见,这样的代码非常粗劣、不优雅,每解析一个接口的报文,都要写一个专门的类或者函数,堆砌大量的条件分支语句,难写、难维护。如果报文结构简单还好,如果有一百个甚至更多的字段,怎么办?毫不夸张,在实际工作中,我遇到过一个银行核心接口有140多个字段的情况,而且这还不是最多的!
试水:优雅地解析XML
当我们碰到这种结构的xml、而且字段还特别多的时候,解决问题的钥匙就是类反射技术,基本思路是:
- 从xml中解析出字段的name和value,以键值对的形式存储起来;
- 用类反射的方法,用键值对的name找到字段或字段对应的setter(这是有规律可循的);
- 然后把value直接set到字段,或者调用setter把值set到字段。
接口类应该是这样的结构:


- nodes是存储字段的name-value键值对的列表,MessageNode就是键值对,结构如下:
public class MessageNode { private String name; private String value; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getValue() { return value; } public void setValue(String value) { this.value = value; } public MessageNode() { super(); } }
- createNode是在解析xml的时候,把键值对添加到列表的函数;
- initialize是用类反射方法,根据键值对初始化每个字段的函数。
这样,解析xml的代码可以变得非常优雅、简洁。如果用Digester解析之前列举的那种格式的银行报文,可以这样写:
Digester digester = new Digester(); digester.setValidating(false); digester.addObjectCreate("service/sys-header", SysHeader.class); digester.addCallMethod("service/sys-header/data/struct/data", "createNode", 2); digester.addCallParam("service/sys-header/data/struct/data", 0, "name"); digester.addCallParam("service/sys-header/data/struct/data/field", 1); parseObj = (SysHeader) digester.parse(new StringReader(msg)); parseObj.initialize();
initialize函数的代码,可以写在一个基类里面,子类继承基类即可。具体代码如下:
public void initialize() { for (MessageNode node: nodes) { try { /** * 直接获取字段、然后设置字段值 */ //String fieldName = StringUtils.camelCaseConvert(node.getName()); // 只获取调用者自己的field(private/protected/public修饰词皆可) //Field field = this.getClass().getDeclaredField(fieldName); // 获取调用者自己的field(private/protected/public修饰词皆可)和从父类继承的field(必须是public修饰词) //Field field = this.getClass().getField(fieldName); // 把field设为可写 //field.setAccessible(true); // 直接设置field的值 //field.set(this, node.getValue()); /** * 通过setter设置字段值 */ Method method = this.getSetter(node.getName()); // 调用setter method.invoke(this, node.getValue()); } catch (Exception e) { log.debug("It\'s failed to initialize field: {}, reason: {}", node.getName(), e); }; } }
上面被注释的段落是直接访问Field的方式,下面的段落是调用setter的方式,两种方法在效率上没有差别。
考虑到JAVA语法规范(书写bean的规范),调用setter是更通用的办法,因为接口类可能是被继承、派生的,子类无法访问父类用private关键字修饰的Field。
getSetter函数很简单,就是用Field的名字反推setter的名字,然后用类反射的办法获取setter。代码如下:
private Method getSetter(String fieldName) throws NoSuchMethodException, SecurityException { String methodName = String.format("set%s", StringUtils.upperFirstChar(fieldName)); // 获取field的setter,只要是用public修饰的setter、不管是自己的还是从父类继承的,都能取到 return this.getClass().getMethod(methodName, String.class); }
如果设计得好,甚至可以用一个解析函数处理所有的接口,这涉及到Digerser的运用技巧和接口类的设计技巧,本文不作深入讲解。
2017年,我们在一个和银行有关的金融增值服务项目中使用了这个解决方案,取得了非常不错的效果,之后在公司内部推广开来成为了通用技术架构。经过一年多的实践,证明这套架构性能稳定、可靠,极大地简化了代码编写和维护工作,显著提高了生产效率。
问题:类反射性能差
但是,随着业务量的增加,2018年末在进行压力测试的时候,发现解析xml的代码占用CPU资源居高不下。进一步分析、定位,发现问题出在类反射代码上,在某些极端的业务场景下,甚至会占用90%的CPU资源!这就提出了性能优化的迫切要求。
类反射的性能优化不是什么新课题,因此有一些成熟的第三方解决方案可以参考,比如运用比较广泛的ReflectASM,据称可以比未经优化的类反射代码提高1/3左右的性能。
(参考资料:Java高性能反射工具包ReflectASM,ReflectASM-invoke,高效率java反射机制原理)
在研究了ReflectASM的源代码以后,我们决定不使用现成的第三方解决方案,而是从底层入手、自行解决类反射代码的优化问题。主要基于两点考虑:
- ReflectASM的基本技术原理,是在运行期动态分析类的结构,把字段、函数建立索引,然后通过索引完成类反射,技术上并不高深,性能也谈不上完美;
- 类反射是我们系统使用的关键技术,使用场景、调用频率都非常高,从自主掌握和控制基础、核心技术,实现系统的性能最优化角度考虑,应该尽量从底层技术出发,独立、可控地完成优化工作。
思路和实践:缓存优化
前面提到ReflectASM给类的字段、函数建立索引,借此提高类反射效率。进一步分析,这实际上是变相地缓存了字段和函数。那么,在我们面临的业务场景下,能不能用缓存的方式优化类反射代码的效率呢?
我们的业务场景需要以类反射的方式频繁调用接口类的setter,这些setter都是用public关键字修饰的函数,先是getMethod()、然后invoke()。基于以上特点,我们用如下逻辑和流程进行了技术分析:
- 用调试分析工具统计出每一句类反射代码的执行耗时,结果发现性能瓶颈在getMethod();
- 分析JAVA虚拟机的内存模型和管理机制,寻找解决问题的方向。JAVA虚拟机的内存模型,可以从下面两个维度来描述:
A.类空间/对象空间维度

B.堆/栈维度

- 从JAVA虚拟机内存模型可以看出,getMethod()需要从不连续的堆中检索代码段、定位函数入口,获得了函数入口、invoke()之后就和传统的函数调用差不多了,所以性能瓶颈在getMethod();
- 代码段属于类空间(也有资料将其描述为“函数空间”/“代码空间”),类被加载后,除非虚拟机关闭,函数入口不会变化。那么,只要把setter函数的入口缓存起来,不就节约了getMethod()消耗的系统资源,进而提高了类反射代码的执行效率吗?
把接口类修改为这样的结构(标红的部分是新增或修改):
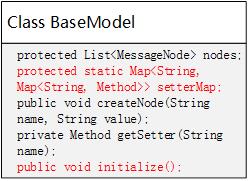

setterMap就是缓存字段setter的HashMap。为什么是两层嵌套结构呢?因为这个Map是写在基类里面的静态变量,每个从基类派生出的接口类都用它缓存setter,所以第一层要区分不同的接口类,第二层要区分不同的字段。如下图所示:
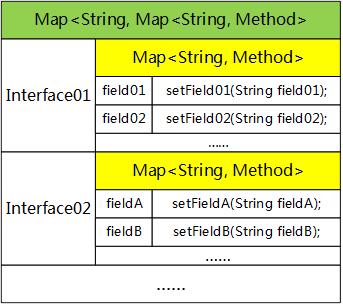
当ClassLoader加载基类时,创建setterMap(内容为空):
static { setterMap = new HashMap<String, Map<String, Method>>(); }
这样写可以保证setterMap只被初始化一次。
Initialize()函数作如下改进:
public void initialize() { // 先检查子类的setter是否被缓存 String className = this.getClass().getName(); if (setterMap.get(className) == null) setterMap.put(className, new HashMap<String, Method>()); Map<String, Method> setters = setterMap.get(className); // 遍历报文节点 for (MessageNode node: nodes) { try { // 检查对应的setter是否被缓存了 Method method = setters.get(node.getName()); if (method == null) { // 没有缓存,先获取、再缓存 method = this.getSetter(node.getName()); setters.put(node.getName(), method); } // 用类反射方式调用setter method.invoke(this, node.getValue()); } catch (Exception e) { log.debug("It\'s failed to initialize field: {}, reason: {}", node.getName(), e); }; } }
基本思路就是把setter缓存起来,通过MessageNode的name(字段的名字)找setter的入口地址,然后调用。
因为只在初始化第一个对象实例的时候调用getMethod(),极大地节约了系统资源、提高了效率,测试结果也证实了这一点。
验证:测试方法和标准
1)先写一个测试类,结构如下:


2)在构造函数中,用UUID初始化存储键值对的列表nodes:
this.createNode("test001", String.valueOf(UUID.randomUUID().toString().hashCode())); this.createNode("test002", String.valueOf(UUID.randomUUID().toString().hashCode())); // ……
之所以用UUID,是保证每个实例、每个字段的值都不一样,避免JAVA编译器自动优化代码而破坏测试结果的原始性。
3)Initialize_ori()函数是用传统的硬编码方式直接调用setter的方法初始化实例字段,代码如下:
for (MessageNode node: this.nodes) { if (node.getName().equalsIgnoreCase("test001")) this.setTest001(node.getValue()); else if (node.getName().equalsIgnoreCase("test002")) this.setTest002(node.getValue()); // …… }
优化效果就以它作为对照标准1,对照标准2就是没有优化的类反射代码。
4)checkUnifomity()函数用来验证:代码是否用name-value键值对正确地初始化了各字段。
for (MessageNode node: nodes) { if (node.getName().equalsIgnoreCase("test001") && !node.getValue().equals(this.test001)) return false; else if (node.getName().equalsIgnoreCase("test002") && !node.getValue().equals(this.test002)) return false; // …… } return true;
每一种优化方案,我们都会用它验证实例的字段是否正确,只要出现一次错误,该方案就会被否定。
5)创建100万个TestInvoke类的实例,然后循环调用每一个实例的initialize_ori()函数(传统的硬编码,非类反射方法),记录执行耗时(只记录初始化耗时,创建实例的耗时不记录);再创建100万个实例,循环调用每一个实例的类反射初始化函数(未优化),记录执行耗时;再创建100万个实例,改成调用优化后的类反射初始化函数,记录执行耗时。
6)以上是一个测试循环,得到三种方法的耗时数据,重复做10次,得到三组耗时数据,把记录下的数据去掉最大、最小值,剩下的求平均值,就是该方法的平均耗时。某一种方法的平均耗时越短则认为该方法的效率越高。
7)为了进一步验证三种方法在不同负载下的效率变化规律,改成创建10万个实例,重复5/6两步,得到另一组测试数据。
测试结果显示:在确保测试环境稳定、一致的前提下,8个字段的测试实例、初始化100万个对象,传统方法(硬编码)耗时850~1000毫秒;没有优化的类反射方法耗时23000~25000毫秒;优化后的类反射代码耗时600~800毫秒。10万个测试对象的情况,三种方法的耗时也大致是这样的比例关系。这个数据取决于测试环境的资源状况,不同的机器、不同时刻的测试,结果都有出入,但总的规律是稳定的。
基于测试结果,可以得出这样的结论:缓存优化的类反射代码比没有优化的代码效率提高30倍左右,比传统的硬编码方法提高了10~20%。有必要强调的是,这个结论偏向保守。和ReflecASM相比,性能大幅度提高也是毋庸置疑的。
第一次迭代:忽略字段
缓存优化的效果非常好,但是,这个方案真的完美无缺了么?
经过分析,我们发现:如果数据更复杂一些,这个方案的缺陷就暴露了。比如键值对列表里的值在接口类里面并没有定义对应的字段,或者是没有对应的、可以访问的setter,性能就会明显下降。
这种情况在实际业务中是很常见的,比如对接银行核心接口,往往并不需要解析报文的全部字段,很多字段是可以忽略的,所以接口类里面不用定义这些字段,但解析代码依然会把这些键值对全部解析出来,这时就会给优化代码造成麻烦了。
分析过程如下:
1)举例而言,如果键值对里有两个值在接口类(Interface01)并未定义,假定名字是fieldX、filedY,第一次执行initialize()函数:
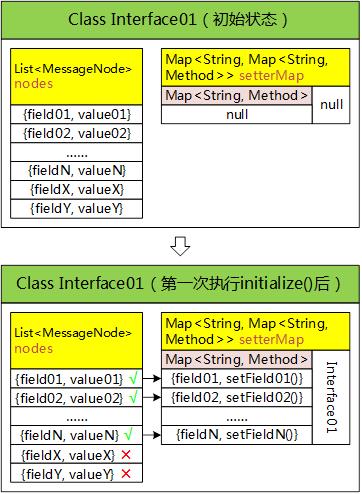
初始状态下,setterMap检索不到Interface01类的setter缓存,initialize()函数会在第一次执行的时候,根据键值对的名字(field01/field02/……/fieldN/fieldX/fieldY)调用getMethod()函数、初始化sertter引用的缓存。因为fieldX和fieldY字段不存在,找不到它们对应的setter,缓存里也没有它们的引用。
2)第二次执行initialize()函数(也就是初始化第二个对象实例),field01/field02/……/fieldN键值对都能在缓存中找到setter的引用,调用速度很快;但缓存里找不到fieldX/fieldY的setter的引用,于是再次调用getMethod()函数,而因为它们的setter根本不存在(连这两个字段都不存在),做的是无用功,setterMap的状态没有变化。
3)第三次、第四次……第N次,都是如此,白白消耗系统资源,运行效率必然下降。
测试结果印证了这个推断:在TestInvoke的构造函数增加了两个不存在对应字段和setter的键值对(姑且称之为“无效键值对”),进行100万个实例的初始化测试,经过优化的类反射代码,耗时从原来的600~800毫秒,增加到7000~8000毫秒,性能下降10倍左右。如果增加更多的键值对(不存在对应字段),性能下降更严重。
所以必须进一步完善优化代码。为了加以区分,我们把之前的优化代码称为V1版;进一步完善的代码称为V2版。
怎么完善?从上面的分析不难找到思路:增加忽略字段(ignore field)缓存。
基类BaseModel作如下修改(标红部分是新增或者修改),增加了ignoreMap:

ignoreMap的数据结构类似于setterMap,但第二层不是HashMap,而是Set,缓存每个子类需要忽略的键值对的名字,使用Set更节约系统资源,如下图所示:
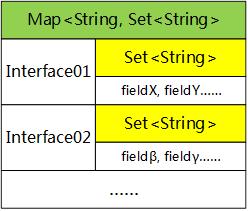
同样的,当ClassLoader加载基类的时候,创建ignoreMap(内容为空):
static { setterMap = new HashMap<String, Map<String, Method>>(); ignoreMap = new HashMap<String, Set<String>>(); }
Initialize()函数作如下改进:
public void initialize() { // 先检查子类的setter是否被缓存 String className = this.getClass().getName(); if (setterMap.get(className) == null) setterMap.put(className, new HashMap<String, Method>()); if (ignoreMap.get(className) == null) ignoreMap.put(className, new HashSet<String>()); Map<String, Method> setters = setterMap.get(className); Set<String> ignores = ignoreMap.get(className); // 遍历报文节点 for (MessageNode node: nodes) { String sName = node.getName(); try { // 检查该字段是否被忽略 if (ignores.contains(sName)) continue; // 检查对应的setter是否被缓存了 Method method = setters.get(sName); if (method == null) { // 没有缓存,先获取、再缓存 method = this.getSetter(sName); setters.put(sName, method); } // 用类反射方式调用setter method.invoke(this, node.getValue()); } catch (NoSuchMethodException | SecurityException e) { log.debug("It\'s failed to initialize field: {}, reason: {}", sName, e); // 找不到对应的setter,放到忽略字段集合,以后不再尝试 ignores.add(sName); } catch (IllegalAccessException | IllegalArgumentException | InvocationTargetException e) { log.error("It\'s failed to initialize field: {}, reason: {}", sName, e); try { // 不能调用setter,可能是虚拟机回收了该子类的全部实例、入口地址变化,更新地址、再试一次 Method method = this.getSetter(sName); setters.put(sName, method); method.invoke(this, node.getValue()); } catch (Exception e1) { log.debug("It\'s failed to initialize field: {}, reason: {}", sName, e1); } } catch (Exception e) { log.error("It\'s failed to initialize field: {}, reason: {}", sName, e); } } }
虽然代码复杂了一些,但思路很简单:用键值对的名字寻找对应的setter时,如果找不到,就把它放进ignoreMap,下次不再找了。另外还增加了对setter引用失效的处理。虽然理论上说“只要虚拟机不重启,setter的入口引用永远不会变”,在测试中也从来没有遇到过这种情况,但为了覆盖各种异常情况,还是增加了这段代码。
继续沿用前面的例子,分析改进后的代码的工作流程:
1)第一次执行initialize()函数,实例的状态是这样变化的:

因为fieldX和fieldY字段不存在,找不到它们对应的setter,它们被放到ignoreMap中。
2)再次调用initialize()函数的时候,因为检查到ignoreMap中存在fieldX和fieldY,这两个键值对被跳过,不再徒劳无功地调用getMethod();其它逻辑和V1版相同,没有变化。
还是用上面提到的TestInvoke类作验证(8个字段+2个无效键值对),V2版本虽然代码更复杂了,但100万条纪录的初始化耗时为600~800毫秒,V1版代码这个时候的耗时猛增到7000~8000毫秒。哪怕增加更多的无效键值对,V2版代码耗时增加也不明显,而这种情况下V1版代码的效率还会进一步下降。
至此,对JAVA类反射代码的优化已经比较完善,覆盖了各种异常情况,如前所述,我们把这个版本称为V2版。
第二次迭代:逆向思维
这样就代表优化工作已经做到最好了吗?不是这样的。
仔细观察V1、V2版的优化代码,都是循环遍历键值对,用键值对的name(和字段的名字相同)推算setter的函数名,然后去寻找setter的入口引用。第一次是调用类反射的getMethod()函数,以后是从缓存里面检索,如果存在无效键值对,那就必然出现空转循环,哪怕是V2版代码,ignoreMap也不能避免这种空转循环。虽然单次空转循环耗时非常短,但在无效键值对比较多、负载很大的情况下,依然有无效的资源开销。
如果采用逆向思维,用setter去反推、检索键值对,又会如何?
先分析业务场景以及由业务场景所决定的数据结构特点:
- 接口类的字段数量可能大于setter函数的数量,因为可能需要一些内部使用的功能性字段,并不是从xml报文里解析出来的;
- xml报文里解析出的键值对和字段是交集关系,多数情况下,键值对的数量包含了接口类的字段,并且大概率存在一些不需要的键值对;
- 相比较字段,setter函数和需要解析的键值对最接近于一一对应关系,出现空转循环的概率最小;
- 因为接口类编写要遵守JAVA编程规范,从setter函数的名字反推字段的名字,进而检索键值对,是可行、可靠的。
综上所述,逆向思维用setter函数反推、检索键值对,初始化接口类,就是第二次迭代的具体方向。
需要把接口类修改成这样的结构(标红的部分是新增或者修改):


1)为了便于逆向检索键值对,nodes字段改成HashMap,key是键值对的名字、value是键值对的值。
2)为了提高循环遍历的速度,setterMap的第二层改成链表,链表的成员是内部类FieldSetter,结构如下:
private class FieldSetter { private String name; private Method method; public String getName() { return name; } public Method getMethod() { return method; } public void setMethod(Method method) { this.method = method; } public FieldSetter(String name, Method method) { super(); this.name = name; this.method = method; } }
setterMap的第二层继续使用HashMap也能实现功能,但循环遍历的效率,HashMap不如链表,所以我们改用链表。
3)同样的,setterMap在基类被加载的时候创建(内容为空):
static { setterMap = new HashMap<String, List<FieldSetter>>(); }
4)第一次初始化某个接口类的实例时,调用initSetters()函数,初始化setterMap:
protected List<FieldSetter> initSetters() { String className = this.getClass().getName(); List<FieldSetter> setters = new ArrayList<FieldSetter>(); // 遍历类的可调用函数 for (Method method: this.getClass().getMethods()) { String methodName = method.getName(); // 如果从名字推断是setter函数,添加到setter函数列表 if (methodName.startsWith("set")) { // 反推field的名字 String fieldName = StringUtils.lowerFirstChar(methodName.substring(3)); setters.add(new FieldSetter(fieldName, method)); } } // 缓存类的setter函数列表 setterMap.put(className, setters); // 返回可调用的setter函数列表 return setters; }
5)Initialize()函数修改为如下逻辑:
public void initialize() { // 从缓存获取接口类的setter列表 List<FieldSetter> setters = setterMap.get(this.getClass().getName()); // 如果还没有缓存、初始化接口类的setter列表 if (setters == null) setters = this.initSetters(); // 遍历接口类的setter for (FieldSetter setter: setters) { // 用setter的名字(也就是字段的名字)检索键值对 String fieldName = setter.getName(); String fieldValue = nodes.get(fieldName); // 没有检索到键值对、或者键值对没有赋值,跳过 if (StringUtils.isEmpty(fieldValue)) continue; try { Method method = setter.getMethod(); // 用类反射方式调用setter method.invoke(this, fieldValue); } catch (IllegalAccessException | IllegalArgumentException | InvocationTargetException e) { log.error("It\'s failed to initialize field: {}, reason: {}", fieldName, e); // 不能调用setter,可能是虚拟机回收了该子类的全部实例、入口地址变化,更新地址、再试一次 try { Method method = this.getSetter(fieldName); setter.setMethod(method); method.invoke(this, fieldValue); } catch (Exception e1) { log.debug("It\'s failed to initialize field: {}, reason: {}", fieldName, e1); } } catch (Exception e) { log.error("It\'s failed to initialize field: {}, reason: {}", fieldName, e); } } }
不妨把这版代码称为V3……继续沿用前面TestInvoke的例子,分析改进后代码的工作流程:
1)第一次执行initialize()函数,实例的状态是这样变化的:

通过setterMap反向检索键值对的值,fieldX、fieldY因为不存在对应的setter,不会被检索,避免了空转。
2)之后每一次初始化对象实例,都不需要再初始化setterMap,也不会消耗任何资源去检索fieldX、fieldY,最大限度地节省资源开销。
3)因为取消了ignoreMap,取消了V2版判断字段是否应该被忽略的逻辑,代码更简洁,也能节约一部分资源。
结果数据显示:用TestInvoke测试类、8个setter+2个无效键值对的情况下,进行100万/10万个实例两个量级的对比测试,V3版比V2版性能最多提高10%左右,100万实例初始化耗时550~720毫秒。如果增加无效键值对的数量,性能提高更为明显;没有无效键值对的最理想情况下,V1、V2、V3版本的代码效率没有明显差别。
至此,用缓存机制优化类反射代码的尝试,已经比较接近最优解了,V3版本的代码可以视为到目前为止最好的版本。
总结和思考:方法论
总结过去两年围绕着JAVA类反射性能优化这个课题,我们所进行的探索和研究,提高到方法论层面,可以提炼出一个分析问题、解决问题的思路和流程,供大家参考:
1)从实践中来
多数情况下,探索和研究的课题并不是坐在书斋里凭空想出来的,而是在实际工作中遇到具体的技术难点,在现实需求的驱动下发现需要研究的问题。
以本文为例,如果不是在对接银行核心系统的时候遇到了大量的、格式奇特的xml报文,不会促使我们尝试用类反射技术去优雅地解析报文,也就不会面对类反射代码执行效率低的问题,自然不会有后续的研究成果。
2)拿出手术刀,解剖一只麻雀
在实践中遇到了困难,首先要分析和研究面对的问题,不能着急,要有解剖一只麻雀的精神,抽丝剥茧,把问题的根源找出来。
这个过程中,逻辑分析和实操验证都是必不可少的。没有高屋建瓴的分析,就容易迷失大方向;没有实操验证,大概率会陷入坐而论道、脑补的怪圈。还是那句话:实践是最宝贵的财富,也是验证一切构想的终极考官,是我们认识世界改造世界的力量源泉。但我们也不能陷入庸俗的经验主义,不管怎么说,这个世界的基石是有逻辑的。
回到本文的案例,我们一方面研究JAVA内存模型,从理论上探寻类反射代码效率低下的原因;另一方面也在实务层面,用实实在在的时间戳验证了JAVA类反射代码的耗时分布。理论和实践的结合,才能让我们找到解决问题的正确方向,二者不可偏废。
3)头脑风暴,勇于创新
分析问题,找到关键点,接下来就是寻找解决方案。JAVA程序员有一个很大的优势,同时也是很大的劣势:第三方解决方案非常丰富。JAVA生态比较完善,我们面临的麻烦和问题几乎都有成熟的第三方解决方案,“吃现成的”是优势也是劣势,很多时候,我们的创造力也因此被扼杀。所以,当面临高价值需求的时候,应该拿出大无畏的勇气,啃硬骨头,做底层和原创的工作。
就本文案例而言,ReflexASM就是看起来很不错的方案,比传统的类反射代码性能提升了至少三分之一。但是,它真的就是最优解么?我们的实践否定了这一点。JAVA程序员要有吃苦耐劳、以底层技术为原点解决问题的精神,否则你就会被别人所绑架,失去寻求技术自由空间的机会
以上是关于如何利用缓存机制实现JAVA类反射性能提升30倍的主要内容,如果未能解决你的问题,请参考以下文章