iLogtail 与Filebeat 性能对比
Posted 阿里云云栖社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iLogtail 与Filebeat 性能对比相关的知识,希望对你有一定的参考价值。
简介:前段时间, iLogtail 阿里千万实例可观测采集器开源,其中介绍了iLogtail采集性能可以达到单核100MB/s,相比开源采集Agent有5-10倍性能优势。很多小伙伴好奇iLogtail具体的性能数据和资源消耗如何,本文将针对目前业界使用度较高且性能相对较优的Agent FileBeat进行对比,测试这两个Agent在不同压力场景下的表现如何。


作者 | 少旋
来源 | 阿里技术公众号
一 前言
前段时间, iLogtail [1]阿里千万实例可观测采集器开源,其中介绍了iLogtail采集性能可以达到单核100MB/s,相比开源采集Agent有5-10倍性能优势。很多小伙伴好奇iLogtail具体的性能数据和资源消耗如何,本文将针对目前业界使用度较高且性能相对较优的Agent FileBeat进行对比,测试这两个Agent在不同压力场景下的表现如何。
二 测试试验描述
随着Kubernetes 普及,Kubernetes 下的日志收集的需求也日益常态化,因此下文将分别进行容器标准输出流采集与容器内静态文件采集对比试验(使用静态文件采集的小伙伴可以参考容器内静态文件采集对比试验, iLogtail 纯静态文件采集会略优于试验2容器内文件静态采集),试验项具体如下:
- 实验1:恒定采集配置4,Filebeat & iLogtail 在原始日志产生速率 1M/s、2M/s、 3M/s 下的标准输出流采集性能对比。
- 实验2:恒定采集配置4,Filebeat & iLogtail 在原始日志产生速率 1M/s、2M/s、 3M/s 下的容器内文件采集性能对比。
而在真实的生产环境中,日志采集组件的可运维性也至关重要,为运维与后期升级便利,相比于Sidecar模式,K8s下采用Daemonset模式部署采集组件更加常见。但由于Daemonset 同时将整个集群的采集配置下发到各个采集节点的特性,单个采集节点正在工作的配置必定小于全量采集配置数目,因此我们还会进行以下2部分试验,验证采集配置的膨胀是否会影响采集器的工作效率:
- 实验3:恒定输入速率3M/s,Filebeat & iLogtail 在采集配置50、100、500、1000 份下的标准输出流采集性能对比。
- 实验4:恒定输入速率3M/s,Filebeat & iLogtail 在采集配置50、100、500、1000 份下的容器内文件采集性能对比。
- 实验5:iLogtail 在 5M/s、10M/s、10M/s、40M/s 下的标准输出流采集性能。
- 实验6:iLogtail 在 5M/s、10M/s、10M/s、40M/s 下的容器内文件采集性能。
三 试验环境
所有采集环境数据存储于[2], 感兴趣的同学可以自己动手进行整个对比测试实验, 以下部分分别描述了不同采集模式的具体配置,如果只关心采集对比结果,可以直接跳过此部分继续阅读。
1 环境
运行环境:阿里云ACK Pro 版本
节点配置:ecs.g6.xlarge (4 vCPU 16GB) 磁盘ESSD
底层容器:Containerd
iLogtail版本:1.0.28
FileBeat版本:v7.16.2
2 数据源
对于数据源,我们首先去除因正则解析或多行拼接能力带来的差异,仅仅以最基本的单行采集进行对比,数据产生源模拟产生nginx访问日志,单条日志大小为283B,以下配置描述了1000条/s 速率下的输入源:
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-demo-0
namespace: default
spec:
template:
metadata:
name: nginx-log-demo-0
spec:
restartPolicy: Never
containers:
- name: nginx-log-demo-0
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--path=/var/log/medlinker/access.log", "--total-count=1000000000", "--log-file-size=1000000000", "--log-file-count=2", "--logs-per-sec=1000"]
volumeMounts:
- name: path
mountPath: /var/log/medlinker
subPath: nginx-log-demo-0
resources:
limits:
memory: 200Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: path
hostPath:
path: /testlog
type: DirectoryOrCreate
nodeSelector:
kubernetes.io/hostname: cn-beijing.192.168.0.1403 Filebeat 标准输出流采集配置
Filebeat 原生支持容器文件采集,通过add_kubernetes_metadata组件增加kubernetes 元信息,为避免输出组件导致的性能差异,通过drop_event插件丢弃数据,避免输出,filebeat测试配置如下(harvester_buffer_size 调整设置为512K,filebeat.registry.flush: 30s,queue.mem 参数适当扩大,增加吞吐):
filebeat.yml: |-
filebeat.registry.flush: 30s
processors:
- add_kubernetes_metadata:
host: $NODE_NAME
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- drop_event:
when:
equals:
input.type: container
output.console:
pretty: false
queue:
mem:
events: 4096
flush.min_events: 2048
flush.timeout: 1s
max_procs: 4
filebeat.inputs:
- type: container
harvester_buffer_size: 524288
paths:
- /var/log/containers/nginx-log-demo-0-*.log4 Filebeat 容器文件采集配置
Filebeat 原生不支持容器内文件采集,因此需要人工将日志打印路径挂载于宿主机HostPath,这里我们使用 subPath以及DirectoryOrCreate功能进行服务打印路径的分离, 以下为模拟不同服务日志打印路径独立情况。

iLogtail 原生同样支持标准输出流采集,service_docker_stdout 组件已经会提取kubernetes 元信息,为避免输出组件导致的性能差异,通过processor_filter_regex,进行所有日志的过滤,测试配置如下:
"inputs":[
"detail":
"ExcludeLabel":
,
"IncludeLabel":
"io.kubernetes.container.name":"nginx-log-demo-0"
,
"type":"service_docker_stdout"
],
"processors":[
"type":"processor_filter_regex",
"detail":
"Exclude":
"_namespace_":"default"
]
6 iLogtail 容器文件采集配置
iLogtail 原生支持容器内文件采集,但由于文件内采集元信息存在于tag标签,暂无过滤插件,为避免输出组件导致的性能差异,因此我们使用空输出插件进行输出,测试配置如下:
四 Filebeat与iLogtail对比测试
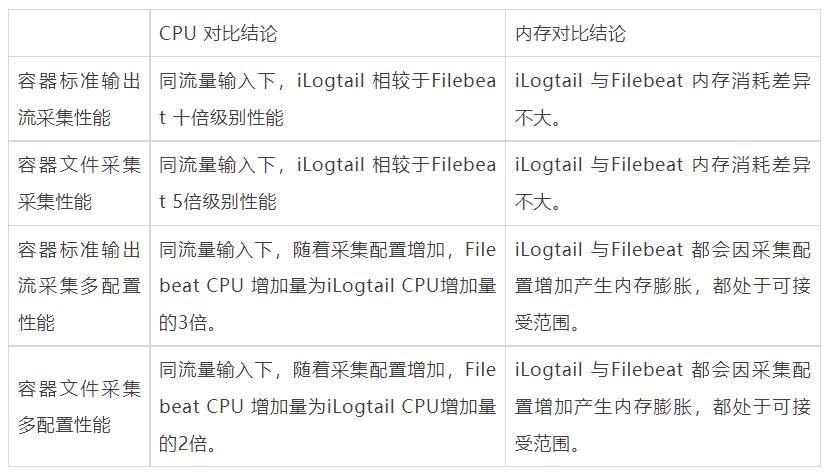
Filebeat 与 iLogtail 的对比项主要包含以下内容:标准输出流采集性能、容器内文件采集性能、标准输出流多用户配置性能、容器内文件多用户配置性能以及大流量采集性能。
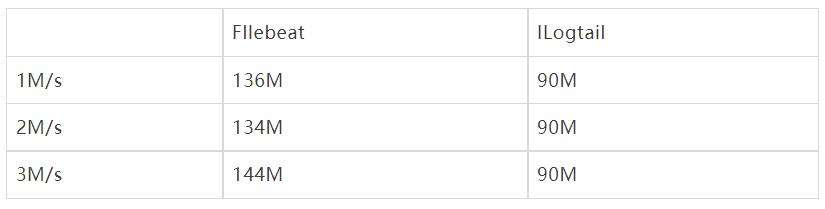
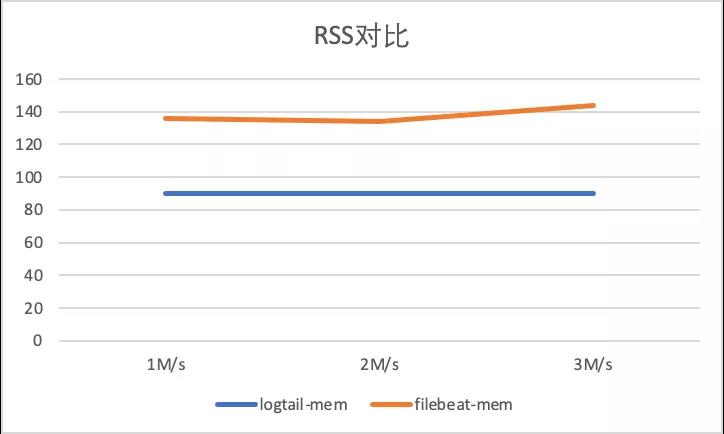
1 标准输出流采集性能对比
输入数据源: 283B/s, 底层容器contianerd,标准输出流膨胀后为328B, 共4个输入源:
- 1M/s 输入日志3700条/s,
- 2M/s 输入日志7400条/s,
- 3M/s 输入日志条11100条/s。
以下显示了标准输出流不同采集的性能对比,可以看到iLogtail相比于Filebeat 有十倍级的性能优势(CPU的百分比为单核的百分比):


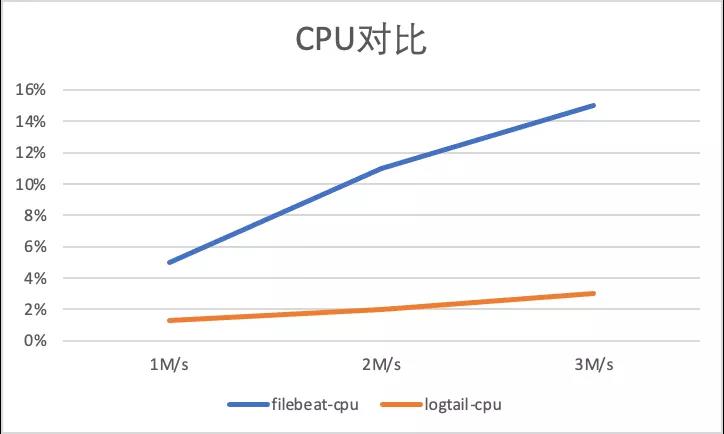
输入数据源: 283B/s, 共4个输入源:
- 1M/s 输入日志3700条/s,
- 2M/s 输入日志7400条/s,
- 3M/s 输入日志条11100条/s。
以下显示了容器内文件不同采集的性能对比,Filebeat 容器内文件由于与container 采集共用采集组件,并省略了Kubernets meta 相关组件,所以相比于标准输出流采集有大性能提升,iLogtail 的容器内文件采集采用Polling + inotify机制,同样相比于容器标准输出流采集有性能提升, 但可以看到iLogtail相比于Filebeat 有5倍级的性能优势(CPU的百分比为单核的百分比):


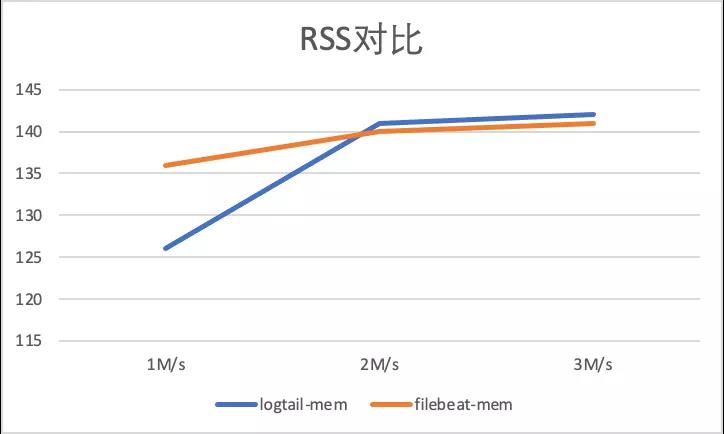
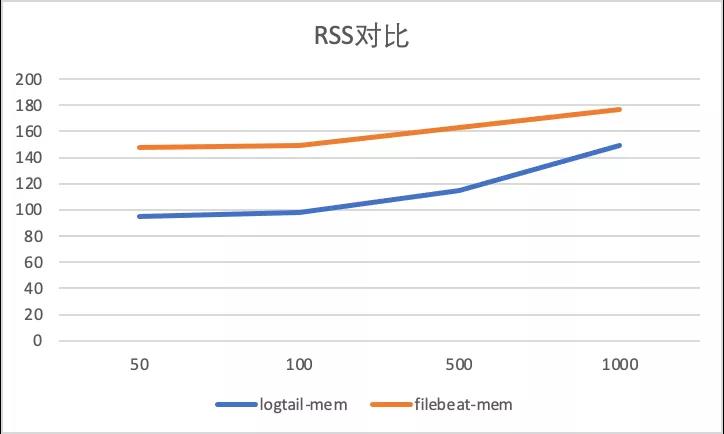
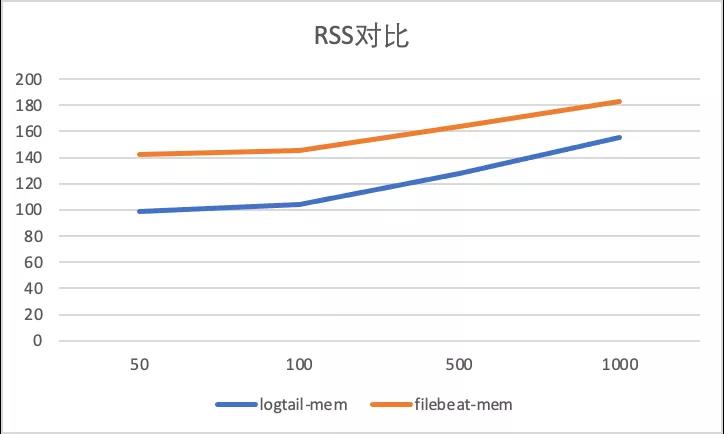
采集配置膨胀性能对比,输入源设置为4,总输入速率为3M/s, 分别进行50采集配置,100采集配置,500采集配置,1000采集配置 对比。
标准输出流采集配置膨胀对比
以下显示了标准输出流不同采集的性能对比,可以看到Filebeat 由于容器采集与静态文件采集底层共用相同静态文件采集逻辑,会在标准输出流采集路径var/log/containers下存在大量正则匹配的工作,可以看到虽然采集数据量没有增加由于采集配置的增加,CPU消耗增加10%+,而iLogtail 针对容器采集模型全局共享容器路径发现机制,所以避免了正则逻辑带来的性能损耗(CPU的百分比为单核的百分比)。
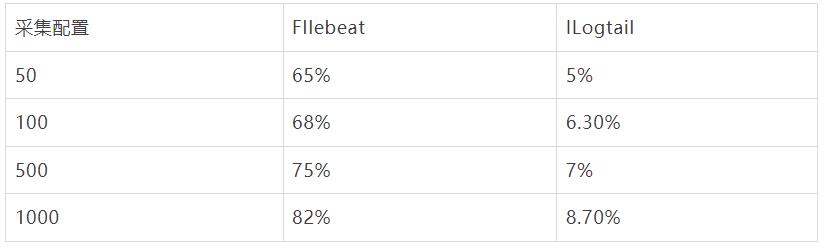
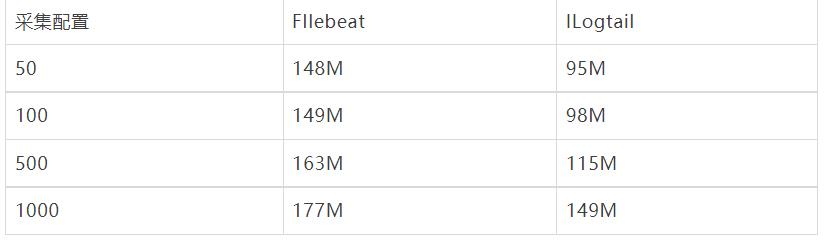
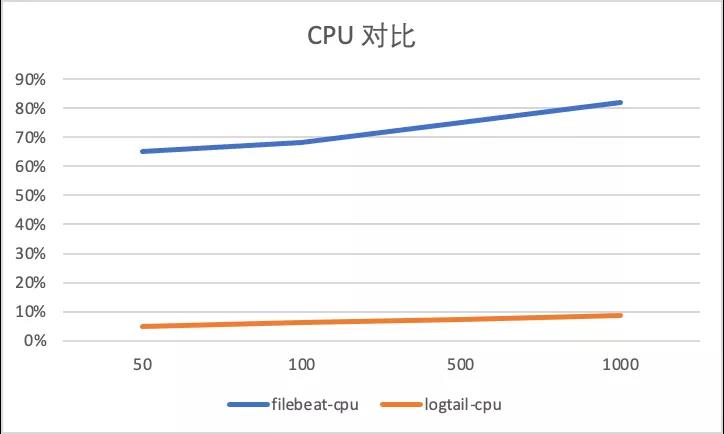
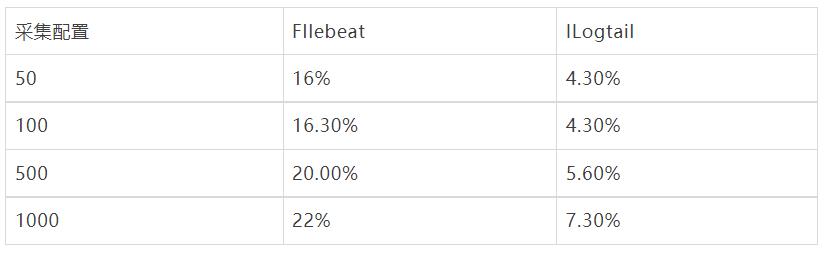
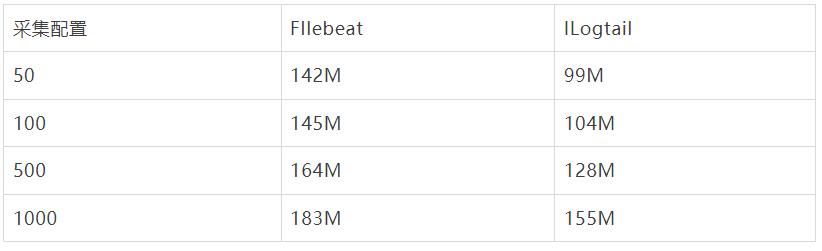
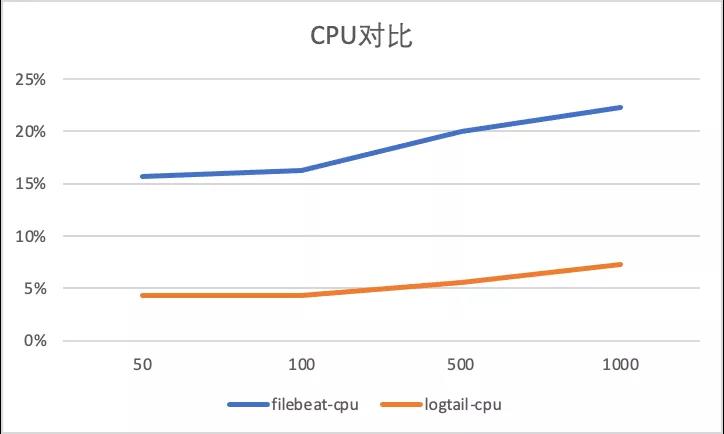
容器内文件采集配置膨胀对比
以下显示了容器内文件采集不同采集器的性能对比,可以看到Filebeat 静态文件采集由于避免标准输出流通用路径正则,相较于标准增加CPU消耗较少,而iLogtail CPU 变化同样很小,且相比于标准输出流采集性能略好(CPU的百分比为单核的百分比)。
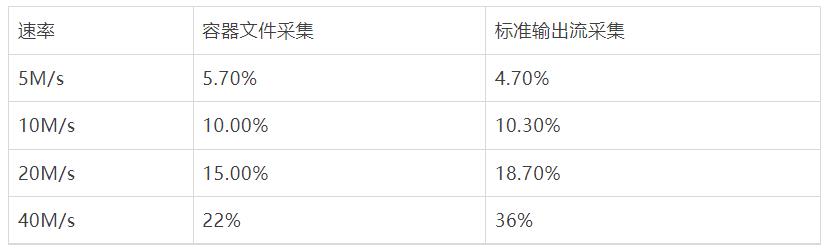
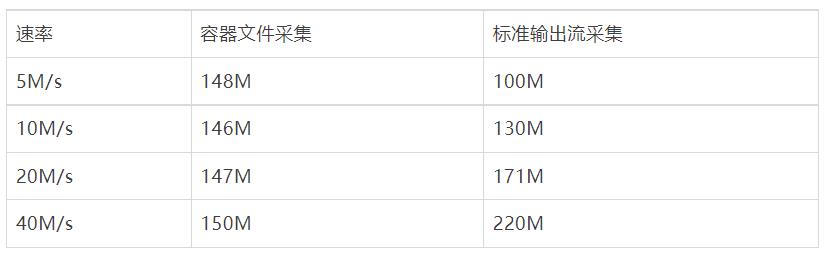
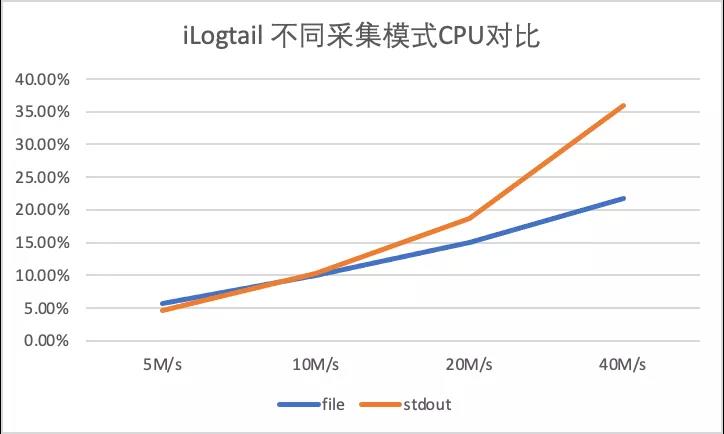
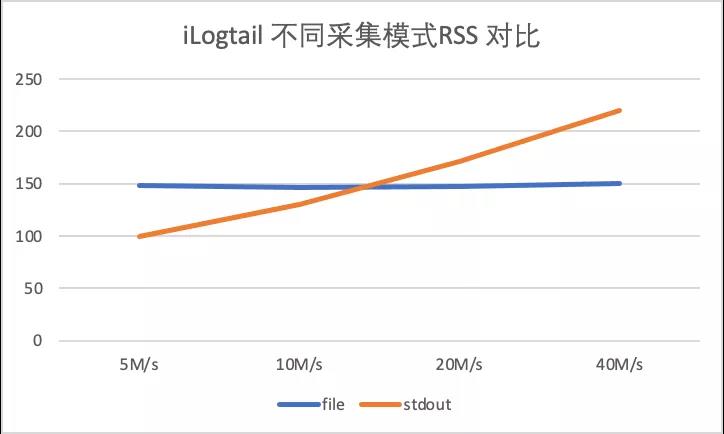
由于FileBeat在日志量大的场景下出现采集延迟问题,所以以下场景仅针对iLogtail进行测试,分别在5M/s、10M/s、20M/s 下针对iLogtail 进行容器标准输出流采集与容器内文件采集的性能压测。
- 输入源数量:10
- 单条日志大小283B
- 5M/s 对应日志速率 18526条/s,单输入源产生速率1852条/s
- 10M/s 对应日志速率 37052条/s,单输入源产生速率3705条/s
- 20M/s 对应日志速率 74104条/s,单输入源产生速率7410条/s
- 40M/s 对应日志速率 148208条/s,单输入源产生速率14820条/s
和上述试验类似可以看到CPU消耗方面容器文件采集略好于容器标准输出流采集性能(CPU的百分比为单核的百分比),主要是由于容器文件采集底层Polling + inotify机制。
五 为什么Filebeat 容器标准输出与文件采集差异巨大?
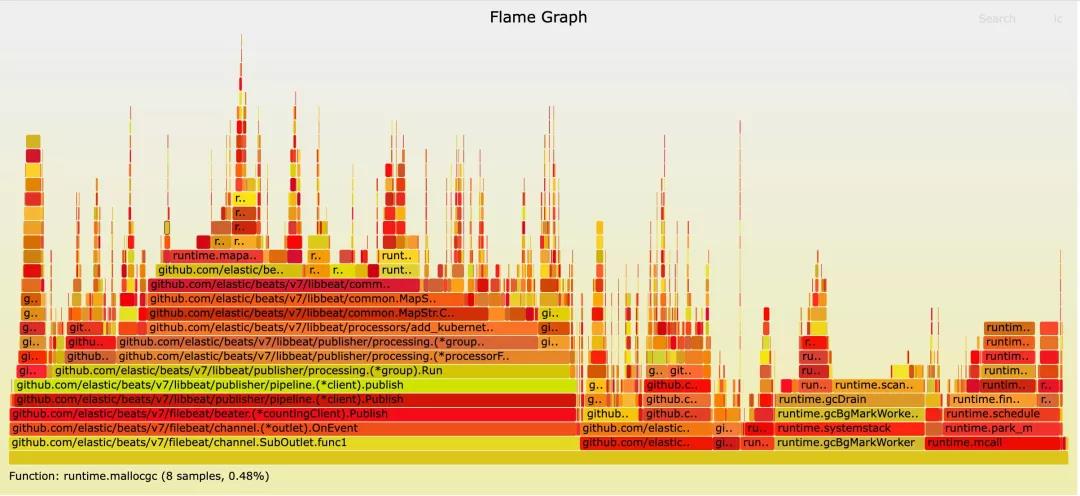
通过上述试验可以看到FIlebeat 在不同工作模式下有较大的CPU差异,通过dump 容器标准输出流采集的pprof 可以得到如下火焰图,可以看到Filebeat 容器采集下的add_kubernets_meta 插件是性能瓶颈,同时FIlebeat 的add_kubernets_meta 采用与每个节点监听api-server 模式,也存在api-server 压力问题。
六 iLogtail DaemonSet 场景优化
通过以上对比,可以看到iLogtail 相比于Filebeat 具有了优秀的内存以及CPU 消耗,有小伙伴可能好奇iLogtail 拥有如此极致性能背后原因,下文主要讲解iLogtail Daemonset 场景下的优化,如何标准输出流相比于FIlebeat 拥有10倍性能。
首先对于标准输出流场景,相比于其他开源采集器,例如Filebeat 或Fluentd。一般都是通过监听var/log/containers 或 /var/log/pods/ 实现容器标准输出流文件的采集,比如/var/log/pods/ 的路径结构为: /var/log/pods/_<pod_name>_<pod_id>/<container_name>/, 通过此路径复用物理机静态文件采集模式进行采集。

- 采集路径不在依赖于静态配置路径,可以靠容器标签动态选择采集源,从而简化用户接入成本。
- 可以根据容器元信息探测容器自动挂载节点的动态路径,所以iLogtail 无需挂载即可采集容器内文件,而如Filebeat 等采集器需要将容器内路径挂载于宿主机路径,再进行静态文件采集。
- 对于新接入采集配置复用历史容器列表,快速接入采集,而对于空采集配置,由于容器发现全局共享机制的存在,也就避免了存在空轮训监听路径机制的情况,进而保证了在容器这样动态性极高的环境中,iLogtail 可运维性的成本达到可控态。

七 结语
综上所述,在动态性极高的Kubernetes 环境下,iLogtail不会因为采用Daemonset 的部署模型带来的多配置问题,造成内存大幅度膨胀,而且在静态文件采集方面,iLogtail 拥有5倍左右的性能优势,而对于标准输出流采集,由于iLogtail 的采集机制,iLogtail 拥有约10倍左右的性能优势。但是相比于Filebeat 或Fluentd 等老牌开源产品,在文档建设与社区建设上还欠缺很多,欢迎对iLogtail 感兴趣的小伙伴一起参与进来,共同打造易用且高性能的iLogtail产品。
参考文献
- Logtail技术分享一
- Logtail技术分享二
- Filebeat 配置
- Filebeat 容器化部署
- iLogtail 使用指南
本文为阿里云原创内容,未经允许不得转载。
以上是关于iLogtail 与Filebeat 性能对比的主要内容,如果未能解决你的问题,请参考以下文章
iLogtail 社区版使用入门 - 采集 MySQL Binlog