千万级可观测数据采集器 - iLogtail代码完整开源
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了千万级可观测数据采集器 - iLogtail代码完整开源相关的知识,希望对你有一定的参考价值。

2022年6月29日,阿里云iLogtail开源后迎来首次重大更新,正式发布完整功能的iLogtail社区版。本次更新开源全部C++核心代码,该版本在内核能力上首次对齐企业版,开发者可以构建出与企业版性能相当的iLogtail云原生可观测性数据采集器。本次发布新增日志文件采集、容器文件采集、无锁化事件处理、多租户隔离、基于Pipeline的新版配置方式等诸多重要特性,全面增强社区版的易用性和性能,欢迎广大开发者关注、共建。
可观测性数据采集挑战
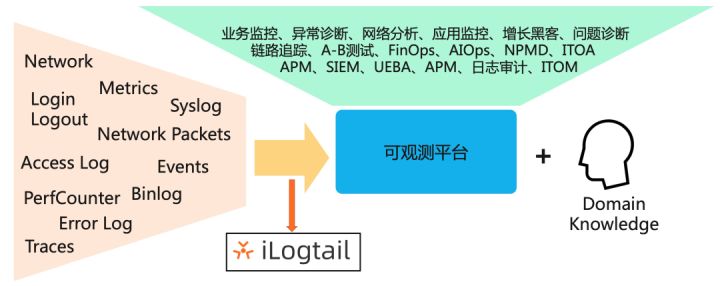
可观测性是通过检查其输出来衡量系统内部状态的能⼒。该术语起源于⼏⼗年前的控制理论,最早是匈牙利裔工程师鲁道夫·卡尔曼提出。在分布式IT系统中,可观测性典型使⽤种类型的遥测数据⸺⽇志、指标和跟踪来度量基础设施、平台和应用程序,以了解他们的运行状态和过程。这些数据的收集通常由一个与被观测对象共同运行的采集Agent完成。基于云原生和微服务的现代系统架构下,这些观测对象比以往分布更加分散,数量更多且变化更快,使得采集Agent面临如下挑战:
- 高性能,低开销:现代应用程序通常在数据中心、公共云和边缘处汇集了数以千计的服务器、虚拟机、容器中运行,采集Agent的每一点性能开销都会被数以千计地放大。目前众多开源Agent的设计更多的是偏重功能而非性能,单核处理性能普遍在2-10M/s左右,而我们希望能达到单核100M/s的性能。在采集目标增加、数据量增加、采集延迟、服务端异常等情况下,开源Agent内存都会呈现爆炸式增长,而我们希望即使在各种环境下,内存也能处在较低的水位。
- 采集稳定准确,故障多级隔离:可观测性需要比被观测的系统至少可靠一个数量级。数据采集Agent的稳定性,除了保证数据本身采集的准确性外,还需要保证不能影响业务应用,否则将带来灾难性的后果。另一方面,无论怎样出现问题,都需要尽可能的隔离问题,例如一个Agent上有多个采集配置,一个配置出问题,不能影响其他配置。
- 大规模配置企业级管控:可观测数据的应用范围广泛,一个企业内部往往存在大量配置,需要Agent支持中心化、自动化配置管理能力,代替手工登录机器修改配置的方式,并且能够保证配置Reload期间数据不丢不重。当Agent有多个采集配置时,合理安排资源,既要优先把内存带宽等资源供给高优先级配置,又要确保低优先级的配置不被“饿死”,其需要在波峰过后有足够的Burst能力快速追齐数据。
- 更原生友好的K8s支持:K8s提供了强悍的运维部署、弹性伸缩、故障恢复能力,极大地便利了分布式系统的开发和管理,然而日志采集的问题也随之而来。K8s多样的数据输出使得同一个Agent需要同时支持采集宿主机日志、容器内日志、容器stdout等多种数据源。K8s的对业务部署的弹性伸缩能力,要求Agent具备容器动态发现、打标的能力,同时也对如何保证数据采集完整性提出了更高的要求。
由于尚无完美解决以上挑战的开源Agent,我们选择自研iLogtail。iLogtail的核心定位就是可观测数据的采集器,帮助开发者构建统一的业务数据采集层,助力可观测平台打造各种上层的应用场景。
iLogtail简介
iLogtail是阿里云日志服务(SLS)团队自研的可观测数据采集Agent,拥有的轻量级、高性能、自动化配置等诸多生产级别特性,可以署于物理机、虚拟机、Kubernetes等多种环境中来采集遥测数据。iLogtail在阿里云上服务了数万家客户主机和容器的可观测性采集工作,在阿里巴巴集团的核心产品线,如淘宝、天猫、支付宝、菜鸟、高德地图等也是默认的日志、监控、Trace等多种可观测数据的采集工具。目前iLogtail已有千万级的安装量,每天采集数十PB的可观测数据,广泛应用于线上监控、问题分析/定位、运营分析、安全分析等多种场景,在实战中验证了其强大的性能和稳定性。
iLogtail发展历程
iLogtail的前身源自阿里云的神农项目,自从2013年正式孵化以来,iLogtail始终在不断演进。
诞生初期,面对阿里云自身和早期客户运维和可观测性需求,iLogtail主要解决的是从单机、小规模集群到大规模的运维监控挑战,此时的iLogtail已经具备了基本的文件发现和轮转处理能力,可以实现日志、监控实时采集,抓取毫秒级延迟,单核处理能力约为10M/s。通过Web前端可支持中心化配置文件自动下发,支持3W+部署规模,上千采集配置项,实现日10TB数据的高效采集。
2015年,阿里巴巴开始推进集团和蚂蚁金服业务上云,面对近千个团队、数百万终端、以及双11、双12等超大流量数据采集的挑战,iLogtail在功能、性能、稳定性和多租户支持方面都需要进行巨大的改进。至2017年前后,iLogtail已经具备了正则、分隔符、JSON等多个格式日志的解析能力,支持多种日志编码方式,支持数据过滤、脱敏等高级处理能力,单核处理能力极简模式下提升到100M/s,正则、分隔符、JSON等方式20M/s+。采集可靠性方面,增加文件发现Polling方式兜底、轮转队列顺序保证、日志清理丢失保护、CheckPoint增强;进程可靠性方面,增加异常自动恢复、Crash自动上报、守护进程等。通过全流程多租户隔离、多级高低水位队列、配置级/进程级流量控制、临时降级等机制,支持百万+部署规模,千级别租户,10万+采集配置项,实现日PB级数据的稳定采集。
随着阿里推进核心业务全面上云,以及iLogtail所属日志服务(SLS)正式在阿里云上商业化,iLogtail开始全面拥抱云原生。面对多元的云上环境、迅速发展的开源生态和大量涌入的行业客户需求,iLogtail的发展的重心转移到解决如何适应云原生、如何兼容开源协议和如何去处理碎片化需求等问题上。2018年iLogtail正式支持docker容器采集,2019年支持containerd容器采集,2020年全面升级Metric采集,2021年增加Trace支持。通过全面支持容器化、K8S Operator管控和可扩展插件系统,iLogtail支持千万部署规模,数万内外部客户,百万+采集配置项,实现日数十PB数据的稳定采集。
2021年11月iLogtail迈出了开源的第一步,将Golang插件代码开源。自开源以来,吸引了数百名开发者的关注,并且也有不少开发者贡献了processor跟flusher插件。今天,C++核心代码也正式开源了,自此开发者可以基于该版本构建完整的云原生可观测数据采集方案。

iLogtail优势
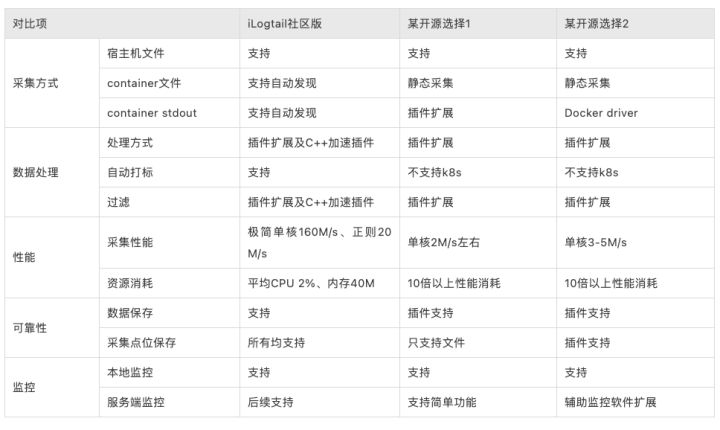
对于可观测数据的采集,有很多开源的采集器,例如Logstash、Fluentd、Filebeats等。这些采集器的功能非常丰富,但在性能、稳定性、管控能力等关键特性方面iLogtail因其独特设计而具备优势。
C++内核重要特性
本次iLogtail C++内核开源全面对齐企业版功能特性,并新增基于Pipeline的极简采集配置项提升社区版易用性。
日志文件采集
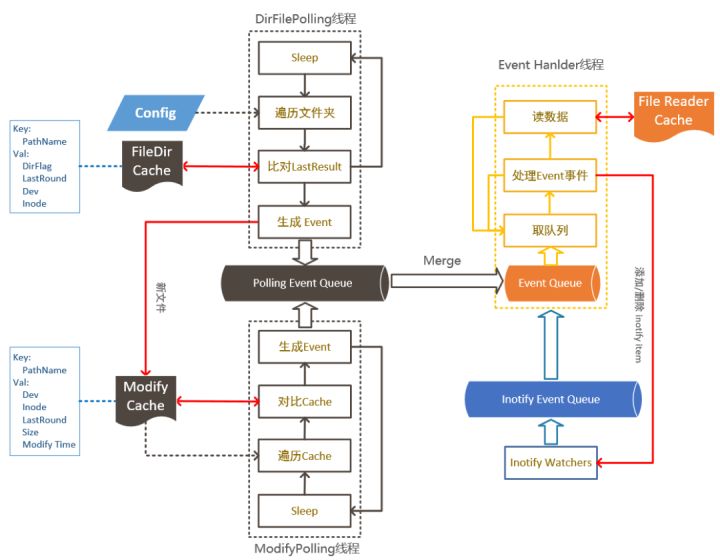
C++核心源代码包含了功能完整的文件发现机制,可以支持通配符和多层次目录的动态日志文件监控,并支持日志轮转、日志数、轮转大小设置。iLogtail在Linux下使用inotify作为文件监控的主要手段,提供了毫秒级延时的数据发现能力,同时为了兼顾不同操作系统以及支持各类特殊采集场景,iLogtail同时使用了轮询作为的数据的发现方式。通过使用轮询与事件并存的混合方式,iLogtail打造了一套兼具性能优势同时不失鲁棒性的文件发现机制。
容器文件采集
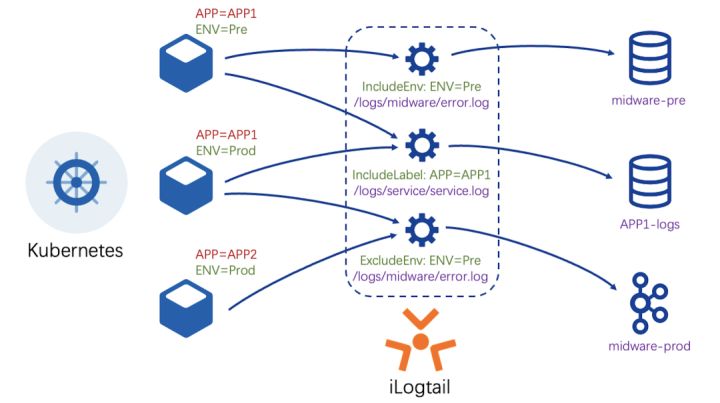
iLogtail C++内核与插件系统配合可支持全场景的容器数据采集。iLogtail通过插件发现节点的容器列表并维护容器和日志采集路径映射,结合C++内核高效的文件采集能力提供了极致的容器数据采集体验。iLogtail支持使用容器标签、环境变量、K8s标签、Pod名称、命名空间等多种方式进行容器筛选,为用户提供了便利的采集源配置能力。支持DaemonSet、Sidecar、CRD等多种部署方式,为应对不同使用场景提供了灵活的部署能力。而iLogtail采用全局容器列表和通过Kubernetes CRI协议获取容器信息的设计,使其在权限和组件依赖上相比其他开源更加轻量级,并且拥有更高的采集效率。
无锁化事件处理
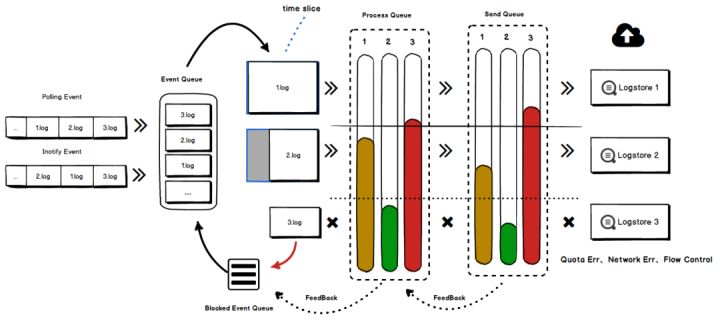
iLogtail实现如此高吞吐的秘诀之一是使用了无锁化事件处理模型。与业界其他开源Agent为每个配置分配独立线程/Goroutine读取数据不同,iLogtail数据的读取只配置了一个线程。由于数据读取的瓶颈并不在于计算而是磁盘,单线程足以完成所有配置的事件处理以及数据读取。使用单线程使得iLogtail的事件处理和数据读取都可以在无锁环境下运行,数据结构更加轻量化,从而取得了相对多线程处理更优的性价比。
多租户隔离
在生产环境中,一台服务存在数百个采集配置属于常态,每个配置的优先级、日志产生速度、处理方式、上传目的地址等都有可能不同,因此必须有效解决如何隔离各种自定义配置,保证采集配置QoS不因部分配置异常而受到影响的问题。iLogtail采用基于时间片的采集调度、多级高低水位反馈队列、事件非阻塞处理、流控/停采策略以及配置动态更新等多项关键技术,融合实现了兼具隔离性、公平性、可靠性、可控性、性价比五大特性的多租户隔离方案。经历了多年双11流量高峰期的考验,这套方案已经被证明相比其他开源具备较大的稳定性和性价比优势。
基于Pipeline的新版配置方式
简洁直观的配置文件对于Agent的使用至关重要,iLogtail早期几乎全部依赖图形化配置方式,默认的JSON配置文件臃肿冗余、难以理解。本次升级使用YAML格式,除了天然继承其可读性强、字符串转义少、支持多行文本、可添加注释的优点外,还根据iLogtail最近的数据流水线架构,将配置文件重新划分为inputs、processors、aggregators、flushers四个部分,注重功能配置淡化实现细节,并统一规范了配置项的命名规范,以进一步降低iLogtail的配置门槛。
一个最简配置示例:
enable: true
inputs:
- Type: file_log
LogPath: /log
FilePattern: simple.log
flushers:
- Type: flusher_stdout后续展望
2021年11月,我们开源了iLogtail功能最丰富、可扩展性最强的Golang插件部分,收到了大量开发者的关注和建议。累计收藏600+次,收到建议60+条,PR 120+次。C++核心模块是iLogtail在性能和资源占用上相比其他开源采集软件具备一定优势的主要因素,希望这次C++核心部分的开源能为更多的企业带来资源效率的进一步提升,同时丰富iLogtail的产品生态,吸引更多优秀开发者参与社区建设。
在当今云原生的时代,我们坚信开源才是iLogtail最优的发展策略,也是释放其最大价值的方法。iLogtail作为可观测领域最基础的软件,在各行各业仍然有许多不同场景有待发现。我们希望能够和开源社区一起共建,持续优化,争取成为世界一流的可观测数据采集器。
相关资料
GitHub: https://github.com/alibaba/ilogtail
社区版用户手册:https://ilogtail.gitbook.io/ilogtail-docs
企业版官网:https://help.aliyun.com/document_detail/65018.html
作者 | 迅飞、烨陌
本文为阿里云原创内容,未经允许不得转载。
以上是关于千万级可观测数据采集器 - iLogtail代码完整开源的主要内容,如果未能解决你的问题,请参考以下文章