RDD
Posted 能够一分耕耘一分收获已经是十足的幸运了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RDD相关的知识,希望对你有一定的参考价值。
RDD的基本性质
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。
-
弹性
- 存储的弹性:内存与磁盘的自动切换
- 容错的弹性:数据丢失可以自动恢复
- 计算的弹性:计算出错重试机制
- 分片的弹性:可根据需要重新分片
-
分布式
-
数据集:RDD封装了计算逻辑,不保存数据
-
数据抽象:RDD是一个抽象类,需要子类具体实现
-
不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑
-
可分区、并行计算
Spark 的作业管理
计算阶段划分的依据是 shuffle,不是转换函数的类型,有的函数有时候有 shuffle,有时候没有
Spark 里面的 RDD 函数有两种:
一种是转换函数,调用以后得到的还是一个 RDD,RDD 的计算逻辑主要通过转换函数完成
另一种是 action 函数,调用以后不再返回 RDD。比如count() 函数,返回 RDD 中数据的元素个数;saveAsTextFile(path),将 RDD 数据存储到 path 路径下。Spark 的 DAGScheduler 在遇到 shuffle 的时候,会生成一个计算阶段,在遇到 action 函数的时候,会生成一个作业(job)。
Spark 的执行过程
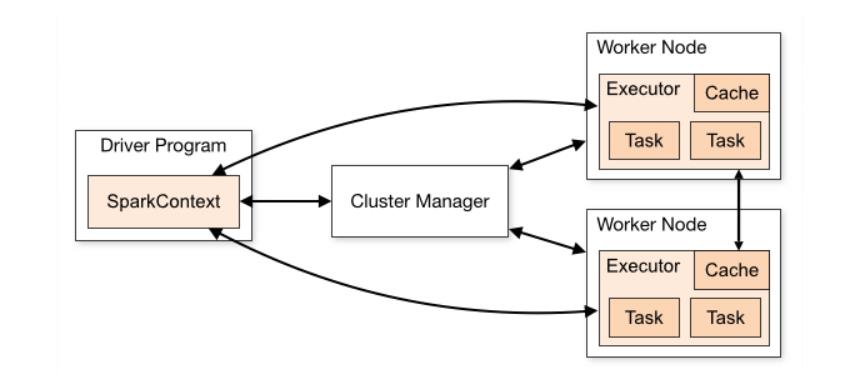
- Spark 应用程序启动在自己的 JVM 进程里,即 Driver 进程,启动后调用 SparkContext 初始化执行配置和输入数据。SparkContext 启动 DAGScheduler 构造执行的 DAG 图,切分成最小的执行单位也就是计算任务
- Driver 向 Cluster Manager 请求计算资源,用于 DAG 的分布式计算。Cluster Manager 收到请求以后,将 Driver 的主机地址等信息通知给集群的所有计算节点 Worker
- Worker 收到信息以后,根据 Driver 的主机地址,跟 Driver 通信并注册,然后根据自己的空闲资源向 Driver 通报自己可以领用的任务数。Driver 根据 DAG 图开始向注册的 Worker 分配任务。
- Worker 收到任务后,启动 Executor 进程开始执行任务。Executor 先检查自己是否有 Driver 的执行代码,如果没有,从 Driver 下载执行代码,通过 Java 反射加载后开始执行
以上是关于RDD的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之_19_Spark学习_02_Spark Core 应用解析+ RDD 概念 + RDD 编程 + 键值对 RDD + 数据读取与保存主要方式 + RDD 编程进阶 + Spark Cor