50.性能调优之重构RDD架构以及RDD持久化
Posted Erik_ly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了50.性能调优之重构RDD架构以及RDD持久化相关的知识,希望对你有一定的参考价值。
本文为《Spark大型电商项目实战》 系列文章之一,主要介绍重构RDD及持久化的原因及方法,并在代码中实现优化。
RDD架构重构与优化
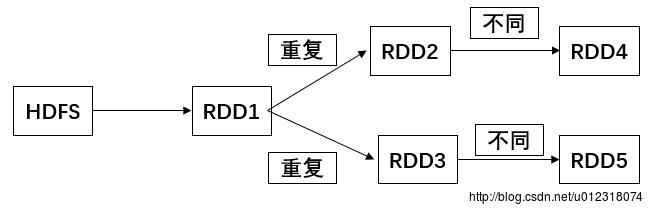
一种情况是从一个RDD到几个不同的RDD,算子和计算逻辑其实是完全一样的,结果因为人为的疏忽计算了多次,获取到了多个RDD。所以尽量去复用RDD,差不多的RDD可以抽取称为一个共同的RDD,供后面的RDD计算时,反复使用。
公共RDD一定要实现持久化
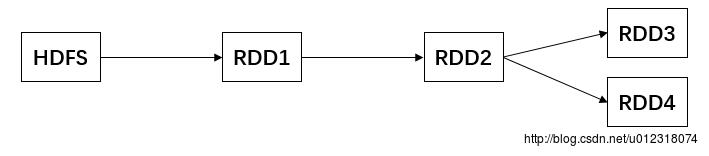
当第一次对RDD2执行算子,获取RDD3的时候,就会从RDD1开始计算,就是读取HDFS文件,然后对RDD1执行算子,获取到RDD2,然后再计算得到RDD3
默认情况下,多次对一个RDD执行算子,去获取不同的RDD都会对这个RDD以及之前的父RDD全部重新计算一次,计算过程为读取HDFS->RDD1->RDD2->RDD4。这种情况,是绝对绝对一定要避免的,一旦出现一个RDD重复计算的情况,就会导致性能急剧降低。比如,HDFS->RDD1-RDD2的时间是15分钟,那么此时就要走两遍,变成30分钟。
所以对于要多次计算和使用的公共RDD,一定要进行持久化。持久化是将RDD的数据通过BlockManager缓存到内存中/磁盘中,以后无论对这个RDD做多少次计算,都是直接取这个RDD的持久化的数据,比如从内存中或者磁盘中直接提取一份数据,过程示意图大致为:

持久化进行序列化
如果正常将数据持久化在内存中,那么可能会导致内存的占用过大,这样的话,也许会导致OOM(内存溢出)。
当纯内存无法支撑公共RDD数据完全存放的时候,就优先考虑使用序列化的方式在纯内存中存储。将RDD的每个partition的数据序列化成一个大的字节数组,就一个对象。序列化后,大大减少内存的空间占用。
序列化的方式,唯一的缺点就是,在获取数据的时候,需要反序列化。
如果序列化纯内存方式还是导致OOM(内存溢出),那就只能考虑磁盘的方式,内存+磁盘的普通方式(无序列化),如果还不行就要考虑内存+磁盘(序列化)的形式。
双副本机制进行持久化
为了数据的高可靠性,而且内存充足,可以使用双副本机制进行持久化。
如果持久化后的一个副本因为机器宕机了,副本丢了,就还是得重新计算一次。持久化的双副本机制持久化的每个数据单元,存储一份副本,放在其他节点上面,从而进行容错,一个副本丢了,不用重新计算,还可以使用另外一份副本。这种方式,仅仅针对你的内存资源极度充足的情况。
代码优化
重构 RDD
重构actionRDD
action是一个公共RDD, 第一,要用actionRDD获取一个公共的sesssionid为key的PairRDD;第二,actionRDD用在了session聚合环节里。
sessionid为key的PairRDD是确定在后面要多次使用, 与通过sessionid进行join获取通过筛选的session明细数据,将这个RDD直接传入aggregateBySession方法进行session聚合。重构完成后,actionRDD就只在最开始使用一次用来生成以sessionid为key的RDD。
将
private static JavaPairRDD<String, String> aggregateBySession(
SQLContext sqlContext, JavaRDD<Row> actionRDD) {
JavaPairRDD<String, Row> sessionid2ActionRDD = actionRDD.mapToPair(
new PairFunction<Row, String, Row>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, Row> call(Row row) throws Exception {
return new Tuple2<String, Row>(row.getString(2), row);
}
});
//对行为数据按照session粒度进行分组
JavaPairRDD<String, Iterable<Row>> sessionid2ActionsRDD =
sessionid2actionRDD.groupByKey();重构为
private static JavaPairRDD<String, String> aggregateBySession(
SQLContext sqlContext, JavaPairRDD<String, Row> sessionid2actionRDD) {
//对行为数据按照session粒度进行分组
JavaPairRDD<String, Iterable<Row>> sessionid2ActionsRDD =
sessionid2actionRDD.groupByKey();
将
JavaPairRDD<String, String> sessionid2AggrInfoRDD =
aggregateBySession(sqlContext, actionRDD);改为:
JavaPairRDD<String, String> sessionid2AggrInfoRDD =
aggregateBySession(sqlContext, sessionid2actionRDD);持久化
持久化 sessionid2actionRDD
因为 sessionid2actionRDD 使用了两次,所以要对 sessionid2actionRDD 进行持久化操作。
持久化只需对RDD调用persist()方法,并传入一个持久化级别即可。
persist(StorageLevel.MEMORY_ONLY()),纯内存,无序列化,可以用cache()方法来替代
StorageLevel.MEMORY_ONLY_SER(),纯内存,序列化,第二选择
StorageLevel.MEMORY_AND_DISK(),内存 + 磁盘,无序列号,第三选择
StorageLevel.MEMORY_AND_DISK_SER(),内存 + 磁盘,序列化,第四选择
StorageLevel.DISK_ONLY(),纯磁盘,第五选择
如果内存充足,要使用双副本高可靠机制, 选择后缀带_2的策略,比如:StorageLevel.MEMORY_ONLY_2()
在
JavaPairRDD<String, Row> sessionid2actionRDD = getSessionid2ActionRDD(actionRDD);后面添加
sessionid2actionRDD = sessionid2actionRDD.persist(StorageLevel.MEMORY_ONLY());即可。
持久化 filteredSessionid2AggrInfoRDD
因为 filteredSessionid2AggrInfoRDD 也被使用两次,所以也将其持久化。在
JavaPairRDD<String, String> filteredSessionid2AggrInfoRDD = filterSessionAndAggrStat(
sessionid2AggrInfoRDD, taskParam, sessionAggrStatAccumulator);后面添加
filteredSessionid2AggrInfoRDD = filteredSessionid2AggrInfoRDD.persist(StorageLevel.MEMORY_ONLY());持久化 sessionid2detailRDD
因为 sessionid2detailRDD 使用了三次,所以也需将其持久化,所以,在
JavaPairRDD<String, Row> sessionid2detailRDD = getSessionid2detailRDD(
filteredSessionid2AggrInfoRDD, sessionid2actionRDD);后添加持久化操作
sessionid2detailRDD = sessionid2detailRDD.persist(StorageLevel.MEMORY_ONLY());《Spark 大型电商项目实战》源码:https://github.com/Erik-ly/SprakProject
本文为《Spark大型电商项目实战》系列文章之一,
更多文章:Spark大型电商项目实战:http://blog.csdn.net/u012318074/article/category/6744423
以上是关于50.性能调优之重构RDD架构以及RDD持久化的主要内容,如果未能解决你的问题,请参考以下文章
Spark篇---Spark调优之代码调优,数据本地化调优,内存调优,SparkShuffle调优,Executor的堆外内存调优