Python基础之内置函数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础之内置函数相关的知识,希望对你有一定的参考价值。
一、内置函数表(Python 3.x)

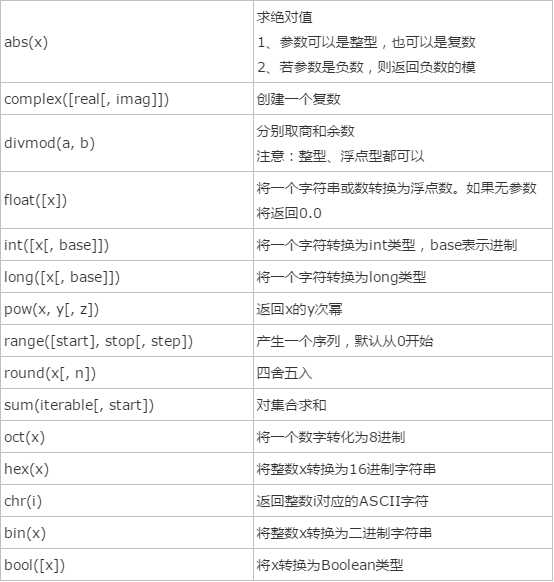
1、数学运算类:
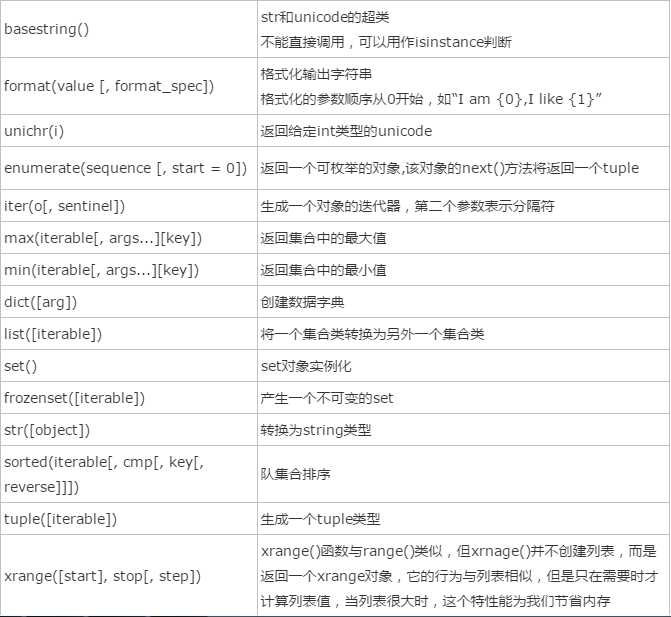
2、集合类操作:
3、逻辑判断:

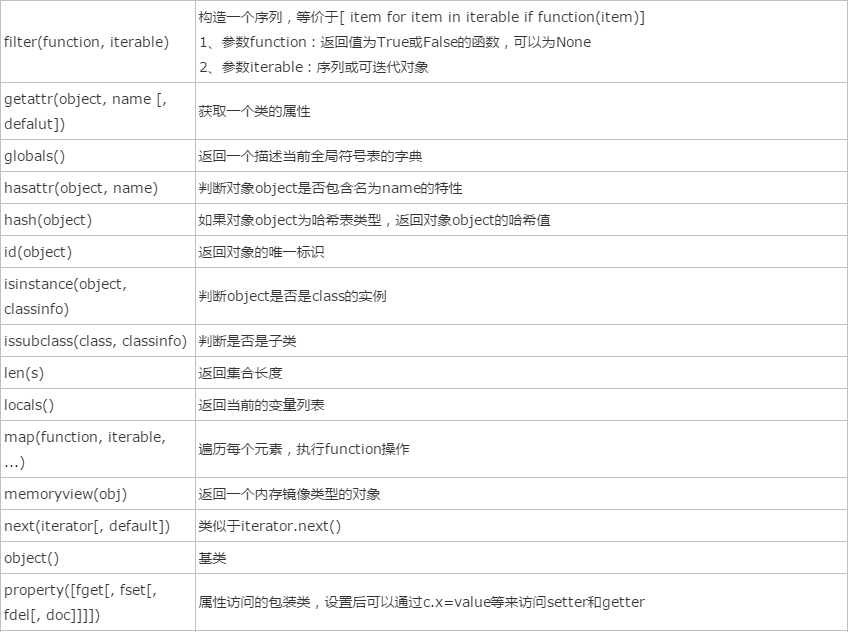
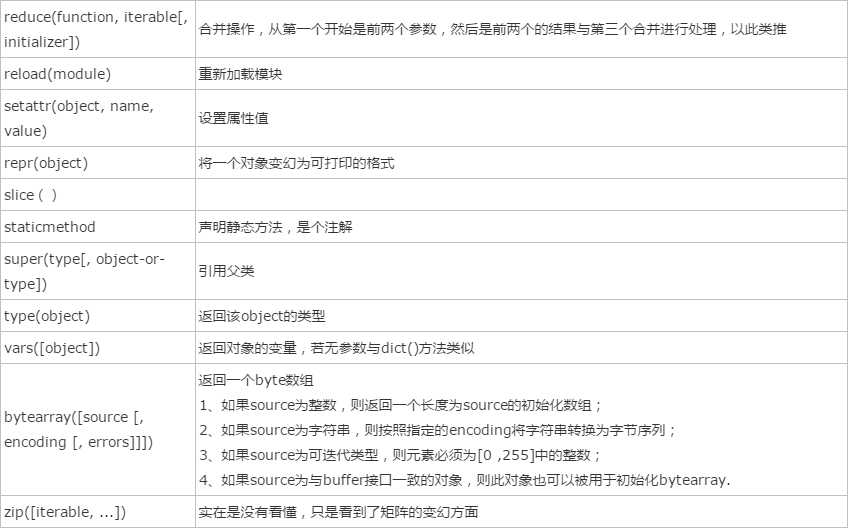
4、反射:

5、IO操作:

二、内置函数使用实例:
1、abs() 取绝对值
print(abs(3))
print(abs(-3)) #取-3的绝对值
--------输出结果--------
3
3
2、all() 括号里的内容都为True时,结果才为True,反之为False
print(all("")) #可迭代对象是空的,也返回True
print(all((1,2,"a","b")))
print(all((1,2,"a","b"," ")))
print(all((1,2,"a","b"," ",None))) #只要有一个为False,就为False
---------------------------输出结果--------------------------
True
True
True
False
3、any() 括号里的内容只要有一个为True时,结果才为True,反之为False
print(any(("",None)))
print(any((1,"",None))) #只要有一个为True时,结果为True
----------输出结果-----------
False
True
4、bin() 把十进制转为二进制
print(bin(5)) #将5转成二进制
-------输出结果-------
0b101 #二进制表达式
5、bool 布尔值 空,None,0的布尔值为False,其余都为True
print(bool("")) #空
print(bool(0)) #0
print(bool(None)) #None
print(bool("0")) #此时0位一个字符串
----------------输出结果------------------
False
False
False
True
6、bytes() 把字符串转成字节
content = "你好"
print(bytes(content,encoding="utf8")) #手动把字符串编码,转成二进制bytes类型
print(bytes(content,encoding="utf8").decode("utf8")) #需要把字符串进行编码,再解码(用什么编码,就用什么解码)
------------------------输出结果--------------------------
b‘\\xe4\\xbd\\xa0\\xe5\\xa5\\xbd‘
你好
7、chr() 数值对应的ASSCII字符
print(chr(65))
print(chr(66))
print(chr(67))
-----输出结果-----
A
B
C
8、dir 显示函数内置属性和方法
print(dir(dict)) ----------------输出结果-------------------- [‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__delitem__‘, ‘__dir__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__init_subclass__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__setattr__‘, ‘__setitem__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘clear‘, ‘copy‘, ‘fromkeys‘, ‘get‘, ‘items‘, ‘keys‘, ‘pop‘, ‘popitem‘, ‘setdefault‘, ‘update‘, ‘values‘]
9、divmod 取商得余数,用于做分页显示功能
print(divmod(10,3)) #得3,余1,就得要4页了
----------输出结果---------
(3, 1)
10、eval 把字符串中的数据结构给提取出来,解释字符串表达式
dic={‘name‘:‘michael‘} #定义一个字典
dic_str=str(dic) #字典类型转成字符串
print(dic_str) #打印内容
print(type(dic_str)) #打印数据类型
d1=eval(dic_str) #eval:把字符串中的数据结构给提取出来
print(d1) #打印内容
print(type(d1)) #打印数据类型
---------------输出结果------------------
{‘name‘: ‘michael‘}
<class ‘str‘>
{‘name‘: ‘michael‘}
<class ‘dict‘>
11、globals 全局变量
ps1:
name = "千江有水千江月,万里无云万里天。"
print(globals())
---------------------输出结果-------------------------
{‘__name__‘: ‘__main__‘, ‘__doc__‘: None, ‘__package__‘: None, ‘__loader__‘: <_frozen_importlib_external.SourceFileLoader object at 0x00000000021C9668>, ‘__spec__‘: None, ‘__annotations__‘: {}, ‘__builtins__‘: <module ‘builtins‘ (built-in)>, ‘__file__‘: ‘F:/Michael/day25/内置函数实例.py‘, ‘__cached__‘: None, ‘name‘: ‘千江有水千江月,万里无云万里天。‘}
ps2:
name = "千江有水千江月,万里无云万里天。" print(__file__) #打印文件路径和文件名 ------------输出结果--------------- F:/Michael/day25/内置函数实例.py
ps3:
globals 打印全局变量,locals 打印局部变量
name = "千江有水千江月,万里无云万里天。"
def test():
name1 = "千山同一月,万户尽皆春。"
print(globals())
print(locals())
test()
---------------------输出结果-------------------------
{‘__name__‘: ‘__main__‘, ‘__doc__‘: None, ‘__package__‘: None, ‘__loader__‘: <_frozen_importlib_external.SourceFileLoaderobject at 0x0000000002209668>, ‘__spec__‘: None, ‘__annotations__‘: {}, ‘__builtins__‘: <module ‘builtins‘ (built-in)>, ‘__file__‘: ‘F:/Michael/day25/内置函数实例.py‘, ‘__cached__‘: None, ‘name‘: ‘千江有水千江月,万里无云万里天。‘, ‘test‘: <function test at 0x00000000003F3E18>}
-----------------分隔线---------------------
{‘name1‘: ‘千山同一月,万户尽皆春。‘}
12、hash() 可hash的数据类型即不可变数据类型,不可hash的数据类型即可变数据类型
hash的作用:在网上下载软件,判断是否被人修改,通过比对hash值,就知道。还有在传输数据的时候,通过hash
值传输前后的对比,就能判断数据是否完整。
print(hash("dkdgdkhglkf"))
print(hash("dkdgdkhglkfjwiofwndnvjskdfjkljj"))
name = "egon"
print(hash(name))
print("----->before",hash(name))
name = "somebody"
print("=====>after",hash(name))
-----------------输出结果-------------------
-8352099065023340321
7790489956030600654
-1821075661332880192
----->before -1821075661332880192
=====>after -3592763496452633376
13、help() 查看函数用法的祥细信息
print(help(all))
------------输出结果--------------
Help on built-in function all in module builtins:
all(iterable, /)
Return True if bool(x) is True for all values x in the iterable.
If the iterable is empty, return True.
None
14、bin、hex、oct 进制转换
print(bin(12)) #binary 十进制----> 二进制
print(oct(12)) #octonary 十进制----> 八进制
print(hex(12)) #hexadecimal 十进制----> 十六进制
------------------------输出结果----------------------------
0b1100
0o14
0xc
15、isinstance判断类型
print(isinstance(1,int)) #判断是不是int类型
print(isinstance(‘abc‘,str)) #判断字符串
print(isinstance([],list)) #判断列表
print(isinstance({},dict)) #判断字典
print(isinstance({1,2},set)) #判断集合
--------------------输出结果-----------------------
True
True
True
True
True
16、max() 最大值 和 min() 最小值
简单用法:
l = [2,4,0,-2,23]
print(max(l))
print(min(l))
-----输出结果-----
23
-2
高级用法:
说明:
1、max函数处理的是可迭代对象,相当于一个for循环取出每个元素进行比较;
注意:不同类型之间不能进行比较。
2、每个元素间进行比较,是从每个元素的第一位置依次比较,如果这一个位置分出大小,后面的都不需要比较
了,直接得出这俩元素的大小。
从字典salary_dic取出工资最高的人和最低的人:
salary_dic = {‘egon‘:290,‘alex‘:100000000,‘wupeiqi‘:10000,‘yuanhao‘:2000}
print(max(salary_dic,key=lambda k:salary_dic[k])) #使用匿名函数
print(min(salary_dic,key=lambda k :salary_dic[k])) #使用匿名函数
-------------输出结果-----------------
alex #最高的人
egon #最低的人
17、zip() 将对象逐一配对,相当于拉链的功能
salary_dic = {‘egon‘:290,‘alex‘:100000000,‘wupeiqi‘:10000,‘yuanhao‘:2000}
print(list(zip(salary_dic.keys(),salary_dic.values()))) print(list(zip(["a","b","c"],[1,2,3,4,5]))) ----------------输出结果------------------- [(‘egon‘, 290), (‘alex‘, 100000000), (‘wupeiqi‘, 10000), (‘yuanhao‘, 2000)] [(‘a‘, 1), (‘b‘, 2), (‘c‘, 3)]
18、reversed() 反转
l = [1,2,4,3]
print(list(reversed(l)))
print(l)
-------输出结果--------
[3, 4, 2, 1] #注意:它是按原列表的顺序反转,并非按元素大小排序
[1, 2, 4, 3]
19、round() 四舍五入
print(round(3.4))
print(round(3.5))
-------输出结果--------
3
4
20、slice() 切片
a = "hello world"
a1 = slice(1,9) #切片
a2 = slice(1,9,2) #加上步长切片
print(a[a1]) #1
print(a[1:9]) #2 1和2效果是一样的
print(a[a2]) #3
print(a[1:9:2]) #4 3和4效果是一样的
print(a2.start) #开始的索引值
print(a2.stop) #结束的索引值
print(a2.step) #步长
----------输出结果-------------
ello wor
ello wor
el o
el o
1
9
2
21、sorted() 排序
还是同16比较工资排序吧!
salary_dic = {‘egon‘:290,‘alex‘:100000000,‘wupeiqi‘:10000,‘yuanhao‘:2000}
print(sorted(salary_dic,key=lambda k:salary_dic[k])) #工资从低到高
print(sorted(salary_dic,key= lambda x:salary_dic[x],reverse=True)) #把反转的巩固一下,是工资从高到低排序
-----------------输出结果------------------
[‘egon‘, ‘yuanhao‘, ‘wupeiqi‘, ‘alex‘]
[‘alex‘, ‘wupeiqi‘, ‘yuanhao‘, ‘egon‘]
22、import 模块
import time time.sleep(3) print(time) ---------输出结果-------- <module ‘time‘ (built-in)> #会睡眠3s输出结果
23、__import__() 导入一个字符串类型模块
s = "time" m = __import__(s) m.sleep(2) print(m) -----输出结果------ <module ‘time‘ (built-in)> #会睡眠2s输出结果
以上是关于Python基础之内置函数的主要内容,如果未能解决你的问题,请参考以下文章