python之爬虫学习记录与心得
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之爬虫学习记录与心得相关的知识,希望对你有一定的参考价值。
之前在寒假的时候,学习了python基础。在慕课网上看的python入门:http://www.imooc.com/learn/177
python进阶:http://www.imooc.com/learn/317
其实好多知识都是学了忘,忘了学的。
最近因为要使用爬虫爬去数据和照片,所以现在开始学习网络爬虫。
爬虫架构:URL管理器,网页下载器,网页解析器
URL管理器:管理待抓取URL集合和已抓取URL集合 防止重复抓取。
URL管理器实现方法: 缓存数据库:大公司,性能高 内存:个人,小公司 关系数据库:永久保存URL数据或节约内存
网页下载器:将URL对应的网页以HTML下载到本地,用于后续分析 常见网页下载器:Python官方基础模块:urllib2 第三方功能包:requests
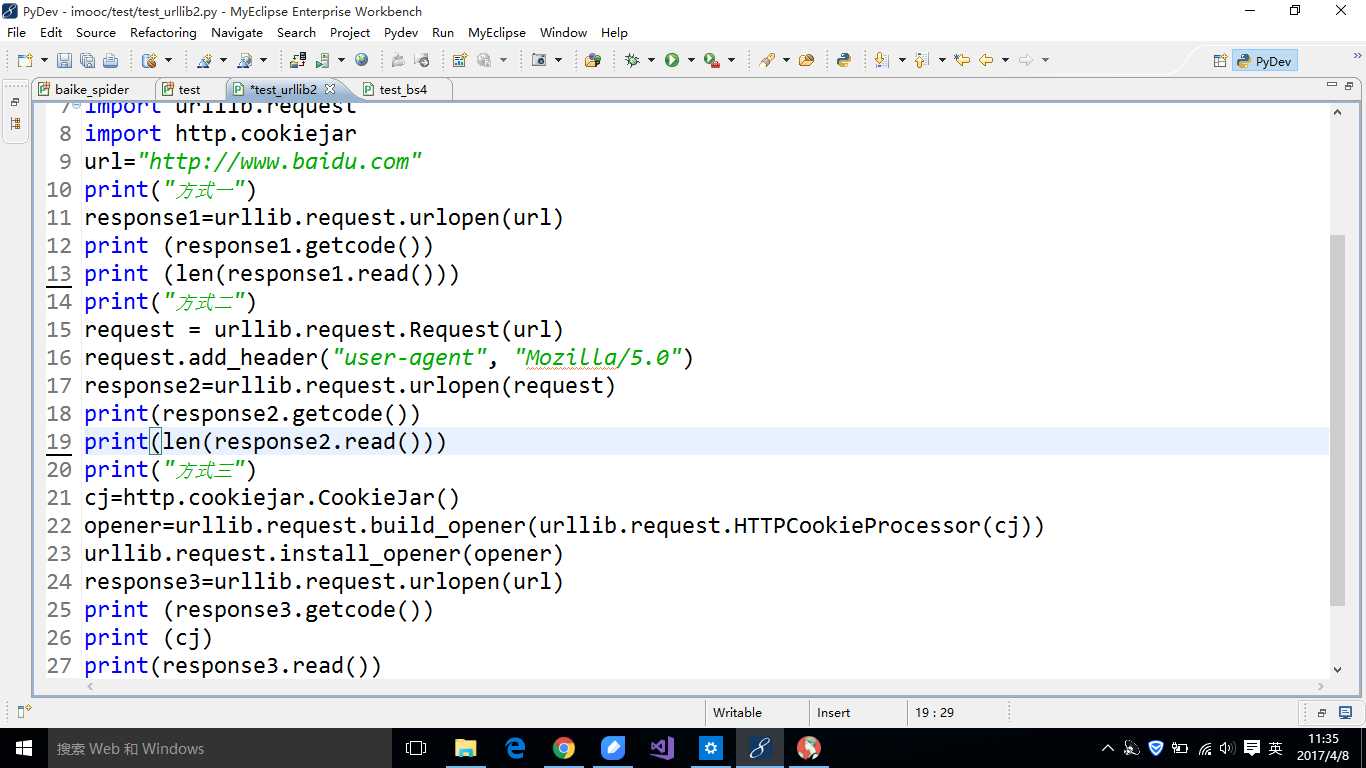
python 3.x中urllib库和urilib2库合并成了urllib库。 其中urllib2.urlopen()变成了urllib.request.urlopen() urllib2.Request()变成了urllib.request.Request()
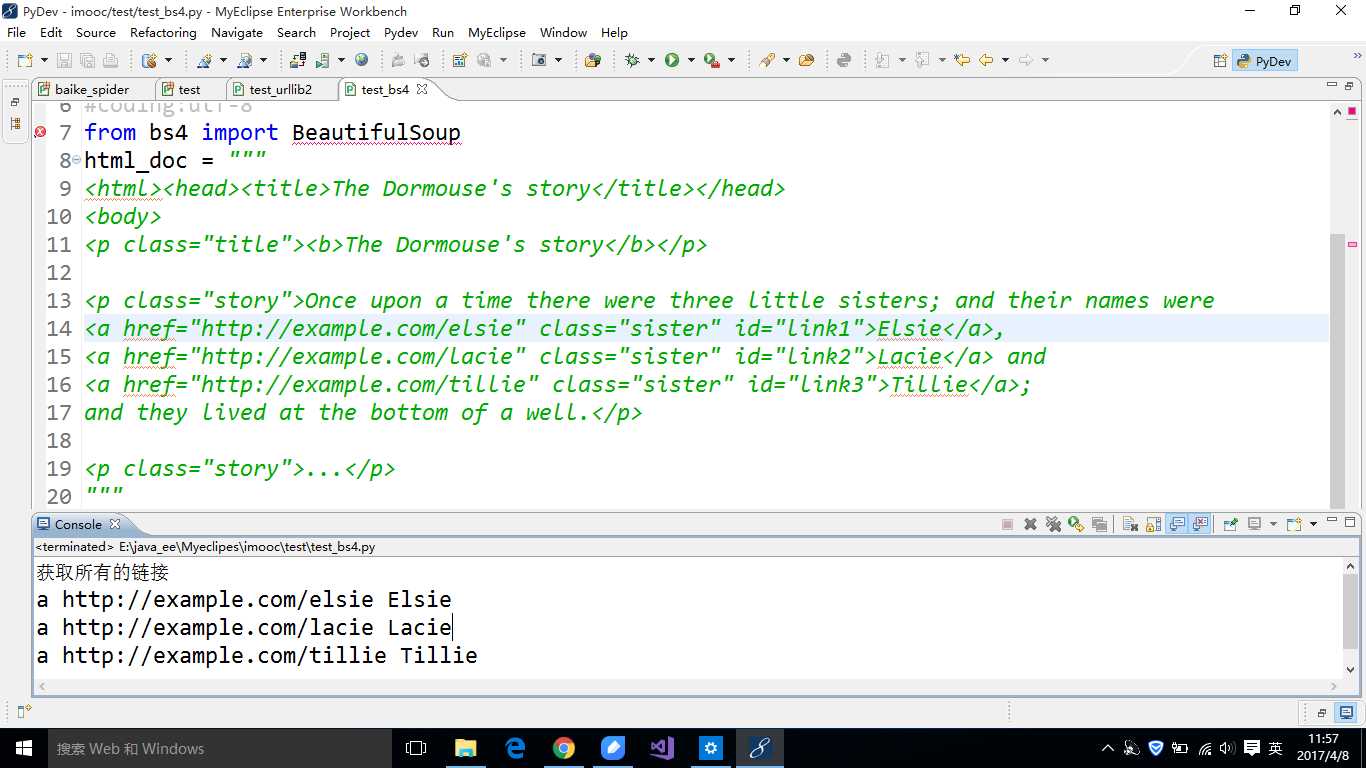
Python的网页解析器分为两类: 1.模糊匹配—>正则表达式 2.结构化解析-> Beautiful Soup、html.parser、lxml 把整个网页作为一个DOM树来进行解析。(Document Objective Model)
新建一个pydev module。在里面输入:

import bs4
print(bs4)
右键文档 run as -> python as
运行出错。打开win+R,cmd
进入命令提示符。进入python的安装目录,cd script
pip install beautifulsoup4
进行安装。
安装成功后重新运行。
报错:
UserWarning: You provided Unicode markup but also provided a value for from_encoding. Your from_encoding will be ignored.
解决方法:
soup = BeautifulSoup(html_doc,"html.parser")
这一句中删除【from_encoding="utf-8"】
原因:
python3 缺省的编码是unicode, 再在from_encoding设置为utf8, 会被忽视掉,去掉【from_encoding="utf-8"】这一个好了

以上是关于python之爬虫学习记录与心得的主要内容,如果未能解决你的问题,请参考以下文章