Python爬虫学习记录内附代码详细步骤
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫学习记录内附代码详细步骤相关的知识,希望对你有一定的参考价值。
引言:
昨天在网易云课堂自学了《Python网络爬虫实战》,视频链接 老师讲的很清晰,跟着实践一遍就能掌握爬虫基础了,强烈推荐!
另外,在网上看到一位学友整理的课程记录,非常详细,可以优先参考学习。传送门:请点击
本篇文章是自己同步跟着视频学习的记录,欢迎阅读~~~
实验:新浪新闻首页爬虫实践
http://news.sina.com.cn/china/
一、准备
-
浏览器内建的开发人员工具(以Chrome为例)
-
Python3 requests 库
-
Python3 BeautifulSoup4 库(注意,BeautifulSoup4和BeautifulSoup是不一样的)
-
jupyter notebook
二、抓取前的分析
以Chrome为例,抓取前的分析步骤如图:
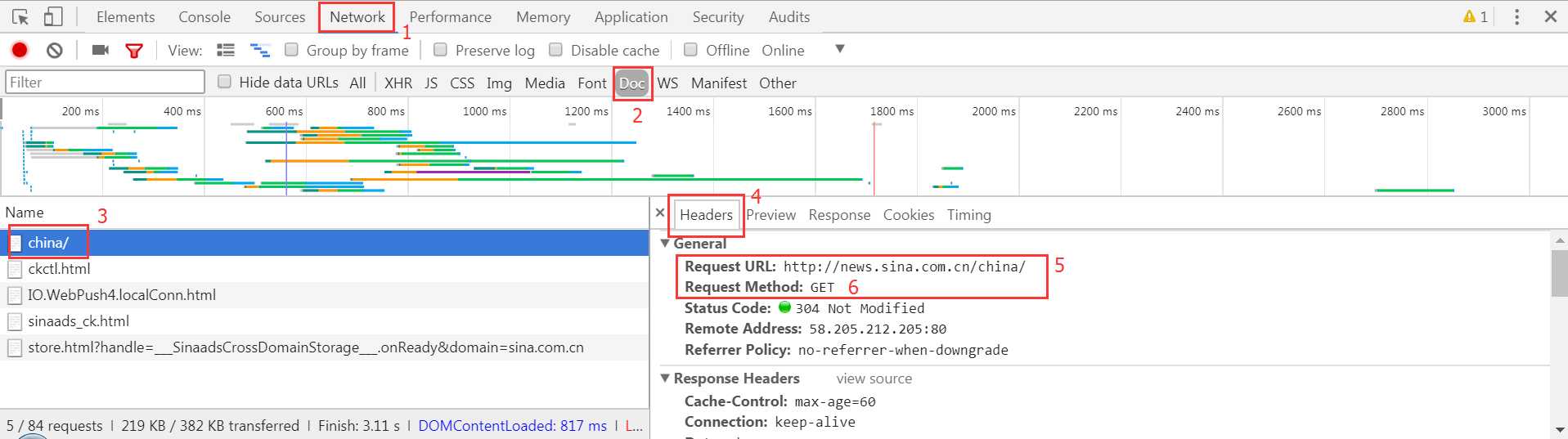
- 按
F12进入到开发者工具; - 点击
Network; 刷新页面;(按F5)- 找到
Doc; - 找到左边
Name这一栏的第一个(需要爬去的链接90%的情况都是第一个); - 点击右边的
Headers; - 找到请求的URL和请求方式。
三、开始撰写第一只网络爬虫
Requests库
- 网络资源撷取套件
- 改善Urllib2的缺点,让使用者以最简单的方式获取网络资源
- 可以使用REST操作存取网络资源
jupyter
使用jupyter来抓取网页并打印在浏览器中,再按Ctrl-F查找对应的内容,以确定我们要爬去的内容在该网页中。
测试示例:
1 import requests 2 res = requests.get(‘http://www.sina.com.cn/‘) 3 res.encoding = ‘utf-8‘ 4 print(res.text)
四、用BeautifulSoup4剖析网页元素
测试示例:
1 from bs4 import BeautifulSoup 2 html_sample = ‘ 3 <html> 4 <body> 5 <h1 id="title">Hello World</h1> 6 <a href="#" class="link">This is link1</a> 7 <a href="# link2" class="link">This is link2</a> 8 </body> 9 </html>‘ 10 11 soup = BeautifulSoup(html_sample, ‘lxml‘) 12 print(soup.text)
五、BeautifulSoup基础操作
使用select找出含有h1标签的元素
soup = BeautifulSoup(html_sample) header = soup.select(‘h1‘) print(header) print(header[0]) print(header[0].text)
使用select找出含有a的标签
soup = BeautifulSoup(html_sample, ‘lxml‘) alink = soup.select(‘a‘) print(alink) for link in alink: print(link) print(link.txt)
使用select找出所有id为title的元素(id前面需要加#)
alink = soup.select(‘#title‘) print(alink)
使用select找出所有class为link的元素(class前面需要加.)
soup = BeautifulSoup(html_sample) for link in soup.select(‘.link‘): print(link)
使用select找出所有a tag的href链接
alinks = soup.select(‘a‘) for link in alinks: print(link[‘href‘]) # 原理:会把标签的属性包装成字典
六、观察如何抓取新浪新闻信息
关键在于寻找CSS定位
- Chrome开发人员工具(进入开发人员工具后,左上角点选元素观测,就可以看到了)
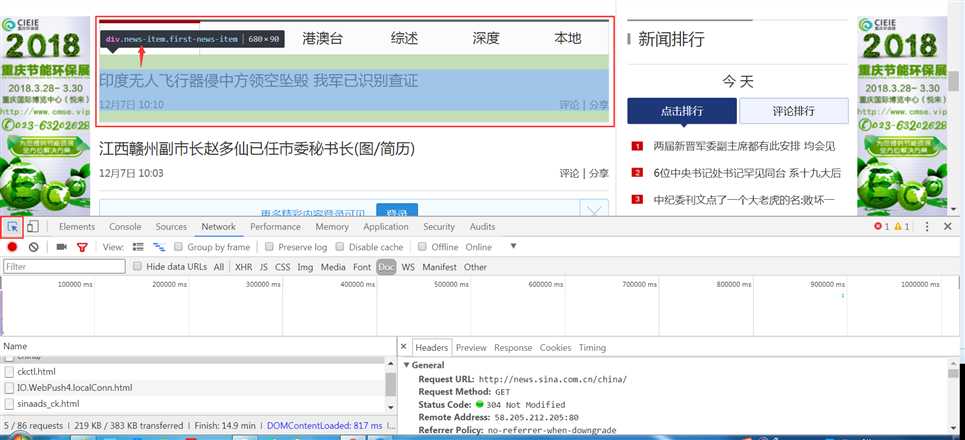
Chrome寻找元素定位.png
- Firefox开发人员工具
- InfoLite(需FQ)
七、制作新浪新闻网络爬虫
抓取时间、标题、内容
import requests from bs4 import BeautifulSoup res = requests.get(‘http://news.sina.com.cn/china‘) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text, ‘lxml‘) for news in soup.select(‘.news-item‘): if (len(news.select(‘h2‘)) > 0): h2 = news.select(‘h2‘)[0].text time = news.select(‘.time‘)[0].text a = news.select(‘a‘)[0][‘href‘] print(time, h2, a)
抓取新闻内文页面
新闻网址为:http://news.sina.com.cn/o/2017-12-06/doc-ifypnyqi1126795.shtml
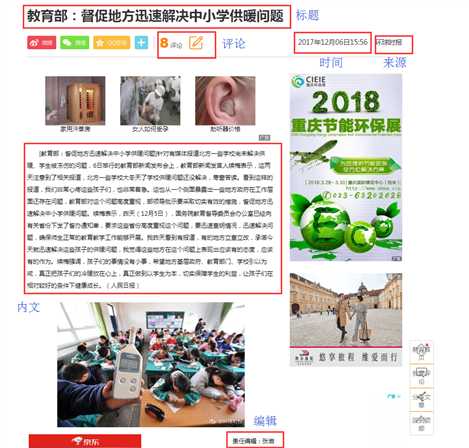
内文资料信息说明图.png
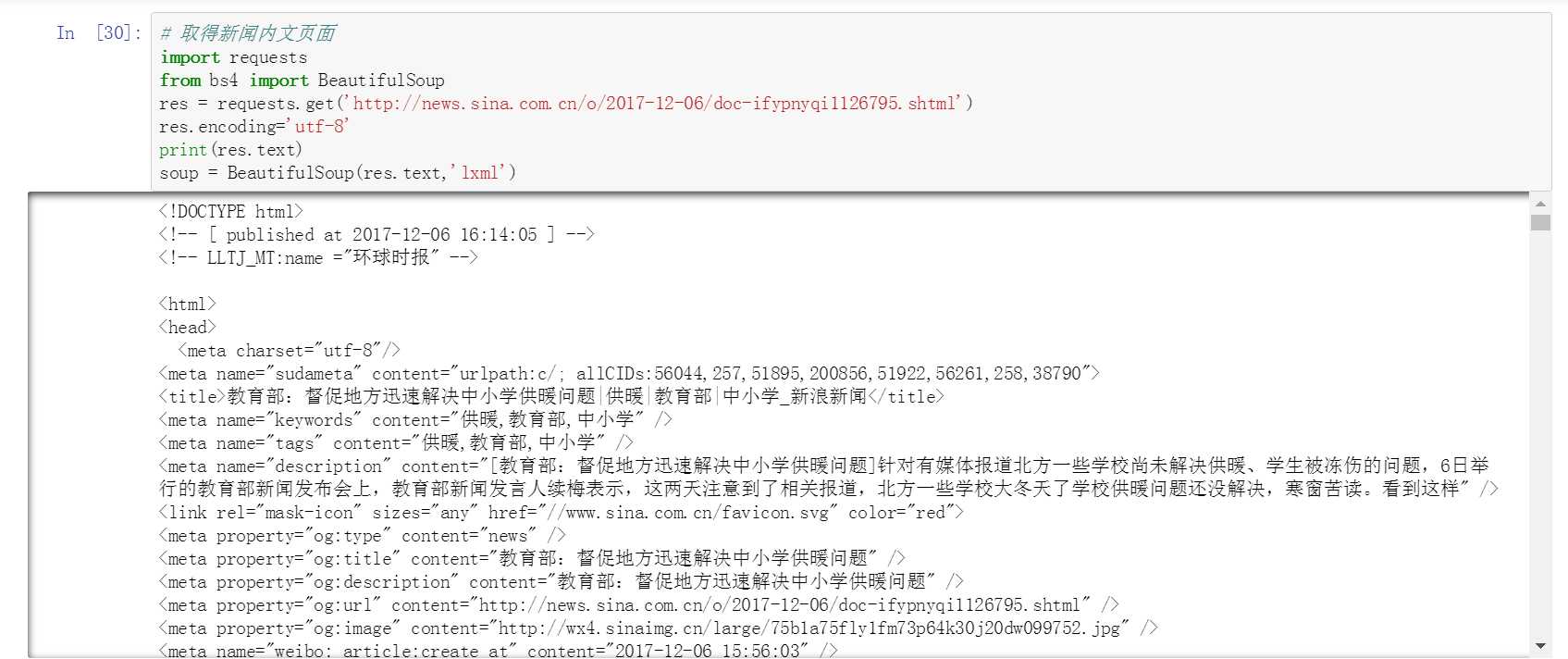
获取新闻内文标题、时间、来源
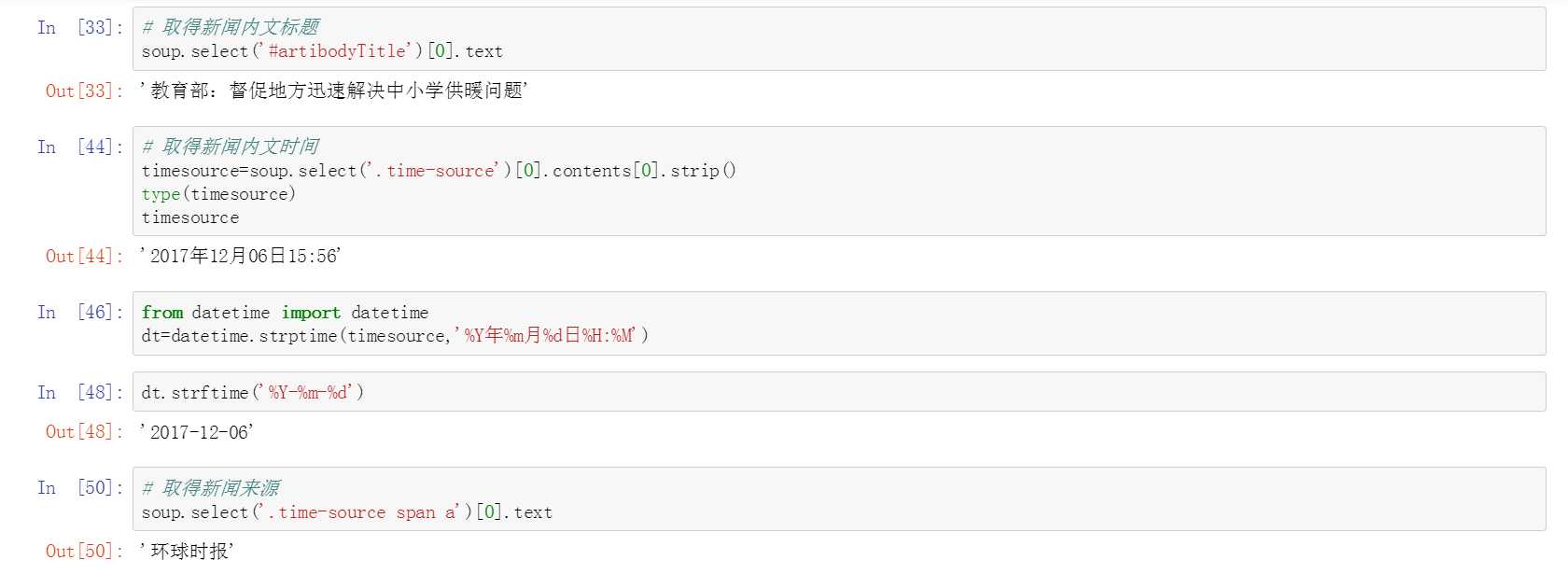
其中涉及时间和字符串转换
from datetime import datetime // 字符串转时间 --- strptime dt = datetime.strptime(timesource, ‘%Y年%m月%d日%H:%M‘) // 时间转字符串 --- strftime dt.strftime(%Y-%m-%d)
整理新闻内文、获取编辑名称
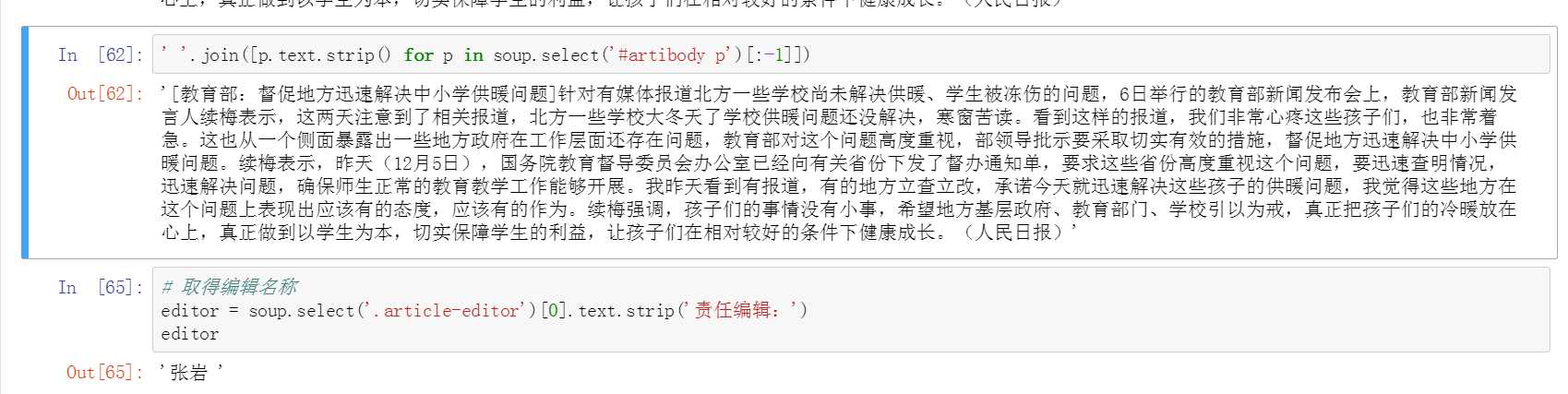
整理新闻内文步骤:
1、抓取;
2、获取段落;
3、去掉最后一行的编辑者信息;
4、去掉空格;
5、将空格替换成\\n,这里可以自行替换成各种其他形式;
最终简写为一句话。
抓取新闻评论数
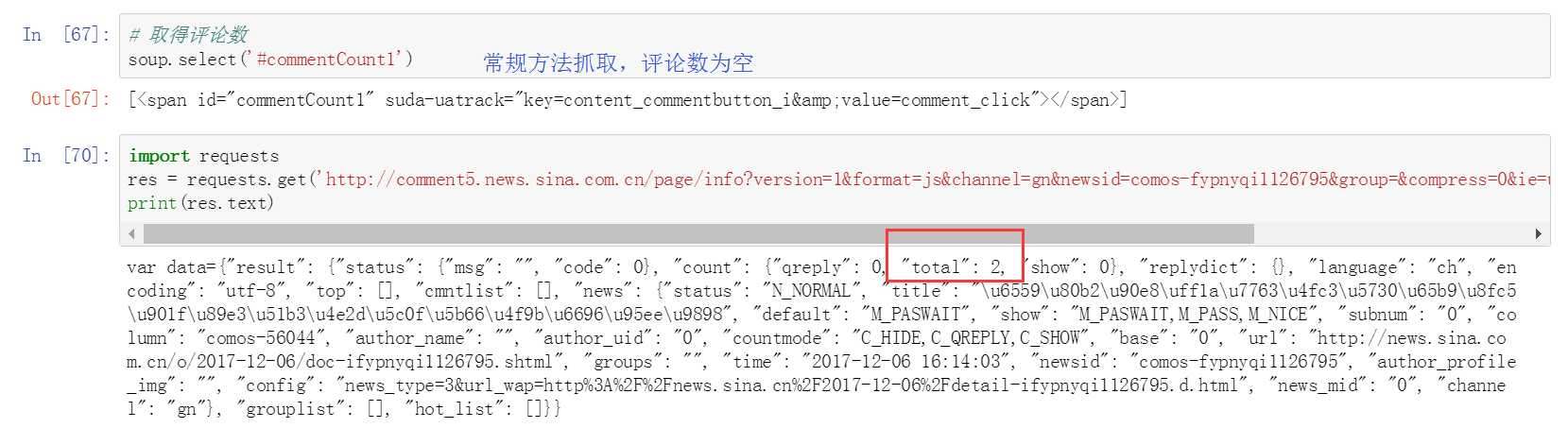
解释:
评论是是通过JS代码传过来的;既然是JS,那么通过AJAX传过来的概率很高,于是点到XHR中看,但是发现Response中没有出现总评论数2;然后就只能去JS里面了,地毯式搜索,找哪个Response里出现了总评论数2,终于找到了。
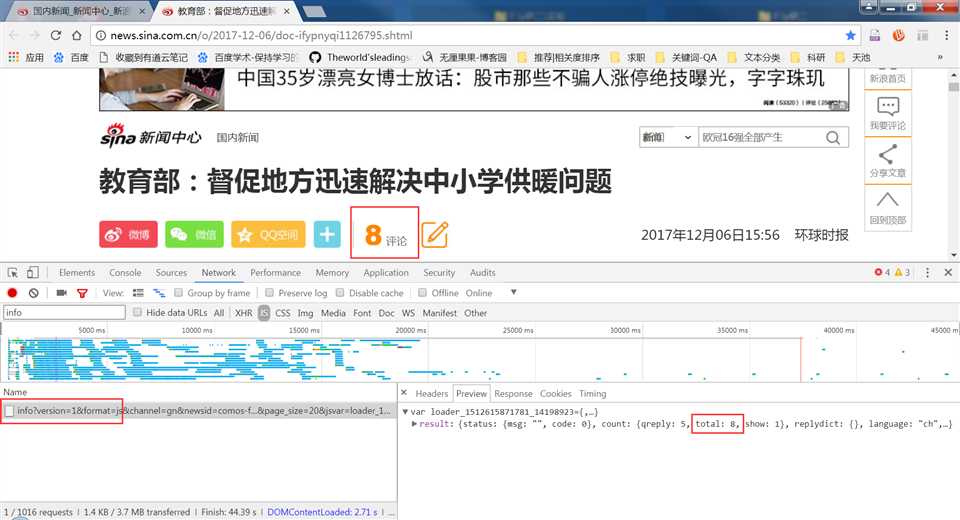
找到链接和请求方式
今天补的截图,评论数实时增加,请不要觉得奇怪 ^_^
然后就可以撸码了。
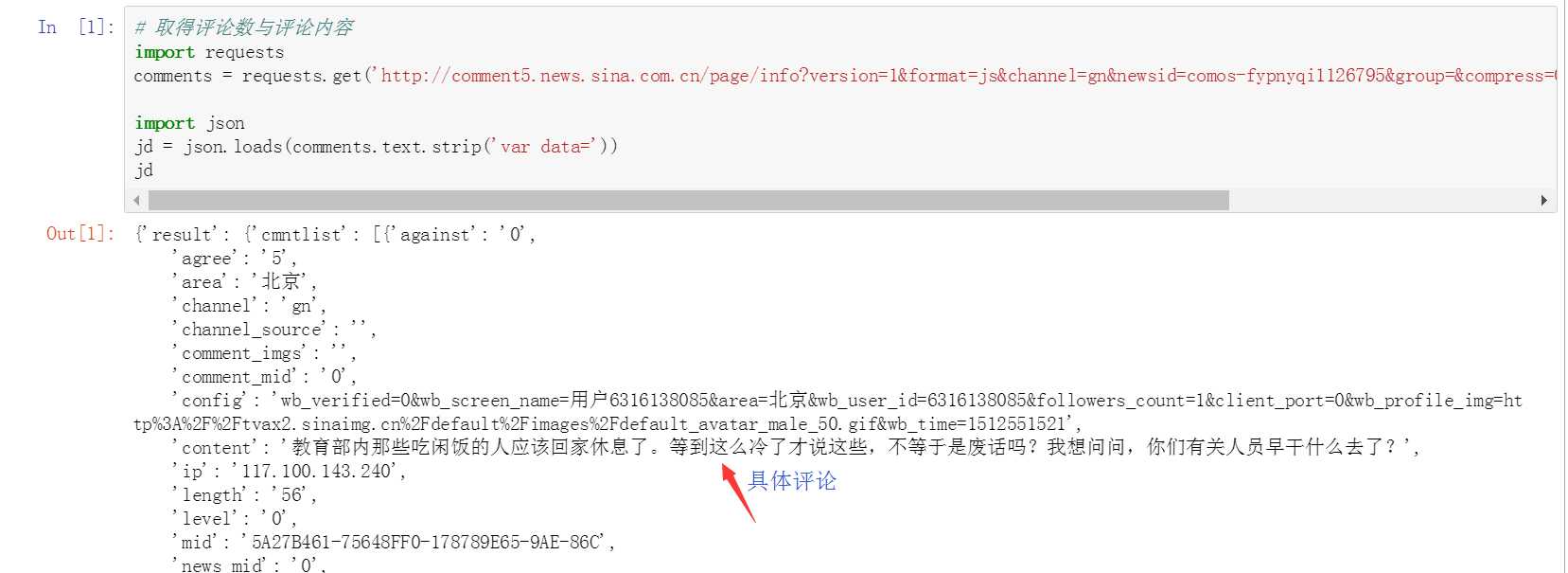
解释:
var data={......}看着很像是个json串,去掉var data=,使其变为json串。
可以看到,jd串中就是评论的信息了。
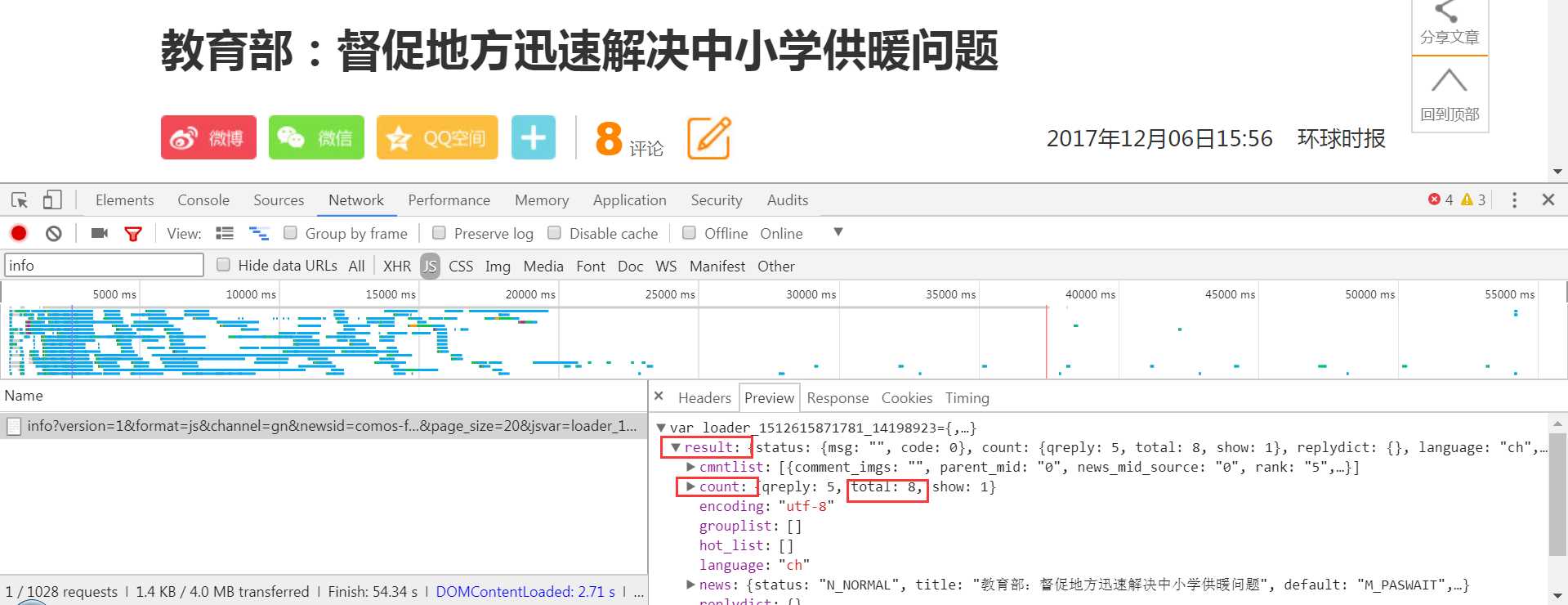
回到Chrome开发工具中,浏览评论数量。

获取新闻标识符(新闻ID)
方式1:切割法
# 取得新闻编号 newsurl = ‘http://news.sina.com.cn/o/2017-12-06/doc-ifypnyqi1126795.shtml‘ newsid = newsurl.split(‘/‘)[-1].rstrip(‘.shtml‘).lstrip(‘doc-i‘) newsid
方式2:正则表达式
import re m = re.search(‘doc-i(.*).shtml‘, newsurl) newsid = m.group(1) newsid
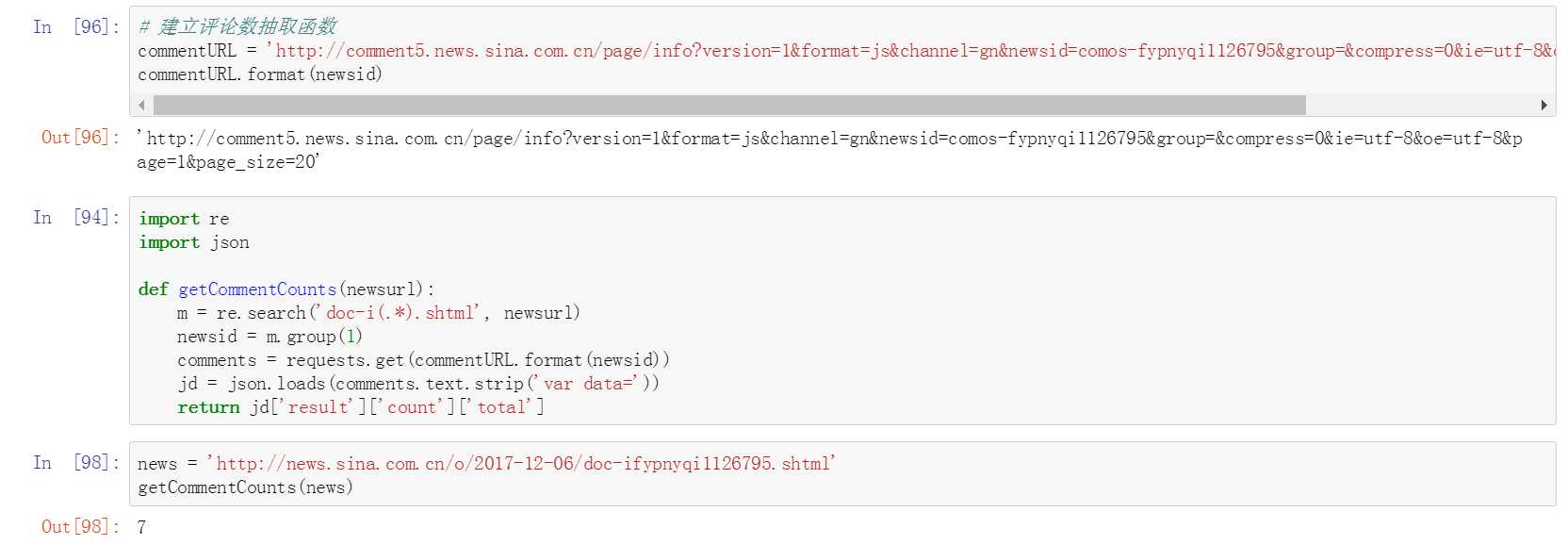
八、建立获取评论数函数
做一个总整理,把刚刚取得评论数的方法整理成一个函数。之后有新闻网页的链接丢进来,可以通过这个函式去取得它的总评论数。
九、建立新闻内文信息抽取函数

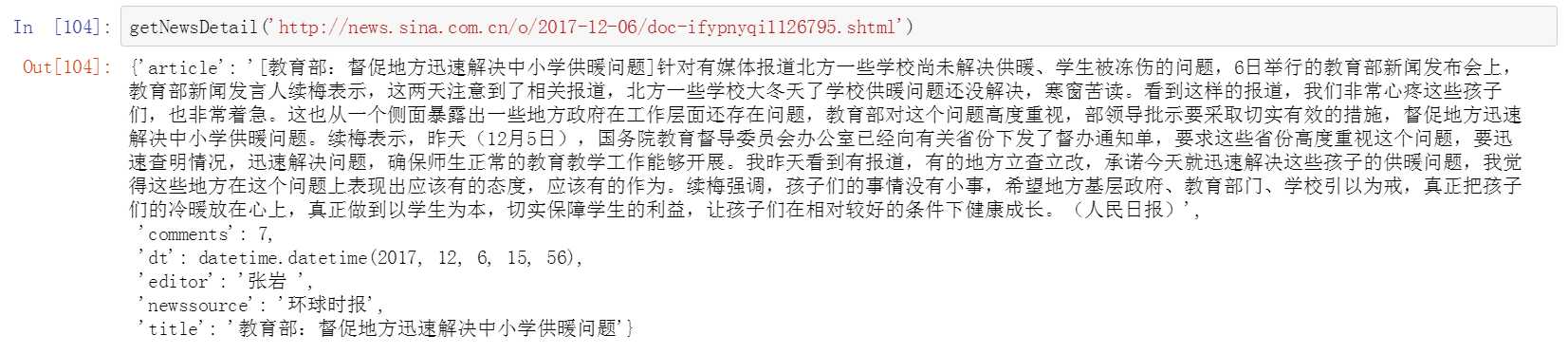
十、从列表链接中取出每篇新闻内容
如果Doc下面没有我们想要找的东西,那么就有理由怀疑,这个网页产生资料的方式,是通过非同步的方式产生的。因此需要去XHR和JS下面去找。
有时候会发现非同步方式的资料XHR下没有,而是在JS下面。这是因为这些资料会被JS的函式包装,Chrome的开发者工具认为这是JS文件,因此就放到了JS下面。
在JS中找到我们感兴趣的资料,然后点击Preview预览,如果确定是我们要找的,就可以去Headers中查看Request URL和Request Method了。
一般JS中的第一个可能就是我们要找的,要特别留意第一个。
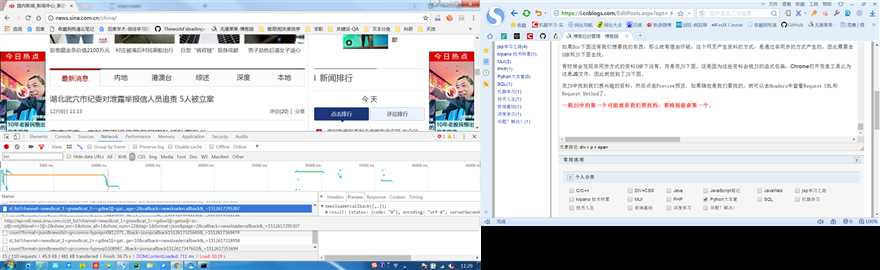
1、选择Network标签
2、点选JS
3、找到页面链接page=2
处理分页链接
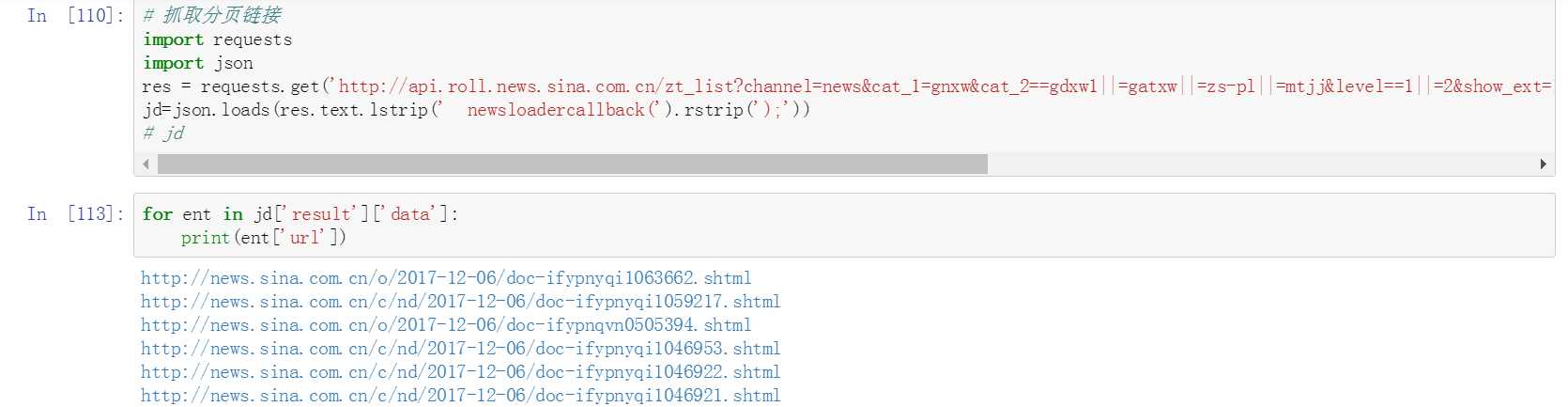
注意头尾,需要去掉头和尾,将其变成标准的json格式。
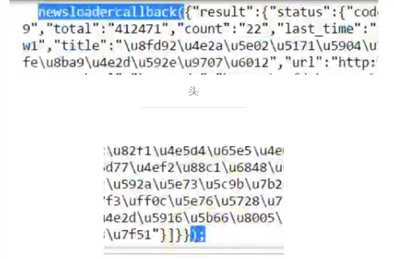
十一、建立剖析清单链接函数
将前面的步骤整理一下,封装到一个函式中。
def parseListLinks(url): newsdetails = [] res = requests.get(url) jd = json.loads(res.text.lstrip(‘newsloadercallback()‘).rstrip(‘);‘)) for ent in jd[‘result‘][‘data‘]: newsdetails.append(getNewsDetail(ent[‘url‘])) return newsdetails
十二、使用for循环产生多页链接

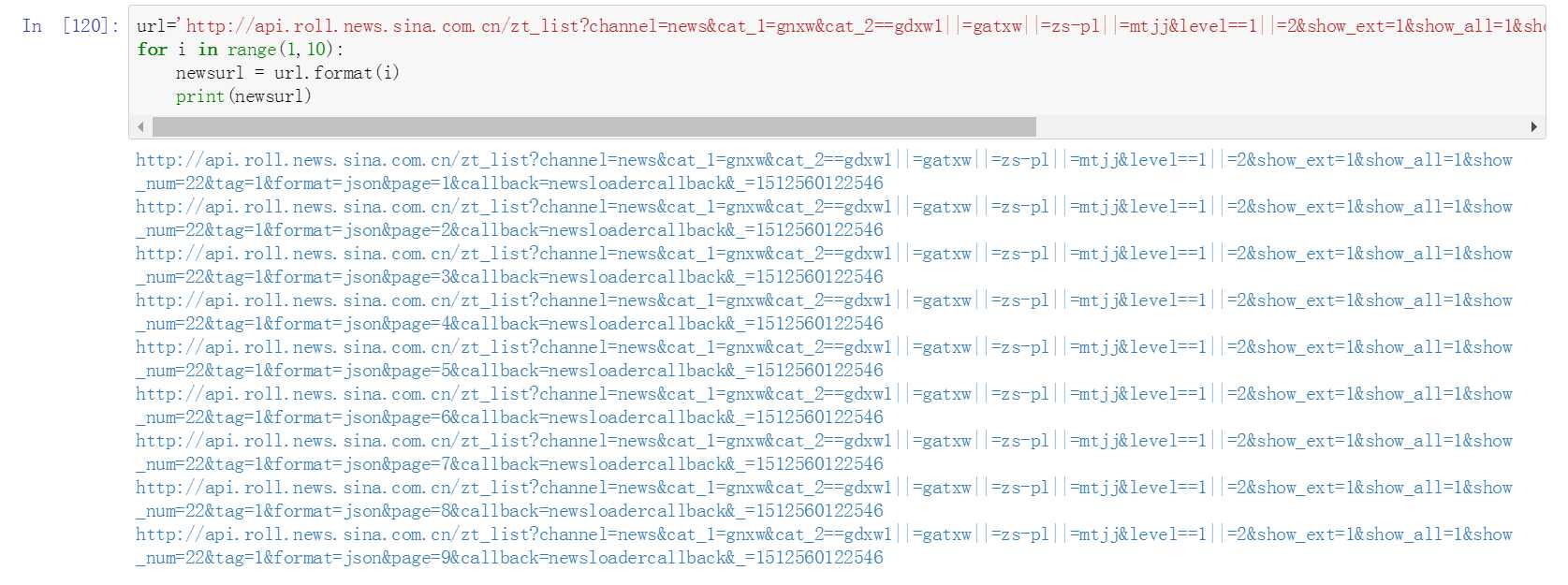
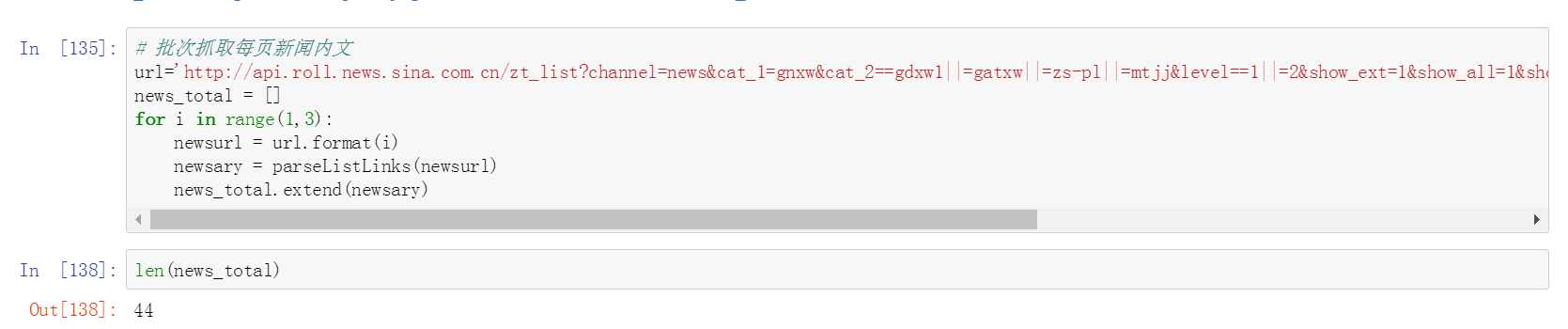
十三、批次抓取每页新闻内文

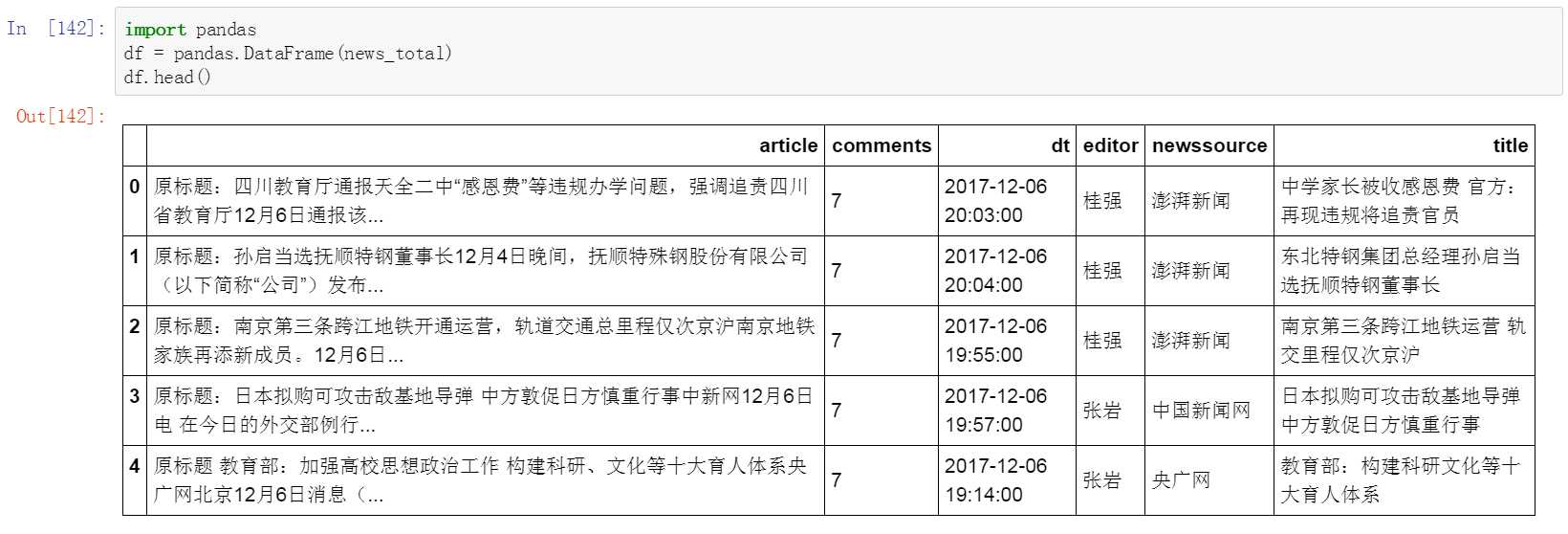
十四、 使用pandas整理数据
Python for Data Analysis
- 源于R
- Table-Like格式
- 提供高效能、简易使用的资料格式(Data Frame)让使用者可以快速操作及分析资料
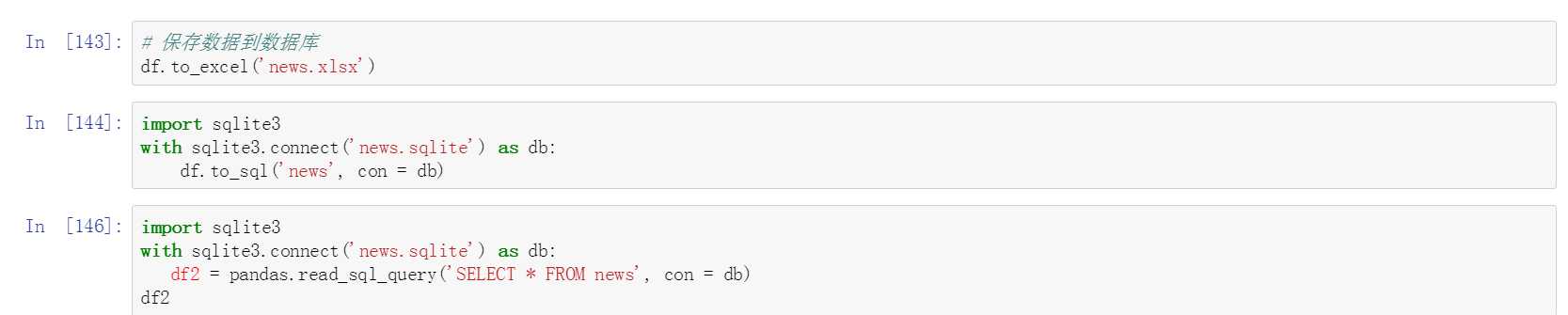
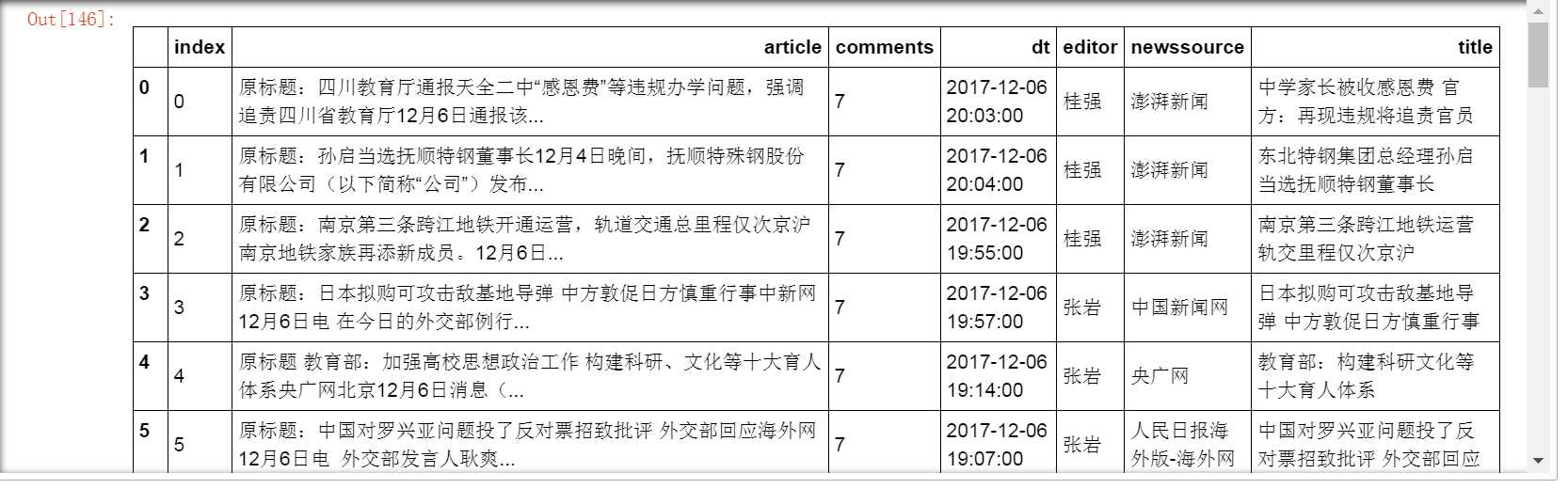
十五、保存数据到数据库
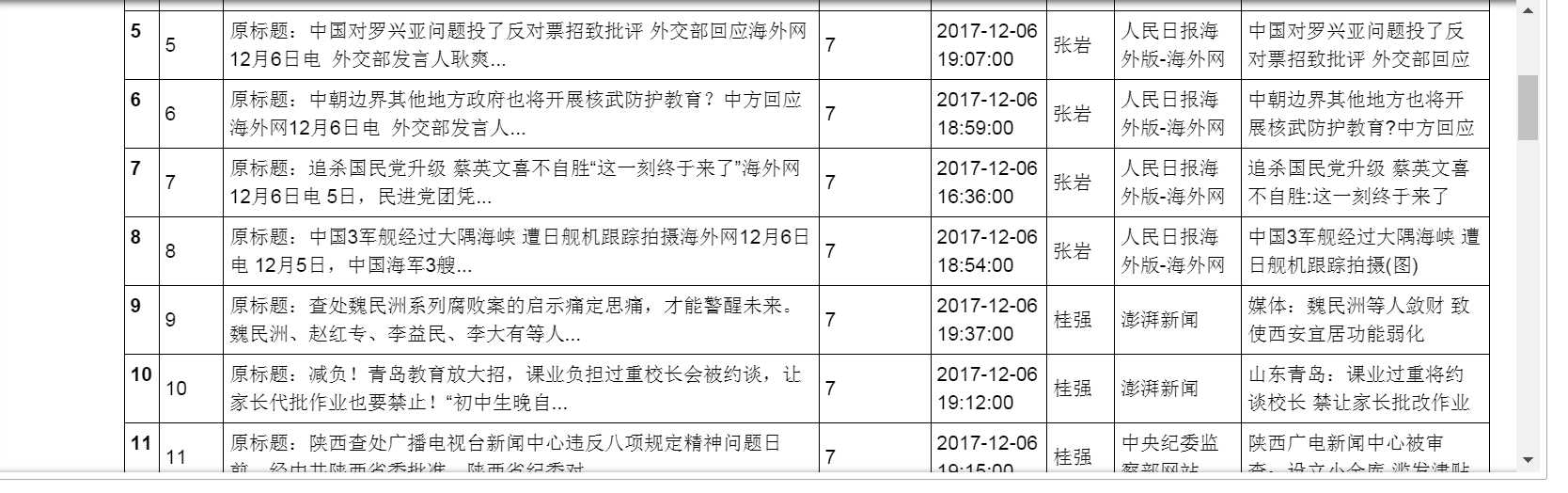
持续战斗到这里,第一只网络爬虫终于完成。看着最终的结果,很有成就感啊!^_^
大家感兴趣的可以试一试,欢迎讨论交流~~~
如果觉得文章有用,请随手点赞,感谢大家的支持!
特别赠送:GitHub代码传送门
感谢大家耐心地阅读,如果能对大家有一点点帮助,欢迎点亮我的GitHub星标,谢谢~~~
以上是关于Python爬虫学习记录内附代码详细步骤的主要内容,如果未能解决你的问题,请参考以下文章