python 爬取 豆瓣电影top250 存储到mysql
Posted qewwc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 爬取 豆瓣电影top250 存储到mysql相关的知识,希望对你有一定的参考价值。
数据分析师
想在本地找一些开源bi做一些数据可视化的呈现
先在网上扒拉点数据,存储到了本地
主要是学习学习python的爬虫
先在本地建了mysql的表 (比较粗暴)
CREATE TABLE `doubanmovie` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` text COMMENT ‘电影名称‘, `director` text COMMENT ‘导演‘, `actor` text COMMENT ‘演员‘, `style` text COMMENT ‘风格‘, `country` text COMMENT ‘国家‘, `release_time` text COMMENT ‘上映日期‘, `time` text COMMENT ‘时长‘, `score` text COMMENT ‘评分‘, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
然后根据学习的整了点数据存入
import requests from lxml import etree import re import pymysql import time author = ‘qewwc‘ conn = pymysql.connect(host=‘localhost‘, user=‘root‘, passwd=‘root‘, db=‘test‘, charset="utf8", use_unicode="True",port=3306) cursor = conn.cursor() headers = { ‘User-Agent‘ :‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36‘ } sql_in = ‘‘‘insert into doubanmovie (name,director,actor,style,country,release_time,time,score) value (%s,%s,%s,%s,%s,%s,%s,%s)‘‘‘ def get_movie_url(url): # 获取每个电影的链接 html = requests.get(url=url,headers=headers) selector = etree.HTML(html.text) movie_hrefs = selector.xpath(‘//div[@class="hd"]/a/@href‘) for movie_href in movie_hrefs: get_movie_info(movie_href) def get_movie_info(url): html = requests.get(url= url,headers = headers) # <Response [200]> selector = etree.HTML(html.text) # <Element html at 0x20892e10108> try: name = selector.xpath(‘//*[@id="content"]/h1/span[1]/text()‘)[0] except IndexError: name = ‘‘ try: director = selector.xpath(‘//*[@id="info"]/span[1]/span[2]/a/text()‘)[0] except IndexError: director = ‘‘ try: actors = selector.xpath(‘//*[@class="actor"]/span[2]‘)[0] actor = actors.xpath(‘string(.)‘) # actors = re.findall(‘<a href="/.*?/" rel="v:starring">(.*?)</a>‘,html.text,re.S) except IndexError: actor = ‘‘ try: style = re.findall(‘<span property="v:genre">(.*?)</span>‘, html.text, re.S)[0] except IndexError: style = ‘‘ try: country = re.findall(‘<span class="pl">制片国家/地区:</span> (.*?)<br/>‘, html.text, re.S)[0] except IndexError: country = ‘‘ try: release_time = re.findall(‘<span property="v:initialReleaseDate" content=.*?>(.*?)</span>‘, html.text, re.S)[0] except IndexError: release_time = ‘‘ try: time = re.findall(‘<span property="v:runtime" content=.*?>(.*?)</span>‘, html.text, re.S)[0] except IndexError: time = ‘‘ try: score = selector.xpath(‘//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()‘)[0] except IndexError: score = ‘‘ cursor.execute( sql_in,[str(name),str(director),str(actor),str(style),str(country),str(release_time),str(time),str(score)] ) # url = ‘https://movie.douban.com/subject/33967902/‘ # <span property="v:initialReleaseDate" content="2019-06-03(英国)">2019-06-03(英国)</span> urls = [‘https://movie.douban.com/top250?start={}&filter=‘.format(i) for i in range(0,250,25)] for url in urls: get_movie_url(url) time.sleep(5) print(‘我好了!‘) conn.commit()
最终数据如下
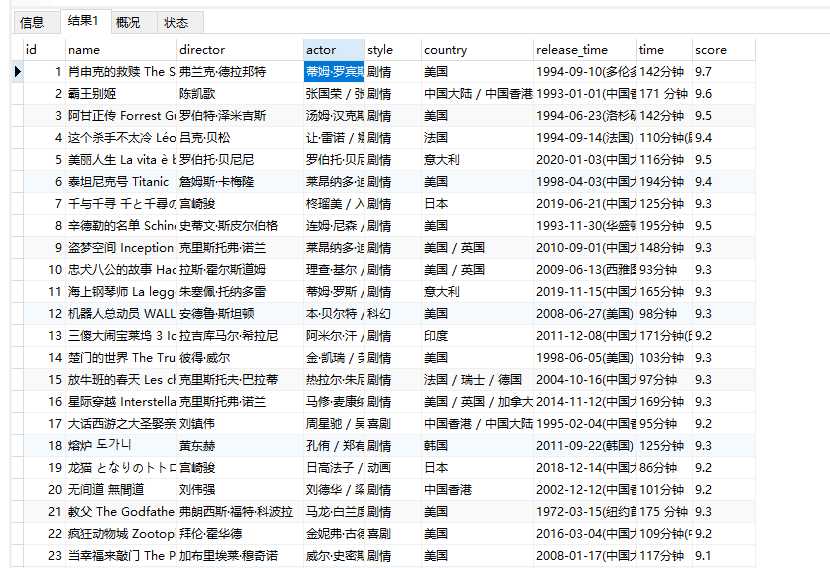
done!
mzz...
以上是关于python 爬取 豆瓣电影top250 存储到mysql的主要内容,如果未能解决你的问题,请参考以下文章