python爬虫入门爬取豆瓣电影top250
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫入门爬取豆瓣电影top250相关的知识,希望对你有一定的参考价值。
python爬虫入门(6):爬取豆瓣电影top250
本次用re库实现爬取豆瓣电影top250的第一页,
当网页换页的时候start参数会变,暂未实现爬取后续内容
有些网页的信息不直接在网页源代码中显示,有些网页会在网页源代码显示,所以要先查看网页源代码
文章目录
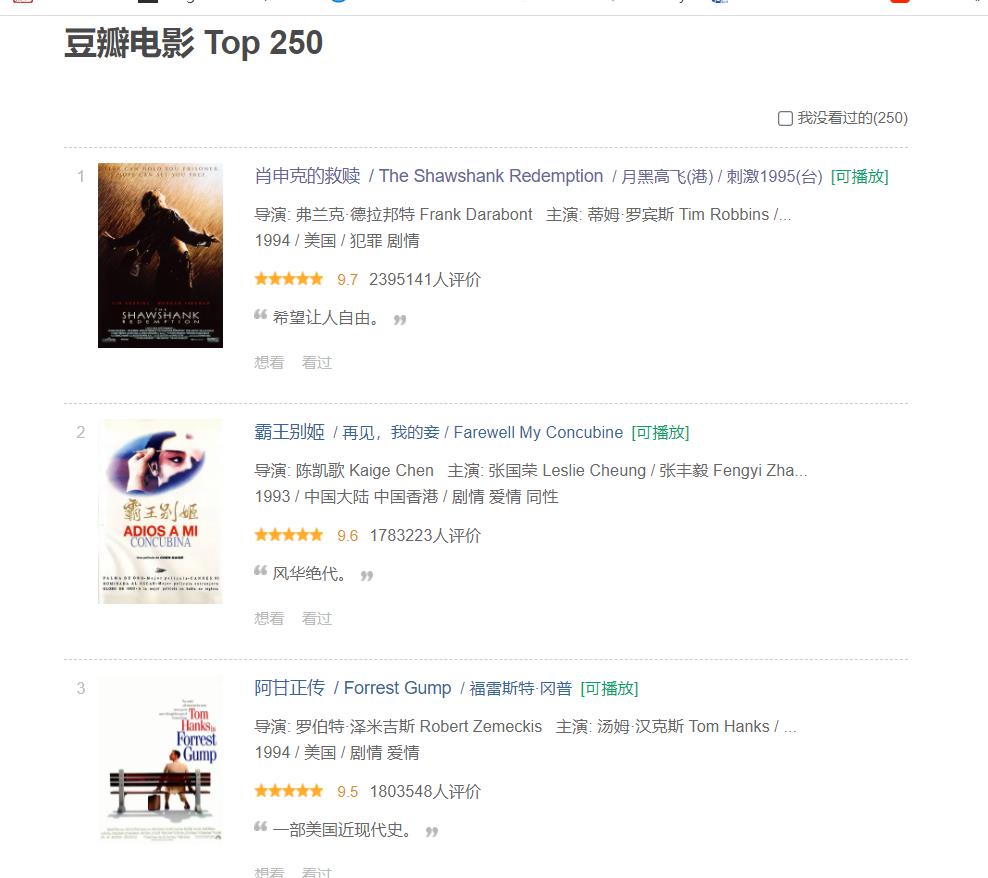

观察发现在源代码显示,所以直接提取即可
一.逐步实现提取第一页的信息
1.测试是否有反爬
先测试一下状态码
import requests
import re
url = "https://movie.douban.com/top250"
resp=requests.get(url)
print(resp.status_code)
418
返回了418,是反爬所致,所以要修改User-Agent,去网页的检查工具中复制即可
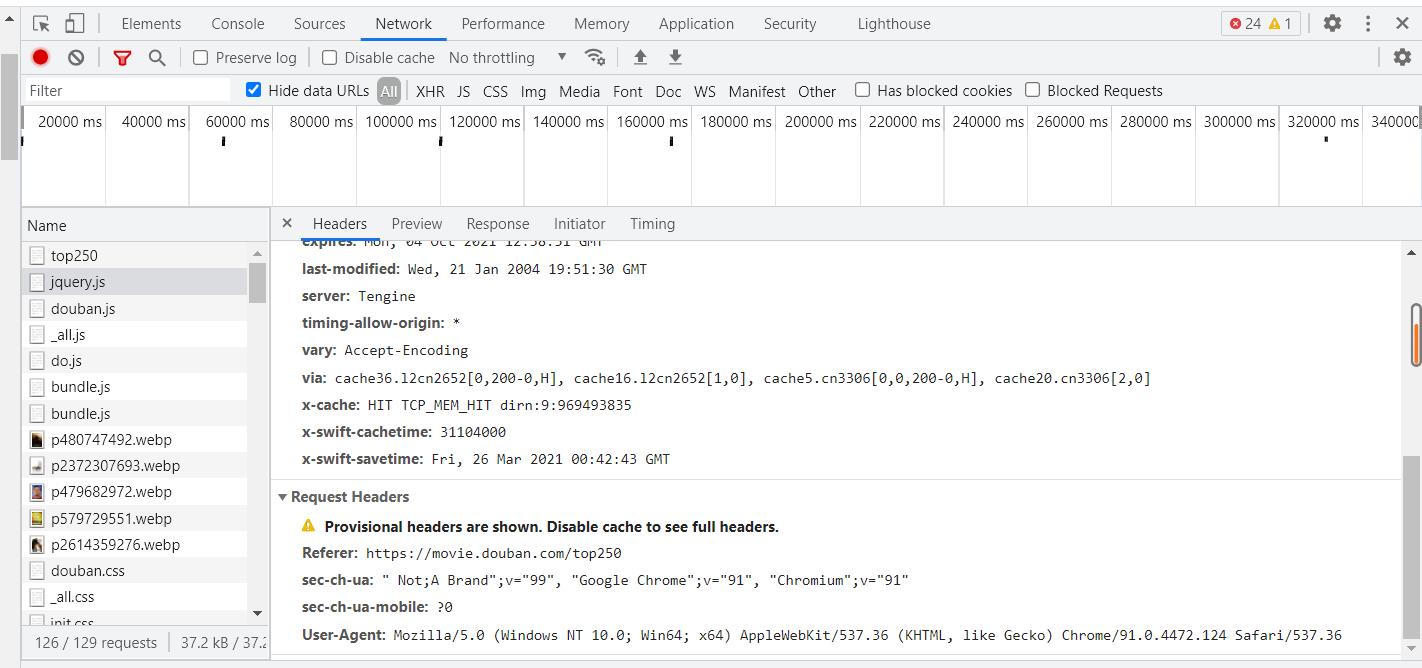
headers = {
"user-agent":"Mozilla/5.0(Windows NT 10.0 Win64 x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
resp=requests.get(url,headers=headers)
print(resp.text)
2.需求确定
爬取成功了,下面就可以用正则表达式解析了,比如需要电影名字,年份,豆瓣评分,评分人数
3.提取电影名字
以肖申克的救赎为例,分析网页源代码

从<li>为起始点,<li>后面可能是空格可能是换行
正则表达式中元字符.为除了换行符以外的任意字符,量词*是重复零次或更多次
故可以用.*?来过滤掉从<li>到<div>的空格
然后找到第一个<span class="title",需要提取文字,用分组特殊格式,然后找到后一个</span>
#测试一下
obj=re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
page_content=resp.text
ret = obj.finditer(page_content)
for it in ret:
print(it.group("name"))
肖申克的救赎
霸王别姬
阿甘正传
这个杀手不太冷
泰坦尼克号
美丽人生
千与千寻
辛德勒的名单
盗梦空间
忠犬八公的故事
星际穿越
楚门的世界
海上钢琴师
三傻大闹宝莱坞
机器人总动员
放牛班的春天
无间道
疯狂动物城
大话西游之大圣娶亲
熔炉
教父
当幸福来敲门
龙猫
怦然心动
控方证人
4.提取年份
成功提取电影名字,还需提取其他的,再来提取年份
年份的主要特征就是在
<br>后面,年份后面是 ,所以提取两者之间
obj = re.compile(
r'<li>.*?<div class="item">.*?<span class="title">(?P<电影名>.*?)</span>.*?<p class="">.*?<br>(?P<年份>.*?) ', re.S)
ret = obj.finditer(page_content)
for it in ret:
print(it.group("电影名"))
print(it.group("年份"))
肖申克的救赎
1994
霸王别姬
1993
阿甘正传
1994
这个杀手不太冷
1994
泰坦尼克号
1997
美丽人生
1997
千与千寻
2001
辛德勒的名单
1993
盗梦空间
2010
忠犬八公的故事
2009
星际穿越
2014
楚门的世界
1998
海上钢琴师
1998
三傻大闹宝莱坞
2009
机器人总动员
2008
放牛班的春天
2004
无间道
2002
疯狂动物城
2016
大话西游之大圣娶亲
1995
熔炉
2011
教父
1972
当幸福来敲门
2006
龙猫
1988
怦然心动
2010
控方证人
1957
空白处理
输出时发现,年份前面有很多空白

#处理空白
for it in ret:
print(it.group("电影名"))
print(it.group("年份").strip())
5.提取评分
obj = re.compile(
r'<li>.*?<div class="item">.*?<span class="title">(?P<电影名>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<年份>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<评分>.*?)</span>', re.S)
ret = obj.finditer(page_content)
for it in ret:
print(it.group("电影名"))
print(it.group("年份").strip())
print(it.group("评分"))
肖申克的救赎
1994
9.7
霸王别姬
1993
9.6
阿甘正传
1994
9.5
这个杀手不太冷
1994
9.4
泰坦尼克号
1997
9.4
美丽人生
1997
9.6
千与千寻
2001
9.4
辛德勒的名单
1993
9.5
盗梦空间
2010
9.3
忠犬八公的故事
2009
9.4
星际穿越
2014
9.3
楚门的世界
1998
9.3
海上钢琴师
1998
9.3
三傻大闹宝莱坞
2009
9.2
机器人总动员
2008
9.3
放牛班的春天
2004
9.3
无间道
2002
9.3
疯狂动物城
2016
9.2
大话西游之大圣娶亲
1995
9.2
熔炉
2011
9.3
教父
1972
9.3
当幸福来敲门
2006
9.1
龙猫
1988
9.2
怦然心动
2010
9.1
控方证人
1957
9.6
6.提取评价人数
obj = re.compile(
r'<li>.*?<div class="item">.*?<span class="title">(?P<电影名>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<年份>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<评分>.*?)</span>'
r'.*?<span>(?P<评价人数>.*?)人评价</span>', re.S)
ret = obj.finditer(page_content)
for it in ret:
print(it.group("电影名"))
print(it.group("年份").strip())
print(it.group("评分"))
print(it.group("评价人数"))
肖申克的救赎
1994
9.7
2395163
霸王别姬
1993
9.6
1783223
阿甘正传
1994
9.5
1803548
这个杀手不太冷
1994
9.4
1973360
泰坦尼克号
1997
9.4
1765007
美丽人生
1997
9.6
1107201
千与千寻
2001
9.4
1881025
辛德勒的名单
1993
9.5
919972
盗梦空间
2010
9.3
1737340
忠犬八公的故事
2009
9.4
1194386
星际穿越
2014
9.3
1410599
楚门的世界
1998
9.3
1328734
海上钢琴师
1998
9.3
1411518
三傻大闹宝莱坞
2009
9.2
1585025
机器人总动员
2008
9.3
1114849
放牛班的春天
2004
9.3
1099838
无间道
2002
9.3
1076211
疯狂动物城
2016
9.2
1558670
大话西游之大圣娶亲
1995
9.2
1285309
熔炉
2011
9.3
779743
教父
1972
9.3
782546
当幸福来敲门
2006
9.1
1274866
龙猫
1988
9.2
1064305
怦然心动
2010
9.1
1514132
控方证人
1957
9.6
380037
7.保存数据
将数据整理成字典格式,保存到csv文件
import csv
f=open("data.csv",mode="w")
csvwriter = csv.writer(f)
obj = re.compile(
r'<li>.*?<div class="item">.*?<span class="title">(?P<电影名>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<年份>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<评分>.*?)</span>'
r'.*?<span>(?P<评价人数>.*?)人评价</span>', re.S)
ret = obj.finditer(page_content)
for it in ret:
dic = it.groupdict("")
dic['年份']=dic['年份'].strip()
csvwriter.writerow(dic.values())
f.close()
print("Done!")
Done!
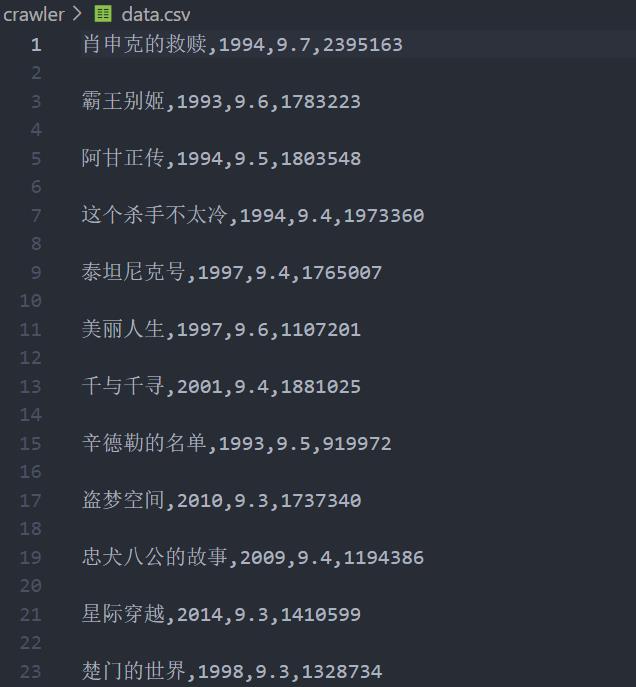
文件保存如下:
8.完整代码
上文是ipynb直接导出的代码,所以前面的各个代码块都不是完整的
import re
import requests
import csv
url = "https://movie.douban.com/top250"
headers = {
"user-agent": "Mozilla/5.0(Windows NT 10.0 Win64 x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
resp = requests.get(url, headers=headers)
page_content = resp.text
f = open("info.csv", mode="w")
csvwriter = csv.writer(f)
obj = re.compile(
r'<li>.*?<div class="item">.*?<span class="title">(?P<电影名>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<年份>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<评分>.*?)</span>'
r'.*?<span>(?P<评价人数>.*?)人评价</span>', re.S)
ret = obj.finditer(page_content)
for it in ret:
# print(it.group("电影名"))
# print(it.group("年份").strip())
# print(it.group("评分"))
# print(it.group("评价人数"))
dic = it.groupdict("")
dic['年份'] = dic['年份'].strip()
csvwriter.writerow(dic.values())
f.close()
print("Done!")
二.提取top250
翻页时发现,
url中只有start这个参数会变
每页有25个电影信息,每翻一页,start就增加25

这两个url是一样的页面


1.每页保存一个文件
一开始发现,如果没有下面代码中的
i=n/25,最后出来的csv文件是空白的(是因为覆盖吗?)
import re
import requests
import csv
headers = {
"user-agent": "Mozilla/5.0(Windows NT 10.0 Win64 x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
if __name__ == '__main__':
for n in range(0, 275, 25):
url=f"https://movie.douban.com/top250?start={n}"
resp = requests.get(url,headers=headers)
i=n/25
page_content = resp.text
f = open(f"info{i}.csv", mode="w")
# f=open("information.csv",mode="w")
csvwriter = csv.writer(f)
obj = re.compile(
r'<li>.*?<div class="item">.*?<span class="title">(?P<电影名>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<年份>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<评分>.*?)</span>'
r'.*?<span>(?P<评价人数>.*?)人评价</span>', re.S)
ret = obj.finditer(page_content)
for it in ret:
dic = it.groupdict("")
dic['年份'] = dic['年份'].strip()
csvwriter.writerow(dic.values())
f.close()
2.成功存入一个文件
import re
import requests
import csv
headers = {
"user-agent": "Mozilla/5.0(Windows NT 10.0 Win64 x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
if __name__ == '__main__':
for n in range(0, 275, 25):
url=f"https://movie.douban.com/top250?start={n}"
resp = requests.get(url,headers=headers)
page_content = resp.text
f = open(f"information_try.csv", mode="a")
csvwriter = csv.writer(f)
obj = re.compile(
r'<li>.*?<div class="item">.*?<span class="title">(?P<电影名>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<年份>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<评分>.*?)</span>'
r'.*?<span>(?P<评价人数>.*?)人评价</span>', re.S)
ret = obj.finditer(page_content)
for it in ret:
dic = it.groupdict("")
dic['年份'] = dic['年份'].strip()
csvwriter.writerow(dic.values())
f.close()
三.遇到的问题
1.测试提取电影标题时正则表达式
obj=re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
我把r''改成r""时就报错显示invalid syntax,是因为和item,title的双引号会混淆吗?
2.为啥提取年份那里会有空白呢
3.汇总代码时
汇总完整代码时,发现输出一直是空的(csv文件一直没有东西写进来),一开始以为是爬取太多被拒绝了,后来才发现,原来是忘了修改headers
4.提取top250存入一个文件
mode="a+"依旧失败,
mode="a"成功了,
但a+也是追加,为啥会覆盖呢?目前还没有细究(其实就是语法不过关🐶🐶)
保存了两个链接:
以上是关于python爬虫入门爬取豆瓣电影top250的主要内容,如果未能解决你的问题,请参考以下文章