用Python来揭秘吃瓜群众是如何看待罗志祥事件的
Posted 7758520lzy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python来揭秘吃瓜群众是如何看待罗志祥事件的相关的知识,希望对你有一定的参考价值。

前言
最近娱乐圈可以说得上是热闹非凡,前有霸道总裁爱小三,正宫撕逼网红女,后有阳光大男孩罗志祥,被周扬青扒的名声扫地。贵圈的爱情故事,常人是难以理解的,正如贾旭明张康这段相声所说的这样,娱乐圈的爱情总是分分合合,成为老百姓茶余饭后的谈资,城外的人想进去,城里的人真会玩。

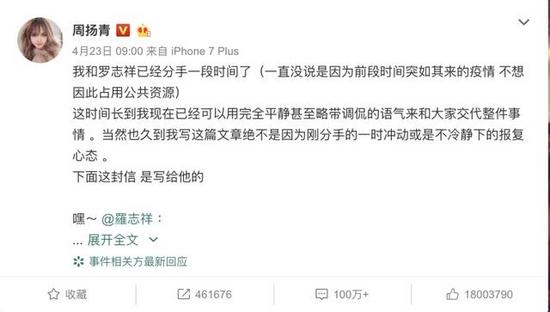
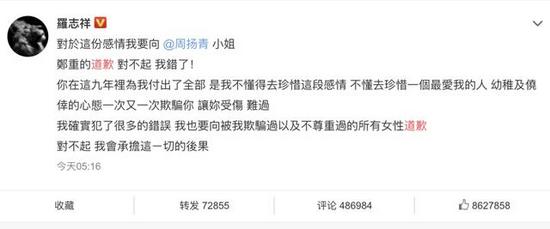
各种版本的洗白、谣言遍地乱飞,吃瓜网友们是如何看待的呢?
用数据说话,是数据工作者的意义所在,整个数据分析的过程分为三步:
- 数据获取
- 数据预处理
- 数据可视化及数据分析
以下是具体步骤和代码实现:
数据获取
数据获取地址:
‘http://ent.163.com/20/0423/09/FASTLQ7I00038FO9.html‘
在爬取评论数据之前,我们需要按F12对评论数据网页进行分析,可以发现共计172页,offset从0开始,每增加一页offset增加30,可以使用get方法获取。
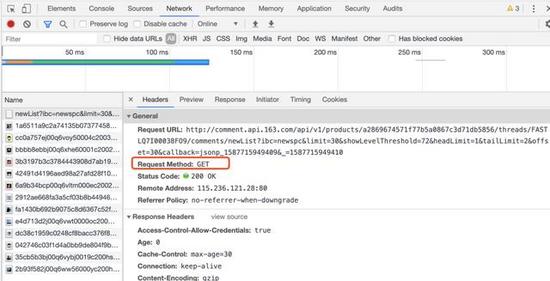
核心代码:
headers = {‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36‘}
# 评论地址
url="http://comment.api.163.com/api/v1/products/a2869674571f77b5a0867c3d71db5856/threads/FASTLQ7I00038FO9/comments/newList?ibc=newspc&limit=30&showLevelThreshold=72&headLimit=1&tailLimit=2&offset={}"
# 循环爬取
df = pd.DataFrame(None)
i = 0
while True:
ret = requests.get(url.format(str(i*30)), headers=headers)
text = ret.text
result = json.loads(text)
t = result[‘comments‘].values()
s = json_normalize(t)
i += 1
if len(s) == 0:
print("爬取结束")
break
else:
df = df.append(s)
print("第{}页爬取完毕".format(i))
df.to_csv(‘data.csv‘)
数据展示
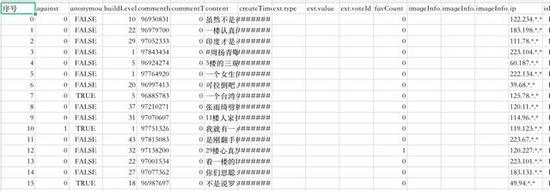
数据预处理
数据预处理是数据可视化之前非常重要的一部分。包含数据读取、评论去重、数据格式转换等
import pandas as pd
#数据读取
df = pd.read_csv(‘data.csv‘)
# 评论去重
df=df.drop_duplicates(‘commentId‘).reset_index(drop=True)
#格式转换
df[‘new_time‘] = df.apply(lambda x : x[‘createTime‘].split(‘:‘,1)[0],axis=1)
数据分析及可视化
1.事件关注指数
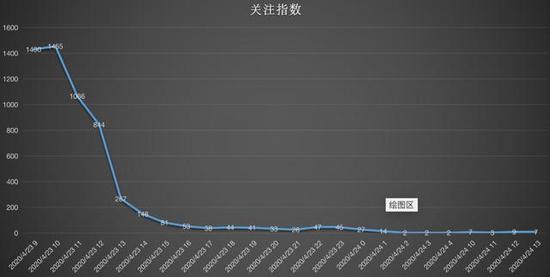
从周扬青的微博、头条等平台的推送时间为4月23日9点,时间很准,足以说明为了这次离婚声明已准备有一段时间,绝非冲动所为。从发送内容上看,声明中开头略有调侃,后面刀刀见血,文笔也润色了不少。在事件发生后,关注指数来看,23日10点评论指数达到高峰,之后评论逐步减少。
2.网友评论词语分析

从词云图中我们不难看出,很多人为周扬青打抱不平,跟随九年,最后闹得如此收场。隔着屏幕,都可以感受到大众对罗志祥人品的愤怒,当然也能看着吃瓜群众的呵呵声。艺人是公众人物,一言一行都会给社会,特别青少年群体带来深远的影响。人品不仅仅是镜头下的人品,更是生活中的人品。“始于颜值,陷于才华,忠于人品”是大众对胡歌的赞誉,也是老百姓对文艺工作者的期许,这是罗志祥要改正的地方。
核心代码
import jieba.analyse
import os
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType, ThemeType
from pyecharts.charts import Page
from pyecharts import options as opts
def get_comment_word(df):
# 集合形式存储-去重
stop_words = set()
print(stop_words)
# 加载停用词
cwd = os.getcwd()
stop_words_path = cwd + ‘/stop_words.txt‘
print(stop_words_path)
with open(stop_words_path, ‘r‘, encoding="ISO-8859-1") as sw:
for line in sw.readlines():
stop_words.add(line.strip())
print(stop_words)
# 合并评论信息
df_comment_all = df[‘content‘].str.cat()
# 使用TF-IDF算法提取关键词
word_num = jieba.analyse.extract_tags(df_comment_all, topK=300, withWeight=True, allowPOS=())
print(word_num)
# 做一步筛选
word_num_selected = []
# 筛选掉停用词
for i in word_num:
if i[0] not in stop_words:
word_num_selected.append(i)
else:
pass
return word_num_selected
3.爱留言的吃瓜群众来自何处
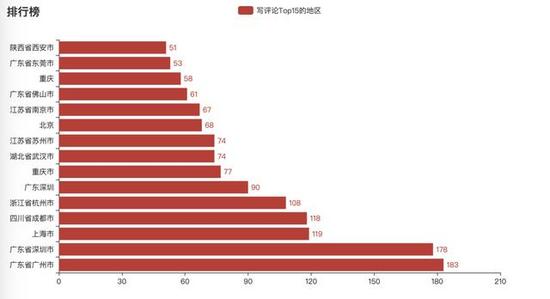
从上述图表中,我们可以看到广州、深圳、上海的网友留言位列前三名,喜欢评论的人基本处于一线城市、准一线城市,一方面是由于人口聚集量比较大,另外一方面为这些城市信息流通比较快。
核心代码
from snapshot_selenium import snapshot as driver
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.render import make_snapshot
df = df.groupby([‘user.location‘]).agg({‘序号‘:‘count‘}).reset_index()
df.rename(columns={‘place‘:‘user.location‘}, inplace=True)
df = df[~df[‘user.location‘].isin([‘上海‘,‘中国‘,‘来自火星‘,‘火星‘])]
df = df.sort_values([‘序号‘],axis = 0,ascending = False)
df_gb_top = df[:15]
def bar_chart() -> Bar:
c = (
Bar()
.add_xaxis(list(df_gb_top[‘user.location‘]))
.add_yaxis("写评论Top15的地区", list(df_gb_top[‘序号‘]))
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="排行榜"))
)
return c以上是关于用Python来揭秘吃瓜群众是如何看待罗志祥事件的的主要内容,如果未能解决你的问题,请参考以下文章