python`最简单的爬虫`实现
Posted a16n
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python`最简单的爬虫`实现相关的知识,希望对你有一定的参考价值。
不管怎么样,一天一更的好习惯一定要保持,现在一天不写点东西都感觉不踏实,总会感觉少了点什么,废话少说,记录一下今天初学的spider(甚至说不上是spider,I‘m so vagetable [/认真])
下面是最朴素(垃圾)的源码爬取脚本,源码爬取其实是没必要的,但是为了练习+学习,这种记录还是有必要的,上python
import requests #没有这个包就pip install requests
url = input("请输入要爬取源码的网站的URL:")
html = requests.get(url) #源码获取
text = html.text #源码转换为text文本
#其实上面两步可以合为
#text = requests.get(url).text这样
#文件操作
txt = open(‘D:///1.txt‘,"wb+") #打开(没有就新建)文件操作,跟c++有些不同吧
txt.write(text.encode(‘utf-8‘)) #文本编码为utf-8
print("txt文件已经生成在了 D:1.txt 路径下")
加上个input("")多人性化,直接在powershell就能用了(当然你要有python3环境变量)
上一下我测试的截图。
首先是我要爬取的网页截图
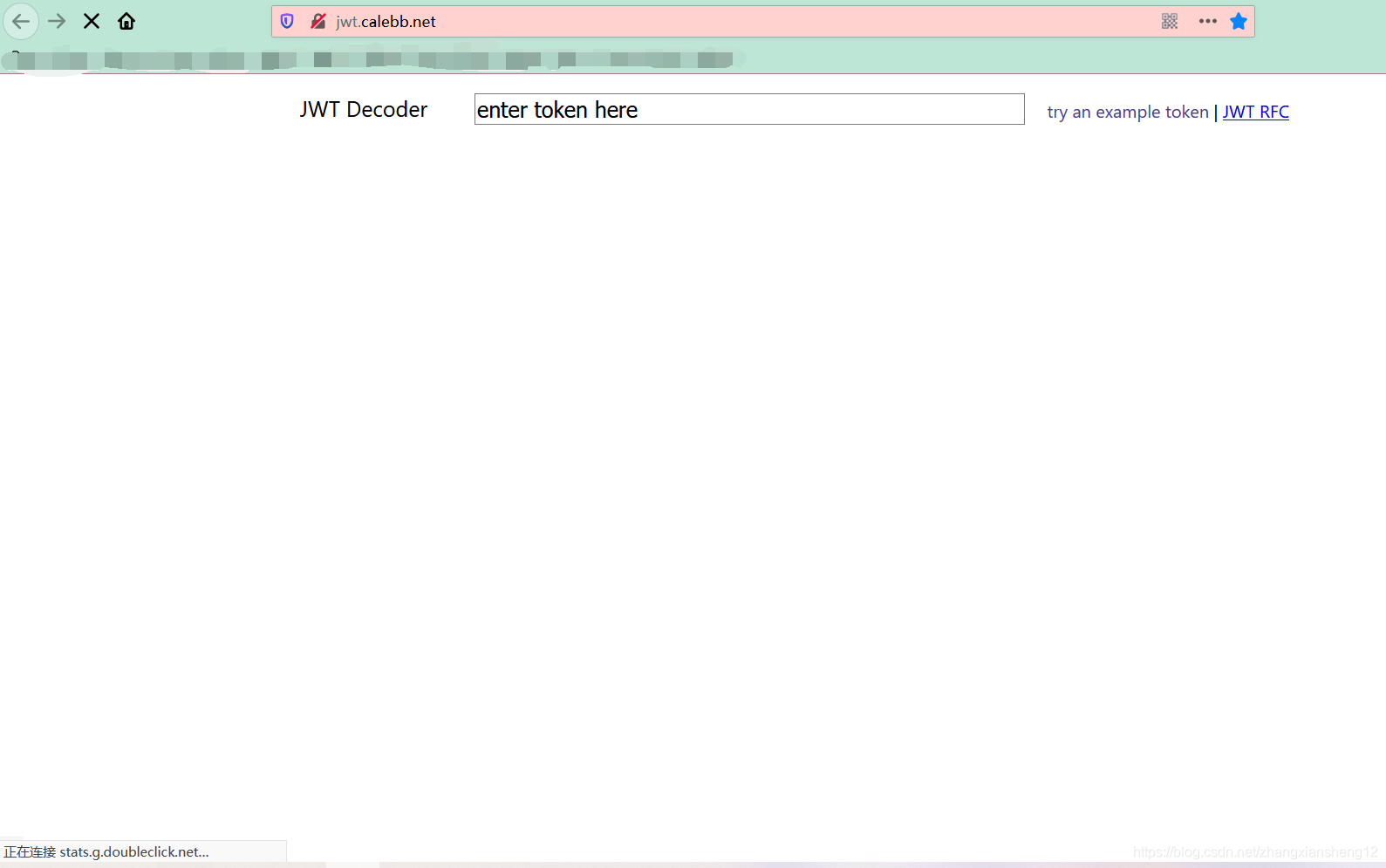 这里专门挑了个最简洁的网页
这里专门挑了个最简洁的网页
代码power shell运行

文件内容展示
 这应该是资源爬取的第一步吧,.md(你知道这只是后缀名),万里长征刚迈开第一步。
这应该是资源爬取的第一步吧,.md(你知道这只是后缀名),万里长征刚迈开第一步。
以上是关于python`最简单的爬虫`实现的主要内容,如果未能解决你的问题,请参考以下文章