python 全栈 linux基础 (部分)正则表达式 grep sed
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 全栈 linux基础 (部分)正则表达式 grep sed相关的知识,希望对你有一定的参考价值。
/etc/profile
/etc/bashrc 、变量添加到shell环境中,永久生效。
/root/.bashrc
/root/.bash_profile
正则表达式
定义:正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。(被命令所解释)
三种文本处理工具/命令:grep sed awk
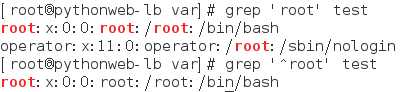
grep(过滤)
参数
-n :显示行号

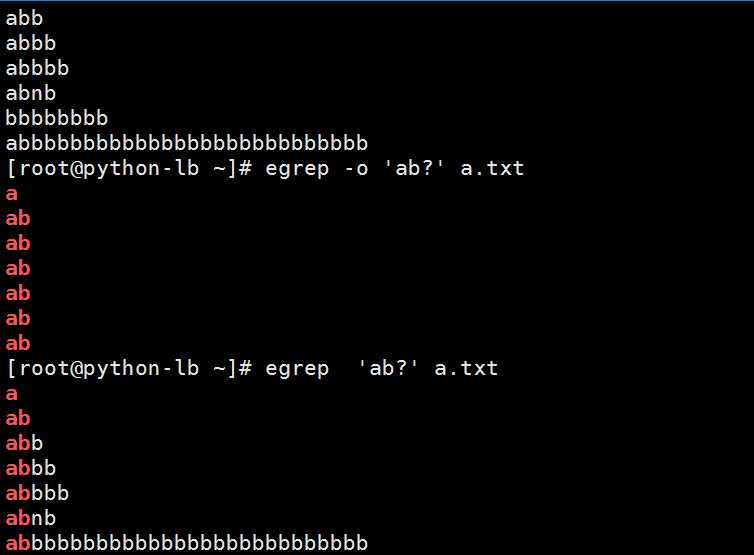
-o :只显示匹配的内容

-q :静默模式,没有任何输出,得用$?来判断执行成功没有,即有没有过滤到想要的内容

-l :如果匹配成功,则只将文件名打印出来,失败则不打印,通常-rl一起用,
grep -rl ‘root‘ /etc

-A :如果匹配成功,则将匹配行及其后n行一起打印出来(常用于日志文件)

-B :如果匹配成功,则将匹配行及其前n行一起打印出来

-C :如果匹配成功,则将匹配行及其前后n行一起打印出来
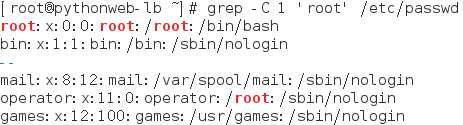
-c :如果匹配成功,则将匹配到的行数打印出来
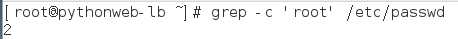
-E :等于egrep,扩展
grep -E ==== egrep
-i :忽略大小写,对搜索过滤文件直接输出

-v :取反,不匹配

-w:匹配单词 连续的字母,碰上一个空格就作为单词处理

正则介绍
^ 行首 过滤 以***开头的行(*代表任意文本)
$ 行尾 过滤 以***结尾的行(*代表任意文本)

. 除了换行符以外的任意单个字符

* 前面的字符有零个或无穷个


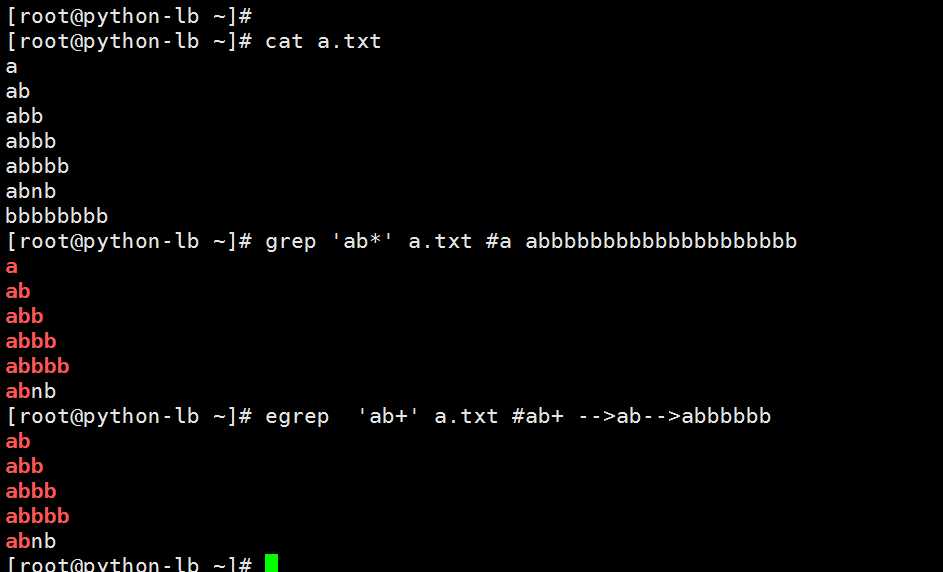

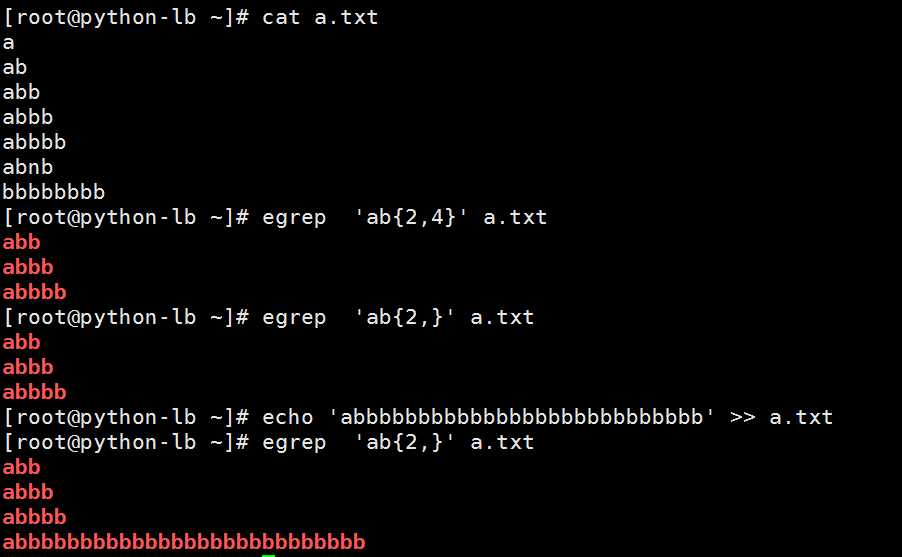
.* 所有字符

[] 字符组内的任一字符 \\表示转义符,同时 - 智能放于开头或是结尾






[^] 对字符组内的每个字符取反(不匹配字符组内的每个字符)
^[^] 非字符组内的字符开头的行

[a-z] 小写字母
[A-Z] 大写字母
[a-Z] 小写和大写字母
[0-9] 数字
\\< 单词头 单词一般以空格或特殊字符做分隔,连续的字符串被当做单词
\\> 单词尾
-v取反过滤掉需要剔除的文件。
sed
定义:流编辑器 stream editer,是以行为单位的处理程序
-n:静默模式,不打印输出
-e:指定扩展规则
-i:对文件进行更改
-f : 把‘‘规则写入文件
1、定位 :sed ‘3‘ test
2、d 删除 sed ‘3d’test :删除第3行
3、p 复制 sed ‘3p‘ test :打印第三行,(重新复制输出)
4、c 更改 sed ‘3c‘ 11111111 test : 改变第三行的文件
5、a 追加 sed ‘3a‘ 11111111 test : 在第三行之后追加文件
6、 i 插入sed ‘3i‘ 1111111 test : 在第三行之前插入一行文件.
正则定位 然后再操作 只写命令不定位,定所有文件内的位置
sed ‘/正则表达/命令‘ test
1、sed ‘/^root/d‘ test 删除root这一行;
sed ‘1,3d‘ test 删除1到3行;
sed ‘1d;3d‘ test 删除第一行和第三行
2、s命令 替换 把什么东西换成什么东西 命令: sed ‘///s‘ 文件
sed ‘s/cd/234/‘ a.txt 一行之中匹配到多个,默认只改一个
sed ‘s/cd/234/g‘ a.txt 一行之中匹配到多个全部替换
()将代码扩成一个整体
sed -r 扩展正则,(默认使用!!!)
sed -r ‘/^[0-9]([a-Z]{3)xsb$/s/sb/SB/g‘ a.txt 倒着从后往前推好理解
将第一行的第一个单词替换掉
sed -r ‘s/^([a-Z]+)([^a-Z]+)/ \\1 \\2 /g‘ test
1个单词 符号 取第一部分 取第二部分
将最后一个单词去掉
sed -r ‘s/([^a-z])([a-z]+)$/\\1/g‘ test
两个单词互换位置
sed -r ‘s/^([a-z]+)([^a-z]+)([a-z]+)([^a-z]+)/\\3\\2\\1\\4/g‘ test
以上是关于python 全栈 linux基础 (部分)正则表达式 grep sed的主要内容,如果未能解决你的问题,请参考以下文章
Python全栈100天学习笔记Day32 Linux概述及基础命令
python 全栈 python基础 (二十一)logging日志模块 json序列化 正则表达式(re)
Python全栈100天学习笔记Day32 Linux概述及基础命令