python 全栈 python基础 (二十一)logging日志模块 json序列化 正则表达式(re)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 全栈 python基础 (二十一)logging日志模块 json序列化 正则表达式(re)相关的知识,希望对你有一定的参考价值。
一、日志模块
两种配置方式:1、config函数 2、logger
#1、config函数 不能输出到屏幕
#2、logger对象 (获取别人的信息,需要两个数据流:文件流和屏幕流需要将数据从两个数据流中接收)
1、函数式简单配置
import logging logging.debug(‘debug message‘) logging.info(‘info message‘) logging.warning(‘warning message‘) logging.error(‘error message‘) logging.critical(‘critical message‘)
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置:
2)config函数样式
import logging #config logging.basicConfig(level=logging.DEBUG, #设置文件等级 format=‘%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s‘, datefmt=‘%a, %d %b %Y %H:%M:%S‘, filename=‘/tmp/test.log‘, filemode=‘w‘) logging.debug(‘debug message‘) logging.info(‘info message‘) logging.warning(‘warning message‘) logging.error(‘error message‘) logging.critical(‘critical message‘)
配置参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
3)logger对象配置方式:
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别。
import logging #logger对象 logger = logging.getLogger() #创建一个logger对象 logger.setLevel(logging.DEBUG) #设置输出等级 fm = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘) #设置文件编写格式 fh = logging.FileHandler(‘b.log‘) #创建一个hander 负责产生文件数据 sh = logging.StreamHandler() #创建一个hander 负责产生屏幕数据 fh.setFormatter(fm) #设置格式 sh.setFormatter(fm) #设置格式 logger.addHandler(fh) #接收文件的数据流 logger.addHandler(sh) ##接收屏幕的数据流 logger.debug(‘logger debug message‘) logger.info(‘logger info message‘) logger.warning(‘logger warning message‘) logger.error(‘logger error message‘) logger.critical(‘日志信息‘)
二、序列化模块 json (可支持跨语言之间的转换!)
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
1、什么是序列化
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化。
1)json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。JSON表示的对象就是标准的JavaScript语言的对象一个子集,JSON和Python内置的数据类型对应如下:
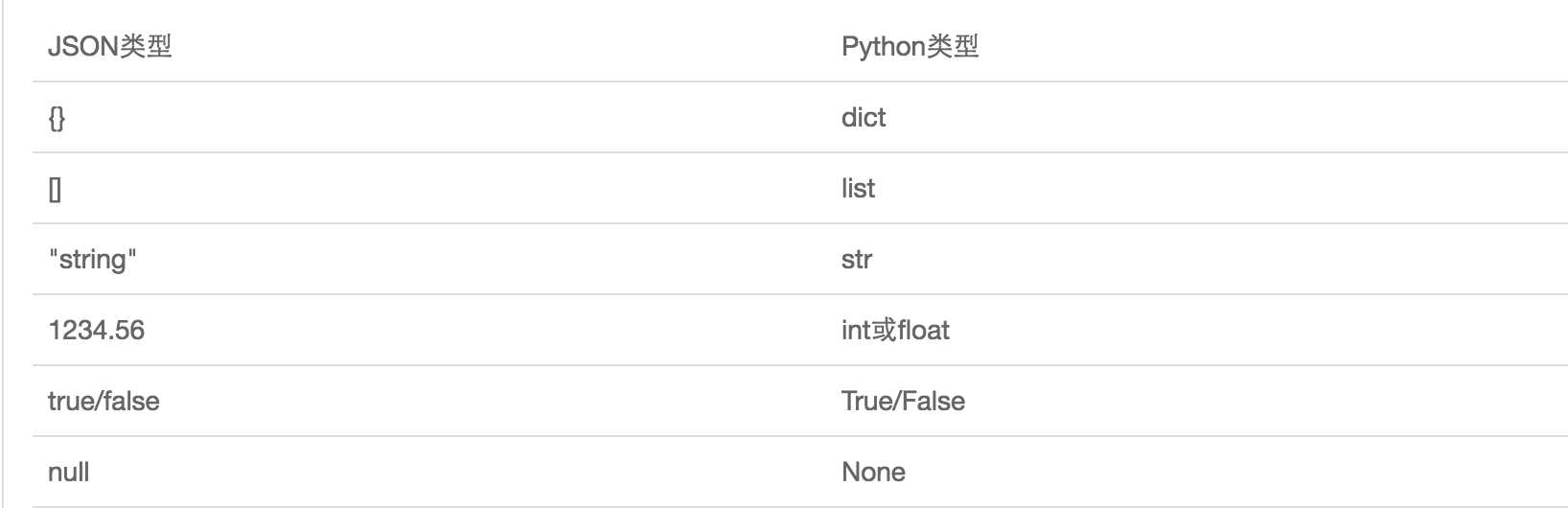
序列化:json.dumps()
反序列化:json.loads() #只要是json字符串,就能反序列化回去
import json d = {‘name‘:‘egon‘} s = json.dumps(d) #将字典d转为json字符串 序列化过程 print(type(s)) print(s) #注意转换的引号,由单引号转成了双引号。形成json字符串 data = json.loads(s) #反序列过程 print(data[‘name‘]) #执行结果: <class ‘str‘> {"name": "egon"} egon
#dump方式 用于文件操作,省掉了write
# # -------------- dump方式 用于文件操作中,先将数据序列化然后写入文件中! import json d={‘name‘:"egon"} f=open("new2",‘w‘) json.dump(d,f)#---------1 将字典d转成json字符串 2 将json字符串写入f里(!注意参数顺序!) f.close() f=open("new2") print(f.read()) f.close()
2)pickle 仅在python中进行序列化转换,可对任意类型的数据进行序列化转换。
操作与json一样,但是转换的数据为bytes格式,不可查看
#----------------------------------pickle-------------------- import pickle import datetime t=datetime.datetime.now() d={"data":t} print(d) s=pickle.dumps(d) #序列化 print(s,type(s)) #查看序列化的内容,数据类型 s1 = pickle.loads(s) #反序列化 print(s1,type(s1)) #查看序列化的内容,数据类型
三、正则表达式 re 模块
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
正则就是给字符串操作得。
爬虫里会大量用到字符串。要处理一定是对字符串处理。
正则表达式是模糊匹配,这就是正则表达式得真正关键所在。
匹配是一个一个对应的关系,匹配上就放进自己的列表中。
1.正则表达式(元字符):只对字符串进行操作
1)操作 一个字符
通配符 点 . 可以替换除了换行符(\\n)所有字符, 通配符(一个字符)没有跳过之说。
2)操作 重复字符(操作元字符前的一个字符)
* 代表:0到无穷次
+ 代表:1到无穷次
? 代表:0到1次
{} {r,m}代表:有r-m次
\\d 代表:0-9 的 数字
[] 字符集 中括号内的字符是或的关系,只要匹配到其中一个就可以。
在字符集中还要注意:*,+ . 等元字符都代表的是普通符号, 而 - ^ \\
[^2] 字符集内的 ^ 是取反的意思。及除字符集内的条件其他的都符合,[\\d] 表示的还是数字!
3)有特殊意义的字符:
- 代表:什么到什么 的意思 例如:[1-9]
^ 开始匹配 从字符串开始位置匹配
$ 结尾匹配 从字符串结尾位置匹配
() 分组 优先匹配分组的内容
(?:内容) 表示取消分组的优先级
| 管道符 表示 或的意思
\\ 转义符 将有意义的符号转成无意义的,将无意义的转换成有意义的
1、后面加上一个元字符使其变成普通符号 比如:\\. \\*
2、将一些普通符号变成特殊符号 比如:\\d \\w
2、re方法
re.findall(pattern , string) 找到所有的匹配元素,返回列表
re.finditer() #将拿到的东西整成一个可迭代的对象
re.search; 只匹配第一个结果,匹配到就不再向下匹配,返回一个内存地址,通过.group()的方式获取匹配的字符串
re.match:只在字符串开始的位置匹配
re.split(规则,字符串) 分割 以前边的规则表达式为条件分隔符,对字符串进行分割!可在后边限制分割次数
re.sub() 替换
ret4 = re.sub(规则,替换内容,原字符串,次数) 返回一个字符串
re.subn() 替换 返回一个元组(内容,替换次数)
re.compile(规则) 编译规则
c = compile(‘\\d+‘) 可操作多个字符串
ret5 = c.findall(‘hello32world‘)
print(ret5)
贪婪匹配与非贪婪匹配!

命名分组:

整体代码如下:
# 正则:对字符串的模糊匹配 # key:元字符(有特殊功能的字符) import re #元字符 # . :匹配除\\n以外的任意符号 print(re.findall("a.+d","abcd")) # ^:从字符串开始位置匹配 # $:从字符串结尾匹配 print(re.findall("^yuan","yuandashj342jhg234")) print(re.findall("yuan$","yuandashj342jhg234yuan")) # * + ? {} :重复 print(re.findall("[0-9]{4}","af5324jh523hgj34gkhg53453")) #贪婪匹配 print(re.findall("\\d+","af5324jh523hgj34gkhg53453")) #非贪婪匹配 print(re.findall("\\d+?","af5324jh523hgj34gkhg53453")) print(re.findall("(abc\\d)*?","af5324jh523hgj34gkhg53453")) # 字符集 []: 起一个或者的意思 print(re.findall("a[bc]d","hasdabdjhacd")) #注意: * ,+.等元字符都是普通符号, - ^ \\ print(re.findall("[0-9]+","dashj342jhg234")) print(re.findall("[a-z]+","dashj342jhg234")) print(re.findall("[^\\d]+","d2a2fhj87fgj")) # ():分组 print(re.findall("(ad)+","addd")) print(re.findall("(ad)+yuan","adddyuangfsdui")) print(re.findall("(?:ad)+yuan","adadyuangfsdui")) print(re.findall("(?:\\d)+yuan","adad678423yuang4234fsdui")) #命名分组 ret8=re.search(r"(?P<A>\\w+)\\\\aticles\\\\(?P<id>\\d{4})",r"yuan\\aticles\\1234") ret8=re.search(r"a\\\\nb",r"a\\nb") print(ret8) print(ret8.group("id")) print(ret8.group("A")) # # | :或 print(re.findall("www\\.(?:oldboy|baidu)\\.com","www.oldboy.com")) # \\:转义 # 1 后面加一个元字符使其变成普通符号 \\. \\* # 2 将一些普通符号变成特殊符号 比如 \\d \\w print(re.findall("\\d+\\.?\\d*\\*\\d+\\.?\\d*","-2*6+7*45+1.456*3-8/4")) print(re.findall("\\w","[email protected] 234")) print(re.findall("a\\sb","a badf")) print(re.findall("\\\\bI","hello I am LIA")) print(re.findall(r"\\dI","hello 654I am LIA")) print(re.findall(r"c\\\\l","abc\\l")) # re的方法 # re.findall() # re.findall(pattern, string) # 找到所有的匹配元素,返回列表 #获得迭代器对象 s=re.finditer("\\d+","ad324das32") print(s) print(next(s).group()) print(next(s).group()) # "(3+7*2+27+7+(4/2+1))+3" # search;只匹配第一个结果 ret=re.search("\\d+","djksf34asd3") print(ret.group()) # #match:只在字符串开始的位置匹配 ret=re.match("\\d+","423djksf34asd3") print(ret.group()) #split 分割 s2=re.split("\\d+","fhd3245jskf54skf453sd",2) print(s2) ret3=re.split("l","hello yuan") print(ret3) # #sub: 替换 ret4=re.sub("\\d+","A","hello 234jkhh23",1) print(ret4) ret4=re.subn("\\d+","A","hello 234jkhh23") print(ret4) #compile: 编译方法 c=re.compile("\\d+") ret5=c.findall("hello32world53") #== re.findall("\\d+","hello32world53") print(ret5)
以上是关于python 全栈 python基础 (二十一)logging日志模块 json序列化 正则表达式(re)的主要内容,如果未能解决你的问题,请参考以下文章