python之算法
Posted 黑墨罗少
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之算法相关的知识,希望对你有一定的参考价值。
python之算法
这个合格程序员还是需要熟练掌握一些算法的,今天主要介绍一些排序算法
递归是算法中一个比较核心的概念,有三个特点,
-
1 调用自身
-
2 具有结束条件
-
3 代码规模逐渐减少
以下四个函数只有两个为递归

这里需要注意一些 fun3和fun4输出的结果是不一样的
fun3:5,4,3,2,1
fun4:1,2,3,4,5
也只有3和4是递归
这里介绍一个汉诺塔的问题:
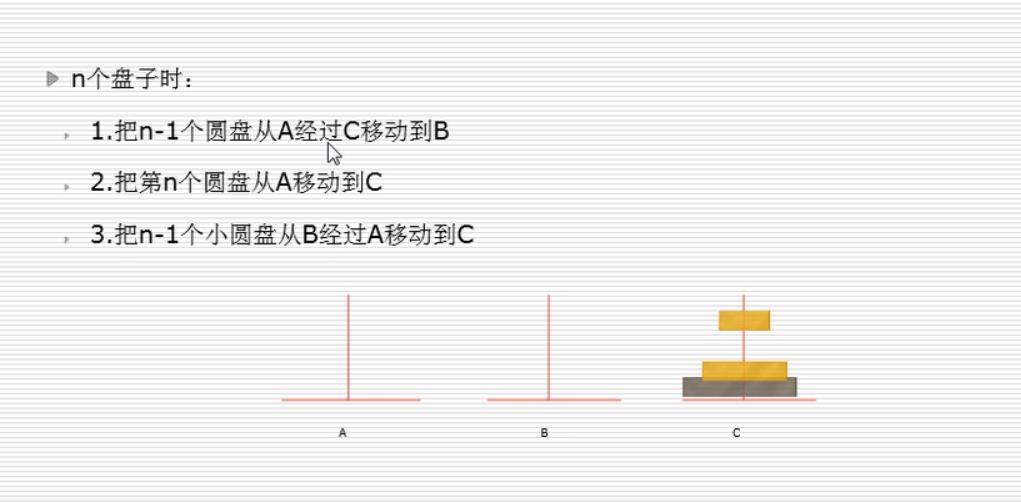
def hanoi(n , A , B , C): # n 个盘子从A经过B 到C if n >0: hanoi(n-1,A , C ,B) print("%s --->%S"%(A , C)) hanoi(n-1 , B , A ,C ) hanoi(4 , A , B ,C)
两个概念:时间复杂度和空间复杂度
时间复杂度:用于体现算法执行时间的快慢,用O表示。一般常用的有:几次循环就为O(n几次方) 循环减半的O(logn)
空间复杂度:用来评估算法内存占用大小的一个式子,通常情况下会选择使用空间换时间
e.g 列表查找:从列表中查找指定元素
输入:列表、待查找元素
输出:元素下标或未查找到元素
version 1 顺序查找:从列表中的第一个元素开始,顺序进行搜索,直到找到为止,复杂度为O(n)
version 2 二分查找:从有序列表中,通过待查值与中间值比较,以减半的方式进行查找,复杂度为O(logn)
代码如下:
list = [1,2,3,4,5,6,7,8,9]
element = 7
def ord_sear(list,element):
for i in range(0,len(list)):
if list[i] == element:
print(\'list[{0}]={1}\'.format(i,element))
return i
else:
print(\'not found\')
def bin_sear(list,element):
low = 0
high = len(list)-1
while low<=high:
mid = (low+high)//2
if element == list[mid]:
print(\'list[{0}]={1}\'.format(mid,element))
return mid
elif element > list[mid]:
low =mid +1
else:
high =mid -1
return None
i = bin_sear(list,element)
j = ord_sear(list,element)
二分查找虽然在时间复杂度上优于顺序查找,但是有比较苛刻的条件,即列表必须为有序的。下面将介绍列表排序:
首先介绍的是最简单的三种排序方式:(low B三人组)
-
1 冒泡排序
-
2 选择排序
-
3 插入排序
写一个计算时间的装饰器
import time def cal_time(func): def wrapper(*args , **kwargs): t1 = time.time() result = func(*args , **kwargs) t2 = time.time() print("%s running time : %s secs " %(func.__name__ , t2-t1)) return result return wrapper
冒泡排序:时间复杂度: O(n²)
(思路):首先,列表每俩个相邻的数,如果前面的比后面的大,那么交换这俩个数.......
from cal_time import cal_time @cal_time def bubble_sort(li): for i in range(0 , len(li)-1): # i 表示第i趟 有序区有i个数 for j in range(0 , len(li)-i-1): if li[j] > li[j+1]: li[j],li[j+1] = li[j+1] , li[j] import random li = list(range(1000)) random.shuffle(li) bubble_sort(li) print(li)
小优化一下
如果冒泡排序中执行一趟而没有交换,则列表已经是有序状态,可以直接结束
def bubble_sort2(li): for i in range(0 , len(li)-1): # i 表示第i趟 有序区有i个数 exchange = False for j in range(0 , len(li)-i-1): if li[j] > li[j+1]: li[j],li[j+1] = li[j+1] , li[j] exchange = True if not exchange: return
选择排序:时间复杂度: O(n²)
一趟遍历记录最小的数,放到第一个位置
再一趟遍历剩下列表中最小的数,继续放置:
from cal_time import cal_time @cal_time def select_sort(li): for i in range(len(li)-1): # 第i趟 , 有序区li[0:i] 无序区li[i : n] min_loc = i for j in range(i+1, len(li)): if li[min_loc] > li[j]: min_loc = j li[min_loc], li[i] = li[i], li[min_loc] import random li = list(range(10000)) random.shuffle(li) select_sort(li) print(li)
插入排序 时间复杂度: O(n²)
列表被分为有序区和无序区俩个部分,最初的有序区只有一个元素.
每次无序区选择一个元素,插入到有序区的位置,直到无序区变空
from cal_time import cal_time @cal_time def insert_sort(li): for i in range(1 , len(li)): # i 既表达趟数, 又表达摸到排的下标 j = i - 1 tmp = li[i] while j >=0 and li[j] > tmp: li[j+1] = li[j] j = j -1 li[j + 1] = tmp import random li = list(range(10000)) random.shuffle(li) insert_sort(li) print(li)
牛逼三人组
- 快速排序
- 堆排序
- 归并排序
快速排序
快速排序思路
- 取一个元素p(第一个元素),使得元素p归位
- 列表被p分成俩部分,左边都比p小, 右边都比p大
- 递归完成排序
from cal_time import cal_time def _quick_sort(li , left , right): if left < right: mid = partition(li , left , right) _quick_sort(li, left, mid-1) _quick_sort(li, mid+1 , right) @cal_time def quick_sort(li): _quick_sort(li , 0 , len(li)-1) def partition(data , left , right): tmp = data[left] while left < right: while left < right and data[right] >= tmp: right -= 1 data[left] = data[right] while left < right and data[left] <= tmp: left += 1 data[right] = data[left] data[left] = tmp return left import random li = list(range(10000)) random.shuffle(li) quick_sort(li) print(li)
堆排序
树:
树是一种数据结构(比如目录),树是一种可以递归的数据结构,相关的概念有根节点、叶子节点,树的深度(高度),树的度(最多的节点),孩子节点/父节点,子树等。
在树中最特殊的就是二叉树(度不超过2的树),二叉树又分为满二叉树和完全二叉树,见下图:

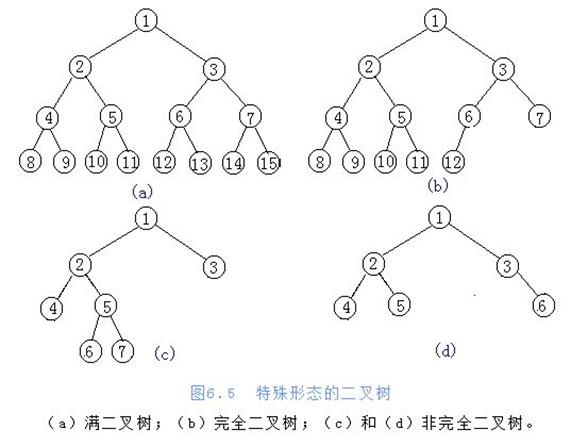
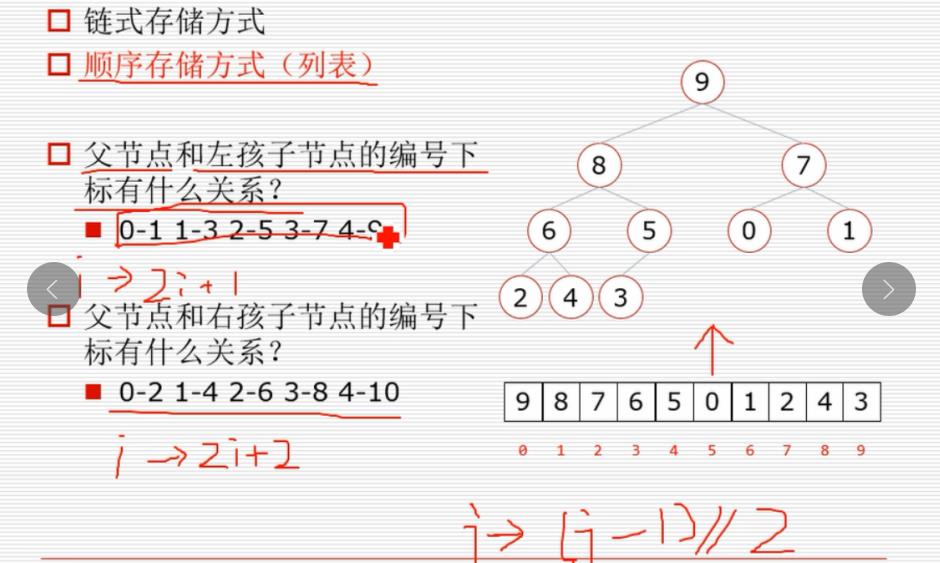
知道了树就可以说说堆了,堆分为大根堆和小根堆,分别的定义为:一棵完全二叉树,满足任一节点都比其孩子节点大或者小。
堆排序过程:
- 建立堆
- 得到堆顶元素,为最大元素
- 去掉堆顶,将堆最后一个元素放到堆顶,此时可以通过一次调整重新使堆变的有序
- 堆顶元素为第二大元素
- 重复步骤3,直到堆变空
from cal_time import cal_time def sift(li, low, high): tmp = li[low]# 原省长 i = low j = 2 * i + 1 while j <= high: #第二种退出条件: j > high if j < high and li[j+1] > li[j]: # 如果左孩子存在大于右孩子 j += 1 if tmp < li[j]: li[i] = li[j] i = j j = 2 * i + 1 else: # 第一种退出条件:li[j] <=tmp li[i] = tmp break li[i] = tmp @cal_time def heap_sort(li): n = len(li) #1 建堆 for i in range(n // 2 - 1, -1, -1): sift(li , 0 , i-1) # 2 挨个出数 for i in range(n-1, -1, -1): #i 表示此时堆的high的位置 li[0], li[i] = li[i], li[0] # 退休 + 旗子 sift(li , 0 , i-1) import random li = list(range(10000)) random.shuffle(li) heap_sort(li) print(li)
内置模块

归并排序:
假设列表中可以被分成两个有序的子列表,如何将这两个子列表合成为一个有序的列表成为归并
原理
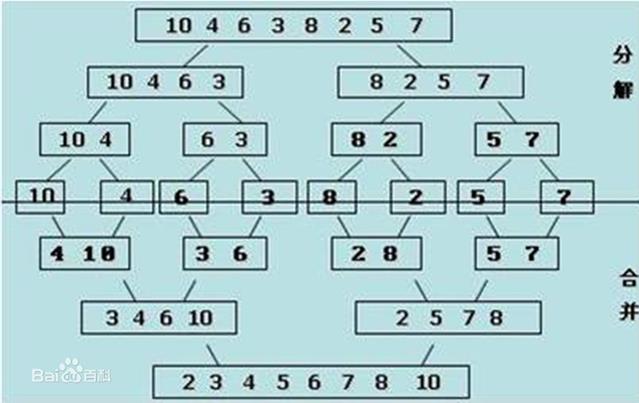
from cal_time import cal_time # 一次归并 def merge(li , low , mid , high): i = low j = mid + 1 ltmp = [] while i <= mid and j <= high: if li[i] <= li[j]: ltmp.append(li[i]) i += 1 else: ltmp.append(li[j]) j += 1 while i <= mid: ltmp.append(li[i]) i += 1 while j <= high: j += 1 li[low:high+1] = ltmp @cal_time def merge_sort(li, low , high): if low > high: mid = (low + high) // 2 merge_sort(li , low , mid) merge_sort(li,mid+1 , high) merge(li ,low , mid, high)
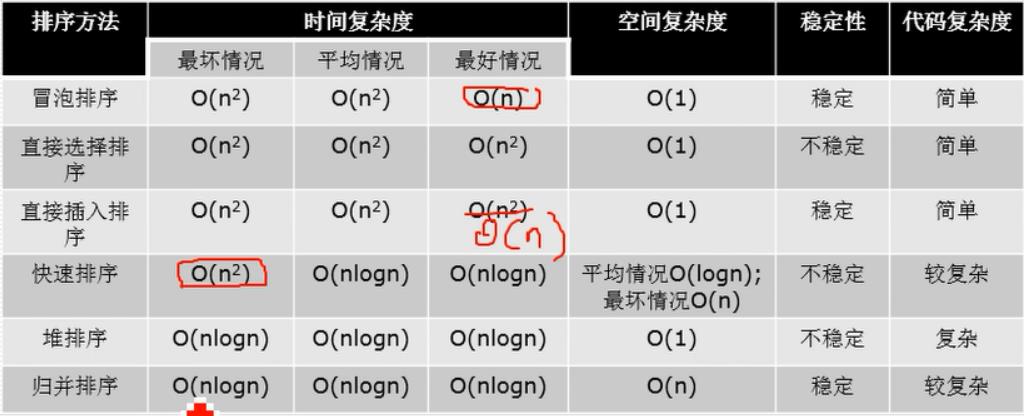
快排,堆排,归并的总结:
- 时间复杂度都是O(nlogn)
- 快排<归并<堆排(一般情况)
- 快排的缺点:极端情况效率较低,可到O(n^2),归并则是需要额外的开销,堆排则在排序算法中相对较慢
以上是关于python之算法的主要内容,如果未能解决你的问题,请参考以下文章
有人可以解释啥是 SVN 平分算法吗?理论上和通过代码片段[重复]