LLVM IR类型系统结构分析
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LLVM IR类型系统结构分析相关的知识,希望对你有一定的参考价值。
LLVM IR类型系统结构分析
类型系统是LLVM IR最重要的特性之一,强类型有利于在LLVM IR上开启大量优化。
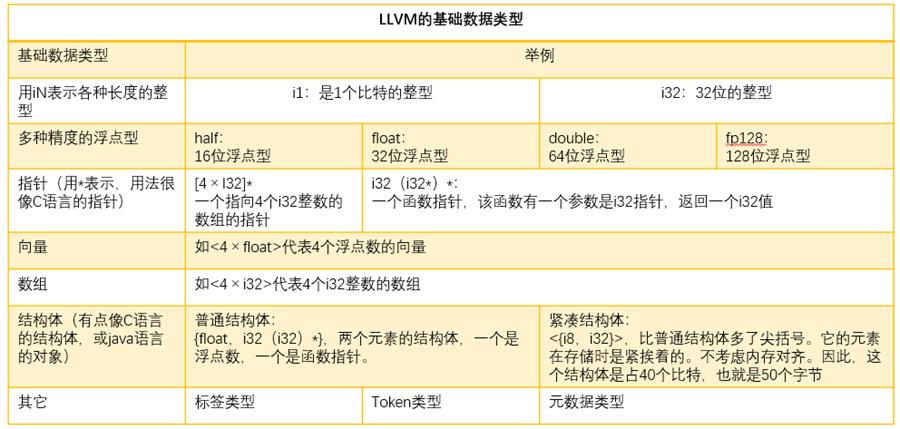
1. void类型
void类型代表无类型,与C/C++中的
void同义,例如下面这段IR中定义了一个名为nop的void函数define
void nop() 2. 函数类型
可以将函数类型看做函数签名,它由返回类型和形参类型列表组成,返回类型可以是
void类型或除label和metadata类型以外的一等类型格式如下
<returntype>
(<parameter list>)其中
<parameter list>是逗号分隔的类型列表,其中可能包括...类型(可变数量参数类型)。以下列举了几种函数类型的示例
; 返回类型为i32且只有一个i32参数的函数
i32
(i32) ; 一个返回类型为float且参数类型为i16和i32*的函数指针
float
(i16, i32 *) * ; 可变数量参数的函数, 这其实是printf函数的签名
i32
(i8*, ...) ; 返回类型为包含两个i32的结构体,参数类型为一个i32的函数
i32,
i32 (i32)3. 一等类型
在LLVM IR中,一等类型的值只能由指令运算得出;一等类型包括:
1)单值类型
A. 整数类型
B. 浮点类型
C. X86_mmx类型D. 指针类型
E. 向量类型
2)标签类型
3)令牌类型
4)元数据类型
5)复杂类型
6)数组类型
7)结构体类型
8)抽象结构体类型
显然,
void类型和函数类型就不是一等类型,因为它们不能通过指令运算得出4. 单值类型
这些类型是从CodeGen的角度看来在寄存器中有效的类型
5. 整数类型
整数类型是一个非常简单的类型,它简单地为所需的整数类型指定一个任意的数据宽度。可以指定从1到2^23 -1(约8百万)位的任何数据宽度。
语法格式
iN
其中的
N就是数据宽度,例如; 单位整数类型, 可以表示布尔类型
i1
; 最常见的32位整数类型
i32
; 数据宽度超过100万位的超级大整数类型
i1942652
6. 浮点数类型
1)half:16位浮点数2)float:32位浮点数3)double:64位浮点数4)fp128:128位浮点数(其中112位尾数)5)x86_fp80:80位浮点数(X87)6)ppc_fp128:128位浮点数(两个64位)7)half,float,double和fp128的二进制格式分别对应于IEEE-754-2008标准的binary16,binary32,binary64和binary128。7. x86_mmx类型
x86_mmx类型表示在x86机器上的MMX寄存器中保存的值。允许的操作相当有限:参数和返回值,
load指令和store指令以及bitcast指令。用户指定的MMX指令表示为具有此类型的参数和结果的内部调用或asm调用。不存在这种类型的数组、向量或常量。语法格式
x86_mmx
8. 指针类型
指针类型用于指定内存位置。指针通常用于引用内存中的对象。
指针类型可能有一个可选的地址空间属性,该属性定义指向对象所在的编号地址空间。默认地址空间是数字零。非零地址空间的语义是特定于目标的。
请注意,LLVM不允许指向
void(void*)的指针,也不允许指向标签(label*)的指针,如有相关需要,请使用i8*代替语法格式
<type>
*示例
; 4个的i32的数组的指针
[4
x i32]* ; 函数指针,它接受一个i32*类型参数,返回类型是i32
i32
(i32*) * ; i32值的指针,指向驻留在地址空间#5中的值
i32
addrspace(5)*9. 向量类型
向量类型是表示元素向量的简单派生类型,用于单个指令并行操作多个基本数据(SIMD)。向量类型需要指定大小、基础原始数据类型和可伸缩属性,以表示在编译时确切硬件向量长度未知的向量。
语法格式
<
<# elements> x <elementtype> > ; 定长向量<
vscale x <# elements> x <elementtype> > ; 可伸缩向量(弹性向量)向量中的元素数量必须是一个大于0的整型常量,元素的原始类型只能是整型、浮点型和指针型。
对于可伸缩向量,元素的总数量必须是其对应的定长向量元素数量的整数倍(这个倍数称之为vscale)。vscale在编译期未知,在运行期对于所有的可伸缩向量它是一个相同硬件相关常数。虽然可伸缩向量类型的值所占用字节大小直到运行时候才能被检测出来,但在LLVM IR里它的尺寸就是个常量(只是在运行前无法得知这个常量罢了)
示例
; 4个32位整数值的向量
<4
x i32> ; 8个32位浮点值的向量
<8
x float> ; 2个64位整数值的向量
<2
x i64> ; 4个64位整数值指针的向量
<4
x i64*> ; 4个32位整数值的倍数的可伸缩向量
<vscale
x 4 x i32>10. 令牌类型
当值与指令相关联时使用token类型,但该值的所有用法不得试图反思或模糊它。因此,具有phi或select类型令牌是不合适的。
语法格式
token
11. 元数据类型
元数据类型表示嵌入的元数据。除函数参数外,不得从元数据创建派生类型。
语法格式
metadata
12. 聚合类型
聚合类型是派生类型的一个子集,可以包含多个成员类型。数组和结构是聚合类型,而向量不是聚合类型。
13. 数组类型
数组类型是一种非常简单的派生类型,它将元素按顺序排列在内存中,需要指定大小(元素数量)和元素类型。
语法格式
[<#
elements> x <elementtype>]elements是一个常数整数值; elementtype可以是任何尺寸的类型示例
; 包含40个32位整数值的数组
[40
x i32] ; 41个32位整数值的数组
[41
x i32] ; 包含4个8位整数值的数组
[4
x i8] ; 下面是多维数组
; 3x4的32位整数值数组
[3
x [4 x i32]] ; 12×10的单精度浮点数组
[12
x [10 x float]] ; 2x3x4的16位整数值数组
[2
x [3 x [4 x i16]]]除了静态类型隐含的数组末尾之外,没有对索引的限制(尽管在某些情况下索引超出了分配对象的范围)。这意味着可以在零长度数组类型的LLVM中实现单维“可变大小数组”。例如,在LLVM中实现"pascal样式数组"可以使用类型
i32, [0 x float]。14. 结构体类型(Structure Type)
结构体类型用于表示内存中一组数据成员的集合,结构体中的数据成员可以是任何具有大小的类型。
通过
getelementptr指令获取指向结构体中某个字段的指针,然后使用load和store指令访问这个指针指向的内存。寄存器中的结构体可使用extractvalue指令和insertvalue指令进行访问。还有一种稠密结构体(packed structure),按单字节对齐(也就是没有进行内存对对齐),在内存中成员字段之间没有空白填充。与之相比,一般的结构体为了按照
target-datalayout进行内存对齐,成员字段之间可能插入了一些空白填充。结构体既可以是字面量,也可以赋给标识符: - 字面量结构体以内联的方式进行定义,而标识符结构体始终在LLVM IR顶层使用名称进行定义 - 字面量结构体被其内容唯一标识,既不能是递归的,也不能是抽象的(opaque);而标识符结构体恰恰相反,既可以是递归的,也可以是抽象的
语法格式
%T1
= type <type list> ; 一般结构体类型%T2
= type < <type list> > ; 稠密结构体类型示例
i32, i32, i32 ; 包含3个i32类型的结构体 float, i32 (i32) * ; 成员是float类型和函数指针类型的结构体 <
i8, i32 > ; 5个字节大小的稠密结构体15. 抽象结构体类型(Opaque Structure Types)
抽象结构体类型用于表示没有实体的命名结构体类型,比如C语言中的前置结构体声明。
关于Opaque Pointer的详情, 请查看https://en.wikipedia.org/wiki/Opaque_pointer
语法格式
%X
= type opaque%52
= type opaque汇编语言是弱类型的,操作汇编语言的时候,实际上考虑的是一些二进制串。但是,LLVM IR却是强类型的,在LLVM IR中所有变量都必须有类型。这是因为,在使用高级语言编程的时候,往往都会使用强类型的语言,弱类型的语言无必要性,也不利于维护。因此,使用强类型语言,LLVM IR可以更好地进行优化。
1)基本的数据类型
LLVM IR中比较基本的数据类型包括:
空类型(
void)整型(
iN)2)浮点型(
float、double等)空类型一般是作为不返回值的函数的返回类型,没有特别的含义,就代表「什么都没有」。
整型是指
i1, i8, i16, i32, i64这类的数据类型。这里iN的N可以是任意正整数,可以是i3,i1942652。但最常用,最符合常理的就是i1以及8的整数倍。i1有两个值:true和false。也就是说,下面的代码可以正确编译:
%boolean_variable = alloca i1
store i1 true, i1* %boolean_variable
对于大于1位的整型,也就是如
i8, i16等类型,可以直接用数字字面量赋值:%integer_variable = alloca i32
store i32 128, i32* %integer_variable
store i32 -128, i32* %integer_variable
2)符号
有一点需要注意的是,在LLVM IR中,整型默认是有符号整型,也就是说可以直接将
-128以补码形式赋值给i32类型的变量。在LLVM IR中,整型的有无符号是体现在操作指令而非类型上的,比方说,对于两个整型变量的除法,LLVM IR分别提供了udiv和sdiv指令分别适用于无符号整型除法和有符号整型除法:%1 = udiv i8 -6, 2 ; get (256 - 6) / 2 = 125
%2 = sdiv i8 -6, 2 ; get (-6) / 2 = -3
可以用这样一个简单的程序验证:
; div_test.ll
target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.15.0"
define i8 @main()
%1 = udiv i8 -6, 2
%2 = sdiv i8 -6, 2
ret i8 %1
分别将
ret语句的参数换成%1和%2以后,将代码编译成可执行文件,在终端下运行并查看返回值即可。总结一下就是,LLVM IR中的整型默认按有符号补码存储,但一个变量究竟是否要被看作有无符号数需要看其参与的指令。
3)转换指令
与整型密切相关的就是转换指令,比如说,将
i8类型的数-127转换成i32类型的数,将i32类型的数257转换成i8类型的数等。总的来说,LLVM IR中提供三种指令:trunc .. to指令,zext .. to指令和sext .. to指令。将长的整型转换成短的整型很简单,直接把多余的高位去掉就行,LLVM IR提供的是
trunc .. to指令:%trunc_integer = trunc i32 257 to i8 ; trunc 32 bit 100000001 to 8 bit, get 1
将短的整型变成长的整型则相对比较复杂。这是因为,在补码中最高位是符号位,并不表示实际的数值。因此,如果单纯地在更高位补
0,那么i8类型的-1(补码为11111111)就会变成i32的255。这虽然符合道理,但有时候需要i8类型的-1扩展到i32时仍然是-1。LLVM IR为提供了两种指令:零扩展的zext .. to指令和符号扩展的sext .. to指令。零扩展就是最简单的,直接在高位补
0,而符号扩展则是用原数的符号位来填充。也就是说如下的代码:%zext_integer = zext i8 -1 to i32 ; extend 8 bit 0xFF to 32 bit 0x000000FF, get 255
%sext_integer = sext i8 -1 to i32 ; extend 8 bit 0xFF to 32 bit 0xFFFFFFFF, get -1
类似地,浮点型的数和整型的数也可以相互转换,使用
fptoui .. to, fptosi .. to, uitofp .. to, sitofp .. to可以分别将浮点数转换为无符号、有符号整型,将无符号、有符号整型转换为浮点数。不过有一点要注意的是,如果将大数转换为小的数,那么并不保证截断,如将浮点型的257.1转换成i8(上限为128),那么就会产生未定义行为。所以,在浮点型和整型相互转换的时候,需要在高级语言层面做一些调整,如使用饱和转换等。4)指针类型
将基本的数据类型后加上一个
*就变成了指针类型i8*, i16*, float*等。之前提到,LLVM IR中的全局变量和栈上分配的变量都是指针,所以其类型都是指针类型。在高级语言中,直接操作裸指针的机会都比较少,除非在性能极其敏感的场景下,由最厉害的大佬才能操作裸指针。这是因为,裸指针极其危险,稍有不慎就会出现段错误等致命错误,所以使用指针时应该慎之又慎。
LLVM IR为大佬们提供了操作裸指针的一些指令。在C语言中,会遇到这种场景:
int x, y;
size_t address_of_x = (size_t)&x;
size_t address_of_y = address_of_x - sizeof(int);
int also_y = *(int *)address_of_y;
这种场景比较无脑,但确实是合理的,需要将指针看作一个具体的数值进行加减。到x86_64的汇编语言层次,取地址就变成了
lea命令,解引用倒是比较正常,就是一个简单的mov。在LLVM IR层次,为了使指针能像整型一样加减,提供了
ptrtoint .. to指令和inttoptr .. to指令,分别解决将指针转换为整型,和将整型转换为指针的功能。也就是说,可以粗略地将上面的程序转写为%x = alloca i32 ; %x is of type i32*, which is the address of variable x
%y = alloca i32 ; %y is of type i32*, which is the address of variable y
%address_of_x = ptrtoint i32* %x to i64
%address_of_y = sub i64 %address_of_x, 4
%also_y = inttoptr i64 %address_of_y to i32* ; %also_y is of type i32*, which is the address of variable y
5)聚合类型
比起指针类型而言,更重要的是聚合类型。在C语言中常见的聚合类型有数组和结构体,LLVM IR也为提供了相应的支持。
数组类型很简单,要声明一个类似C语言中的
int a[4],只需要%a = alloca [4 x i32]
也就是说,C语言中的
int[4]类型在LLVM IR中可以写成[4 x i32]。注意,这里面是个x不是*。也可以使用类似地语法进行初始化:
@global_array = global [4 x i32] [i32 0, i32 1, i32 2, i32 3]
特别地,知道,字符串在底层可以看作字符组成的数组,所以LLVM IR为提供了语法糖:
@global_string = global [12 x i8] c"Hello world\\00"
在字符串中,转义字符必须以
\\xy的形式出现,其中xy是这个转义字符的ASCII码。比如说,字符串的结尾,C语言中的\\0,在LLVM IR中就表现为\\00。结构体的类型也相对比较简单,在C语言中的结构体
struct MyStruct
int x;
char y;
;
在LLVM IR中就成了
%MyStruct = type
i32,
i8
初始化一个结构体也很简单:
@global_structure = global %MyStruct i32 1, i8 0
; or
@global_structure = global i32, i8 i32 1, i8 0
值得注意的是,无论是数组还是结构体,其作为全局变量或栈上变量,依然是指针,也就是说,
@global_array的类型是[4 x i32]*, @global_structure的类型是%MyStruct*也就是 i32, i8 *。接下来的问题就是,如何对聚合类型进行操作呢?getelementptr首先,要讲的是对聚合类型的指针进行操作。一个最全面的例子,用C语言来说,就是:
struct MyStruct
int x;
int y;
;
struct MyStruct my_structs[4];
struct MyStruct *my_structs_ptr = my_structs;
有一个指向长度为4的
MyStruct类型的数组my_structs第一个元素的指针my_structs_ptr,需要的是my_structs_ptr[2].y这个数。先直接看结论,用LLVM IR来表示为
%MyStruct = type
i32,
i32
%my_structs = alloca [4 x %MyStruct]
%my_structs_ptr = getelementptr [4 x %MyStruct], [4 x %MyStruct]* @my_structs, i32 0, i32 0
%1 = getelementptr %MyStruct, %MyStruct* %my_structs_ptr, i64 2, i32 1 ; %1 is pointer to my_structs_ptr[2].y
%2 = load i32, i32* %1 ; %2 is value of my_structs_ptr[2].y
上述代码涉及两处
getelementptr,第一处由my_structs变为my_structs_ptr,第二处由my_structs_ptr得到my_structs_ptr[2].y。在C语言中,数组可以隐式转换为指针,但在LLVM中,似乎并不会那么显然。在
%my_structs_ptr = getelementptr [4 x %MyStruct], [4 x %MyStruct]* @my_structs, i64 0, i64 0
这条语句中,可以看到,
@my_structs是指向内存中长度为4的MyStruct类型的数组的指针,通过第一层的i64 0,可以得到这个指针指向的第一个元素,也就是说这个指针的偏移值为0(如果指针偏移值为1,则在内存里将偏移一整个my_structs数组的大小),第二个元素则是说明最终结果指向的是这个数组的首元素。也就是说,在LLVM IR中,会默认把所有指针看作是由数组转化来的,因此要对指针解引用时,总要先声明顶层偏移值为0。在第二处
getelementptr这个指令,其前两个参数很显然,第一个是这个聚合类型的类型,第二个则是这个聚合类型对象的指针,也就是my_structs_ptr。第三个参数,则是指明在数组中的第几个元素,第四个,则是指明在结构体中的第几个字段(LLVM IR中结构体的字段不是按名称,而是按下标索引来区分)。用人话来说,%1就是my_structs数组第2个元素的第1个字段的地址。因此,如果直接想
my_structs[2].y,LLVM IR就是%1 = getelementptr [4 x %MyStruct], [4 x %MyStruct]* %my_structs, i64 0, i64 2, i32 1 ; %1 is pointer to my_structs[2].y
为了更好地理解上述例子中第一处
getelementptr的用法,思考下面的例子:%MyStruct = type
i32,
i32
%my_struct = alloca %MyStruct
%1 = getelementptr %MyStruct, %MyStruct* %my_struct, i64 0, i32 1 ; %1 is pointer to my_struct.y
如果想根据结构体的指针获取结构体的字段,
getelementptr的第三个参数居然还需要一个i64 0。这是做什么用的呢?这里就是指数组的第一个元素,想象一下有一个C语言代码:struct MyStruct
int x;
int y;
;
struct MyStruct my_struct;
struct MyStruct* my_struct_ptr = &my_struct;
int *y_ptr = my_struct_ptr[0].y;
这里的
my_struct_ptr[0]就代表了getelementptr的第三个参数,这万万不可省略。此外,
getelementptr还可以接多个参数,类似于级联调用。有C程序:struct MyStruct
int x;
int y[5];
;
struct MyStruct my_structs[4];
那么如果想获得
my_structs[2].y[3]的地址,只需要%MyStruct = type
i32,
[5 x i32]
%my_structs = alloca [4 x %MyStruct]
%1 = getelementptr [4 x %MyStruct], [4 x %MyStruct]* %my_structs, i64 2, i32 1, i64 3
可以查看官方提供的The Often Misunderstood GEP Instruction指南更多地了解
getelementptr的机理。6)extractvalue和insertvalue除了上面讲的这种情况,也就是把结构体分配在栈或者全局变量,然后操作其指针以外,还有什么情况呢?考虑这种情况:
; extract_insert_value.ll
%MyStruct = type
i32,
i32
@my_struct = global %MyStruct i32 1, i32 2
define i32 @main()
%1 = load %MyStruct, %MyStruct* @my_struct
ret i32 0
这时,结构体是直接放在虚拟寄存器
%1里,%1并不是存储@my_struct的指针,而是直接存储这个结构体的值。这时,并不能用getelementptr来操作%1,因为这个指令需要的是一个指针。因此,LLVM IR提供了extractvalue和insertvalue指令。因此,如果要获得
@my_struct第二个字段的值,需要%2 = extractvalue %MyStruct %1, 1
这里的
1就代表第二个字段(从0开始)。类似地,如果要将
%1的第二个字段赋值为233,只需要%3 = insertvalue %MyStruct %1, i32 233, 1
然后
%3就会是%1将第二个字段赋值为233后的值。extractvalue和insertvalue并不只适用于结构体,也同样适用于存储在虚拟寄存器中的数组,这里不再赘述。7)标签类型
在汇编语言中,一切的控制语句、函数调用都是由标签来控制的,在LLVM IR中,控制语句也是需要标签来完成。
6.5.2 元数据类型
在使用Clang将C语言程序输出成LLVM IR时,会发现代码的最后几行有
!llvm.module.flags = !!0, !1, !2
!llvm.ident = !!3
!0 = !i32 2, !"SDK Version", [3 x i32] [i32 10, i32 15, i32 4]
!1 = !i32 1, !"wchar_size", i32 4
!2 = !i32 7, !"PIC Level", i32 2
!3 = !!"Apple clang version 11.0.3 (clang-1103.0.32.62)"
类似于这样的内容。
在LLVM IR中,以
!开头的标识符为元数据。元数据是为了将额外的信息附加在程序中传递给LLVM后端,使后端能够好地优化或生成代码。用于Debug的信息就是通过元数据形式传递的。可以使用-g选项:clang -S -emit-llvm -g test.c
来在LLVM IR中附加额外的Debug信息。
LLVM IR的语法指南中有专门的Metadata来解释各种元数据,这里与核心内容联系不太密切,就不再赘述了。
属性
最后,还有一种叫做属性的概念。属性并不是类型,其一般用于函数。比如说,告诉编译器这个函数不会抛出错误,不需要某些优化等。可以看到
define void @foo() nounwind
; ...
这里
nounwind就是一个属性。有时候,一个函数的属性会特别特别多,并且有多个函数都有相同的属性。那么,就会有大量重复的篇幅用来给每一个函数说明属性。因此,LLVM IR引入了属性组的概念,在将一个简单的C程序编译成LLVM IR时,会发现代码中有
attributes #0 = noinline nounwind optnone ssp uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "darwin-stkchk-strong-link" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "probe-stack"="___chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false"
这种一大长串的,就是属性组。属性组总是以
#开头。当函数需要它的时候,只需要define void @foo #0
; ...
直接使用
#0即可。
人工智能芯片与自动驾驶
获取指向 LLVM-IR 中数组第一个元素的指针
【中文标题】获取指向 LLVM-IR 中数组第一个元素的指针【英文标题】:Get pointer to first element of array in LLVM-IR 【发布时间】:2016-06-18 21:36:47 【问题描述】:我想在LLVM-IR中实现一个字符串类型,我的计划如下:
声明字符串变量时,为 i8* 分配内存。
变量初始化时,将字符串存储在某处,将指向第一个元素的指针存储在之前分配的地址,并将字符串的长度保存在成员变量中。
问题是,我无法获得指向第一个元素的指针。 使用 IRBuilder (C++ API),我已经创建了以下代码:
%str2 = alloca i8*
%1 = alloca [4 x i8]
store [4 x i8] c"foo\00", [4 x i8]* %1
%2 = getelementptr [4 x i8], [4 x i8]* %1, i32 0
store [4 x i8]* %2, i8** %str2
但在此调用 llc 会出现以下错误:
error: stored value and pointer type do not match
store [4 x i8]* %2, i8** %str2
^
当使用 clang 在相同(char* 而不是字符串)代码上发出 llvm-ir 时,它会发出以下内容:
%str2 = alloca i8*, align 8
store i8* %str, i8** %1, align 8
store i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i32 0, i32 0), i8** %str2, align 8
看起来非常相似,恕我直言,但不一样。
Clang 使字符串成为全局常量(希望这不是必需的),使用 getelementptr 的 offset 参数并将类型 i8* 赋予 store 指令。
不幸的是,我找不到任何 API 方法来显式地为 store 指令指定类型,或者使用 offset 参数(我猜这甚至没有帮助)。
所以最后我的问题是:如何正确获取指向第一个数组元素的指针并存储它?
提前致谢
【问题讨论】:
在这里查看答案,了解如何在堆栈上存储字符串***.com/questions/37101965/… 数小时的研究,我只是没有发现。谢谢你指点我! 【参考方案1】:正如评论中的链接,解决方案是将 [n x i8]* 比特转换为 i8*
%str2 = alloca i8*
%1 = alloca [4 x i8]
store [4 x i8] c"foo\00", [4 x i8]* %1
%2 = bitcast [4 x i8]* %1 to i8*
store i8* %2, i8** %str2
【讨论】:
以上是关于LLVM IR类型系统结构分析的主要内容,如果未能解决你的问题,请参考以下文章