读数据压缩入门笔记02_二进制和熵
Posted 躺柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读数据压缩入门笔记02_二进制和熵相关的知识,希望对你有一定的参考价值。
数据压缩所做的就是尽可能减少表示特定数据集时所需的二进制位数量
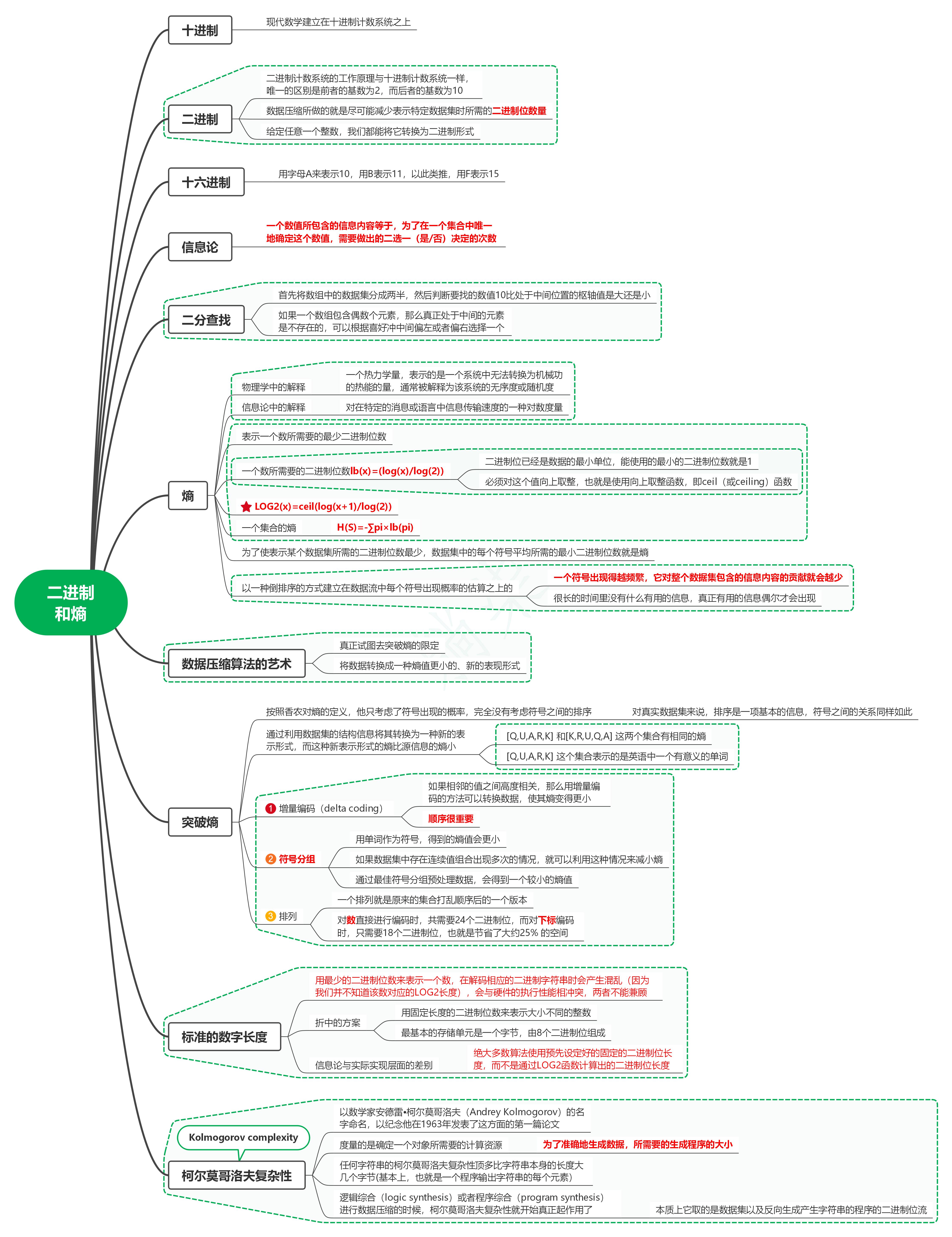
1. 十进制
1.1. 现代数学建立在十进制计数系统之上
2. 二进制
2.1. 二进制计数系统的工作原理与十进制计数系统一样,唯一的区别是前者的基数为2,而后者的基数为10
2.2. 数据压缩所做的就是尽可能减少表示特定数据集时所需的二进制位数量
2.3. 给定任意一个整数,我们都能将它转换为二进制形式
3. 十六进制
3.1. 用字母A来表示10,用B表示11,以此类推,用F表示15
4. 信息论
4.1. 一个数值所包含的信息内容等于,为了在一个集合中唯一地确定这个数值,需要做出的二选一(是/否)决定的次数
5. 二分查找
5.1. 首先将数组中的数据集分成两半,然后判断要找的数值10比处于中间位置的枢轴值是大还是小
5.2. 如果一个数组包含偶数个元素,那么真正处于中间的元素是不存在的,可以根据喜好冲中间偏左或者偏右选择一个
6. 熵
6.1. 物理学中的解释
6.1.1. 一个热力学量,表示的是一个系统中无法转换为机械功的热能的量,通常被解释为该系统的无序度或随机度
6.2. 信息论中的解释
6.2.1. 对在特定的消息或语言中信息传输速度的一种对数度量
6.3. 表示一个数所需要的最少二进制位数
6.4. 一个数所需要的二进制位数lb(x)=(log(x)/log(2))
6.4.1. 二进制位已经是数据的最小单位,能使用的最小的二进制位数就是1
6.4.2. 必须对这个值向上取整,也就是使用向上取整函数,即ceil(或ceiling)函数
6.5. LOG2(x)=ceil(log(x+1)/log(2))
6.6. 一个集合的熵
6.6.1. H(S)=-∑pi×lb(pi)
6.7. 为了使表示某个数据集所需的二进制位数最少,数据集中的每个符号平均所需的最小二进制位数就是熵
6.8. 以一种倒排序的方式建立在数据流中每个符号出现概率的估算之上的
6.8.1. 一个符号出现得越频繁,它对整个数据集包含的信息内容的贡献就会越少
6.8.2. 很长的时间里没有什么有用的信息,真正有用的信息偶尔才会出现
7. 数据压缩算法的艺术
7.1. 真正试图去突破熵的限定
7.2. 将数据转换成一种熵值更小的、新的表现形式
8. 突破熵
8.1. 按照香农对熵的定义,他只考虑了符号出现的概率,完全没有考虑符号之间的排序
8.1.1. 对真实数据集来说,排序是一项基本的信息,符号之间的关系同样如此
8.2. 通过利用数据集的结构信息将其转换为一种新的表示形式,而这种新表示形式的熵比源信息的熵小
8.2.1. [Q,U,A,R,K] 和[K,R,U,Q,A] 这两个集合有相同的熵
8.2.2. [Q,U,A,R,K] 这个集合表示的是英语中一个有意义的单词
8.3. 增量编码(delta coding)
8.3.1. 如果相邻的值之间高度相关,那么用增量编码的方法可以转换数据,使其熵变得更小
8.3.2. 顺序很重要
8.4. 符号分组
8.4.1. 用单词作为符号,得到的熵值会更小
8.4.2. 如果数据集中存在连续值组合出现多次的情况,就可以利用这种情况来减小熵
8.4.3. 通过最佳符号分组预处理数据,会得到一个较小的熵值
8.5. 排列
8.5.1. 一个排列就是原来的集合打乱顺序后的一个版本
8.5.2. 对数直接进行编码时,共需要24个二进制位,而对下标编码时,只需要18个二进制位,也就是节省了大约25% 的空间
9. 标准的数字长度
9.1. 用最少的二进制位数来表示一个数,在解码相应的二进制字符串时会产生混乱(因为我们并不知道该数对应的LOG2长度),会与硬件的执行性能相冲突,两者不能兼顾
9.2. 折中的方案
9.2.1. 用固定长度的二进制位数来表示大小不同的整数
9.2.2. 最基本的存储单元是一个字节,由8个二进制位组成
9.3. 信息论与实际实现层面的差别
9.3.1. 绝大多数算法使用预先设定好的固定的二进制位长度,而不是通过LOG2函数计算出的二进制位长度
10. 柯尔莫哥洛夫复杂性
10.1. Kolmogorov complexity
10.2. 以数学家安德雷•柯尔莫哥洛夫(Andrey Kolmogorov)的名字命名,以纪念他在1963年发表了这方面的第一篇论文
10.3. 度量的是确定一个对象所需要的计算资源
10.3.1. 为了准确地生成数据,所需要的生成程序的大小
10.4. 任何字符串的柯尔莫哥洛夫复杂性顶多比字符串本身的长度大几个字节(基本上,也就是一个程序输出字符串的每个元素)
10.5. 逻辑综合(logic synthesis)或者程序综合(program synthesis)进行数据压缩的时候,柯尔莫哥洛夫复杂性就开始真正起作用了
10.5.1. 本质上它取的是数据集以及反向生成产生字符串的程序的二进制位流
读Java性能权威指南(第2版)笔记14_垃圾回收A
1. 垃圾回收器
1.1. 对象可以在被需要时创建,不再使用时由JVM自动回收
1.2. GC是查找不再使用的对象,然后回收这些对象相关内存的过程
1.2.1. 找到不使用的对象、回收其内存、压缩堆内存
1.3. 优化垃圾回收器比跟踪指针引起的bug要容易得多(且耗时更少)
1.4. VM必须定期搜索堆中不使用的对象
1.4.1. 从GC根(GC root)对象开始搜索,GC根是可以从堆外被访问的对象,主要包括线程栈和系统类
1.4.2. 当GC算法找到不使用的对象时,JVM会回收这些对象占用的内存,并将这些内存分配给其他对象
2. 垃圾回收器运行多个线程
2.1. 一组执行应用程序逻辑,通常被称为mutator线程
2.1.1. 作为应用程序逻辑的一部分会改变对象
2.2. 另一组执行GC,当GC线程跟踪对象引用(用于回收对象)或者在内存中移动对象时,它们必须确保应用程序线程不使用这些对象
2.3. 所有线程都停止运行的停顿被称为STW停顿(stop-the-world pause)
2.3.1. 尽量减少这些停顿是优化GC的重中之重
3. 垃圾回收器分代
3.1. 分代理由
3.1.1. 大量对象(有时甚至是大多数对象)是临时对象
3.1.2. 很多对象的使用时间很短
3.2. 老年代
3.2.1. old generation或tenured generation
3.2.2. Full GC
3.2.2.1. 一般会造成应用程序线程较长时间的停顿
3.3. 新生代
3.3.1. young generation
3.3.2. 只是整个堆的一部分
3.3.2.1. 对象首先在新生代中分配
3.3.2.2. 比处理整个堆要快
3.3.3. Eden空间
3.3.3.1. 占据了新生代的绝大多数空间
3.3.3.2. 最初对象会被分配到Eden空间
3.3.3.3. 不再使用的对象被丢弃
3.3.3.4. 仍在使用的对象被移动到一个Survivor空间或者晋升到老年代
3.3.4. Survivor空间
3.3.4.1. 在回收结束时,Eden空间和一个Survivor空间被清空,新生代中剩余的对象都被压缩到另一个Survivor空间中
3.3.5. Minor GC
3.3.5.1. Young GC
3.3.5.2. 当新生代被填满时,垃圾回收器会停止所有的应用程序线程,并清空新生代
3.3.5.3. 不再使用的对象被丢弃
3.3.5.4. 仍在使用的对象被移到其他地方
4. 并发回收器
4.1. concurrent collector
4.2. 低停顿(low-pause)回收器
4.3. 无停顿(pauseless)回收器
4.4. 查找的代码可以在不停止应用程序线程的情况下运行
4.5. 代价是应用程序总体上使用更多的CPU时间
4.5.1. 避免长时间停顿是以消耗额外的CPU周期为代价的
4.6. 更难优化以达到最佳性能
5. 选型
5.1. 单个请求会受停顿时间的影响,尤其是Full GC时较长时间的停顿
5.1.1. 减少停顿对响应时间的影响,那么并发回收器可能更合适
5.2. 如果平均响应时间比异常值(例如第90百分位响应时间)更重要
5.2.1. 并发回收器可能会产生更好的结果
6. GC算法
6.1. Serial垃圾回收器
6.1.1. 最简单的回收器
6.1.2. 在只有一个CPU可用且额外的GC线程会干扰应用程序的情况下使用(而且是默认的)
6.1.2.1. 只有一个核心(甚至是以两个CPU形式出现的超线程核心)的虚拟机和Docker容器让这个算法又有了使用的意义
6.1.3. 使用单线程来处理堆
6.1.3.1. 处理堆时会停止所有的应用程序线程(不管是Minor GC还是Full GC)
6.1.3.2. 在Full GC期间,它将完全压缩老年代
6.1.4. -XX:+UseSerialGC标志可以开启
6.1.5. -XX:-UseSerialGC并不会禁用
6.1.5.1. 禁用需要设定另外一个垃圾回收器
6.2. CMS垃圾回收器
6.2.1. 第一个并发垃圾回收器
6.2.1.1. JDK 8中相当流行
6.2.1.2. 自JDK 11被正式废弃,而且不鼓励在JDK 8中使用
6.2.2. 会在Minor GC的过程中停止所有的应用程序线程
6.2.3. 主要缺陷是它不能在后台处理过程中压缩堆
6.2.4. -XX:+UseConcMarkSweepGC标志开启
6.2.4.1. 默认值是false
6.3. Throughput垃圾回收器
6.3.1. 并行回收器(parallel collector)
6.3.2. JDK8中任何有两个或者多个CPU的64位机器的默认垃圾回收器
6.3.3. -XX:+UseParallelGC标志
6.3.4. -XX:+UseParallelOldGC标志
6.3.4.1. 已经过时了
6.3.4.2. 可以禁用这个标志,只对新生代进行并行回收
6.4. G1 GC
6.4.1. 垃圾优先垃圾回收器
6.4.2. 使用并发回收策略来以最小的停顿回收堆
6.4.3. JDK 11和之后版本的默认垃圾回收器
6.4.4. -XX:+UseG1GC标志开启
以上是关于读数据压缩入门笔记02_二进制和熵的主要内容,如果未能解决你的问题,请参考以下文章
读Java性能权威指南(第2版)笔记02_ Java SE API技巧上