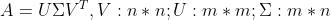2022-2023 春学期 矩阵与数值分析 C3 矩阵分析基础
Posted owuiviuwo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2022-2023 春学期 矩阵与数值分析 C3 矩阵分析基础相关的知识,希望对你有一定的参考价值。
 矩阵与数值分析第三章内容
矩阵与数值分析第三章内容
2022-2023 春学期 矩阵与数值分析 C3 矩阵分析基础
引言
本文内容来自于对矩阵与数值分析课程资料的整理;
本文所涉及的课程指东北某沿海高校,计算机学院硕士生必修课“矩阵与数值分析”,课程资料包括课程PPT、教材《计算机科学计算 第二版》[1],以及网络资料,师兄的笔记等。
C3 矩阵分析基础
3.1 矩阵序列与级数
矩阵序列相关定义与特性
矩阵序列:按整数 k 的序列,将 \\(C^m\\times n\\) 中的矩阵排成一列 \\(A_1,A_2,A_3,\\cdots,A_k,\\cdots\\),称这列有序的矩阵为矩阵为矩阵序列,称 \\(A_k\\) 为矩阵序列的一般项。
矩阵序列的发散与收敛:\\(\\A_k\\^\\infty_k=1\\) 为 \\(C^m\\times n\\) 中的矩阵序列,其中 \\(A_k=(a_ij^(k))\\),又 \\(A=a_ij\\in C^m\\times n\\),如果 \\(\\lim\\limits_k\\rightarrow\\inftya^(k)_ij=a_ij\\),对 \\(i=1,2,\\cdots,m;j=1,2,\\cdots,n\\) 均成立,则称矩阵序列 \\(\\A_k\\^\\infty_k=1\\) 收敛,而 A 称为矩阵序列 \\(\\A_k\\^\\infty_k=1\\) 的极限,记为 \\(\\lim\\limits_k\\rightarrow\\inftyA_k=A\\);不收敛的矩阵序列称为发散的。
可见矩阵序列收敛和矩阵中的元素都收敛的是相互充要的。
矩阵序列收敛性与范数:设 \\(\\A_k\\^\\infty_k=1\\) 为 \\(C^m\\times n\\) 中的矩阵序列,\\(||\\cdot||\\) 为 \\(C ^m\\times n\\) 中的一种矩阵范数,则矩阵序列 \\(\\A_k\\^\\infty_k=1\\) 收敛于 A 的充要条件是 \\(||A_k-A||\\) 收敛于零。
相关结论:设 \\(\\A_k\\^\\infty_k=1,A\\in C ^m\\times n\\) ,并且 \\(\\lim\\limits_k\\rightarrow\\inftyA_k=A\\),则 \\(\\lim\\limits_k\\rightarrow\\infty||A_k||=||A||\\);此结论只是充分条件,反过来不一定成立。
对于矩阵序列的四则运算,有:
设 \\(\\A_k\\^\\infty_k=1\\), 和 \\(\\B_k\\^\\infty_k=1\\),分别为$ C ^m\\times n$ 和 $ C ^n\\times l$,并且 \\(\\lim\\limits_k\\rightarrow\\inftyA_k=A,\\lim\\limits_k\\rightarrow\\inftyB_k=B\\),则
- \\(\\lim\\limits_k\\rightarrow\\infty(\\alpha A_k+\\beta B_k)=\\alpha A+\\beta B,\\forall\\alpha,\\beta\\in C\\)
- \\(\\lim\\limits_k\\rightarrow\\inftyA_kB_k=AB\\)
- 设 \\(\\A_k\\^\\infty_k=1,A\\in C ^n\\times n\\) 中的矩阵序列,并且 \\(\\lim\\limits_k\\rightarrow\\inftyA_k=A,A_k(k=1,2,\\cdots)\\),和 \\(A\\in C ^n\\times n\\) 均为可逆矩阵,则 \\(\\lim\\limits_k\\rightarrow\\inftyA^-1=A^-1\\);注意矩阵序列可逆不能保证极限一定可逆
- 可逆矩阵极限可能奇异,非零矩阵极限可能为零
收敛矩阵:\\(A\\in C^n\\times n,\\lim\\limits_k\\rightarrow\\inftyA^k=0\\)
定理:\\(\\rho(A)<1\\) 的充要条件是:存在 \\(C^n\\times n\\) 上的某种范数 \\(||\\cdot||\\) ,使得 \\(||A||<1\\)
定理:设 \\(C^n\\times n\\),\\(\\lim\\limits_k\\rightarrow\\inftyA^k=0\\) 的充分必要条件是存在 \\(C^n\\times n\\) 上的某种范数 \\(||\\cdot||\\) ,使得 \\(||A||<1\\)
所以有:
\\(\\rho(A)<1\\Leftrightarrow\\lim\\limits_k\\rightarrow\\inftyA^k=0\\Leftrightarrow任意 \\ ||A||<1\\)
判断一个矩阵是否为收敛矩阵:
- 若 \\(A^k\\) 容易计算,则利用其判断收敛性
- 判断矩阵的某种范数是否小于 1
- 计算矩阵的谱半径
例题





矩阵级数相关定义与结论
定义:设 \\(\\A_k\\^\\infty_k=1\\) 为 \\(C ^m\\times n\\) 中的矩阵序列,称
为由矩阵序列 \\(\\A_k\\^\\infty_k=1\\) 构成的矩阵级数,记为 \\(\\sum\\limits^\\infty_k=1A_k\\)
定义:记 \\(S_k=\\sum\\limits^k_i=1A_i\\),称之为矩阵级数 \\(\\sum\\limits^\\infty_k=1A_k\\) 的前 k 项部分和,若矩阵序列 \\(\\S_k\\^\\infty_k=1\\) 收敛且 \\(\\lim\\limits_k\\rightarrow\\inftyS_k=S\\),则称矩阵级数 \\(\\sum\\limits^\\infty_k=1A_k\\) 收敛;矩阵 S 称为矩阵级数的和函数,记为 \\(S=\\sum\\limits^\\infty_k=1A_k\\)。不收敛的矩阵级数称为发散的。矩阵级数收敛即 \\(m\\times n\\) 个数项级数 \\(\\sum\\limits^\\infty_k=1a_ij^(k)\\) 均收敛。
定理:设 A 为 n 阶方阵,则 \\(\\sum\\limits_k=0^\\infty A^k=I+A+A^2+\\cdots+A^k+\\cdots\\) 收敛(\\(A^0=I\\))的充要条件是 \\(\\rho(A)<1\\)
定理:设 A 为 n 阶方阵,当 \\(\\sum\\limits_k=0^\\infty A^k\\) 收敛时,有 \\(\\sum\\limits_k=0^\\infty A^k=(I-A)^-1\\),而且存在 \\(C^n\\times n\\) 上的算子范数 \\(||\\cdot||\\),使得 \\(||(I-A)^-1-\\sum\\limits^m_k=0A^k||\\leq\\frac||A||^m+11-||A||\\)
例题




矩阵级数绝对收敛相关结论
定义:设 \\(\\sum\\limits_k=1^\\infty A_k\\) 为 \\(C^m\\times n\\) 中的矩阵级数,其中 \\(A_k=(a^(k)_ij)\\)。如果\\(\\sum\\limits_k=1^\\infty a_ij^(k)\\) 对任意的 \\(1\\leq i\\leq m,\\, 1\\leq j\\leq n\\) 均为绝对收敛的,则称矩阵级数 \\(\\sum\\limits_k=1^\\infty A_k\\) 绝对收敛。
定理:矩阵级数 \\(\\sum\\limits_k=1^\\infty A_k\\) 为绝对收敛的充要条件是正项级数 \\(\\sum\\limits_k=1^\\infty ||A_k||\\)收敛
定理:若矩阵级数 \\(\\sum\\limits_k=1^\\infty A_k\\) 是绝对收敛的,则它一定是收敛的,并且任意调换各项的顺序所得到的级数还是收敛的,且级数和不变;显然,收敛的级数不一定绝对收敛,而绝对收敛的级数一定是收敛的。
定理:设 \\(\\sum\\limits_k=1^\\infty A_k\\) 为 \\(C^m\\times n\\) 中的绝对收敛的矩阵级数,\\(A=\\sum\\limits_k=1^\\infty A_k\\),设 \\(\\sum\\limits_k=1^\\infty B_k\\) 为 \\(C^n\\times l\\) 中的绝对收敛的矩阵级数,\\(B=\\sum\\limits_k=1^\\infty B_k\\),则 \\(\\sum\\limits_k=1^\\infty A_k\\cdot\\sum\\limits_k=1^\\infty B_k\\) 按任何方式排列得到的级数绝对收敛,且和为 AB。
定理,设 \\(P\\in C^p\\times m\\) 和 \\(Q\\in C^n\\times q\\) 为给定矩阵,则 \\(\\sum\\limits_k=0^\\infty A_k\\) 收敛可以得到 \\(\\sum\\limits_k=0^\\infty PA_kQ\\) 收敛; \\(\\sum\\limits_k=0^\\infty A_k\\) 绝对收敛可以得到 \\(\\sum\\limits_k=0^\\infty PA_kQ\\) 绝对收敛;且有等式 \\(P(\\sum\\limits_k=0^\\infty A_k)Q\\)
3.2 幂级数
收敛与发散
矩阵幂级数的一般形式:\\(\\sum\\limits_k=0^\\infty a_kA^k\\)
定理:设 \\(\\sum\\limits^\\infty_k=0a_kt^k\\) 为收敛半径为 r 的幂级数,A 为 n 阶方阵,则
- \\(\\rho(A)<r\\) 时,矩阵幂级数 \\(\\sum\\limits_k=0^\\infty a_kA^k\\) 绝对收敛
- \\(\\rho(A)>r\\) 时,矩阵幂级数 \\(\\sum\\limits_k=0^\\infty a_kA^k\\) 发散
定理:设 \\(\\sum\\limits_k=0^\\infty a_k(z-z_0)^k\\) 为收敛半径为 r 的幂级数,A 为 n 阶方阵,
- 如果 A 的特征值均落在收敛圆内,即 \\(|\\lambda-z_0|<r\\),其中 \\(\\lambda\\) 为任意特征值,则矩阵幂级数 \\(\\sum\\limits_k=0^\\infty a_k(A-z_0I)^k\\) 绝对收敛
- 若有某个 \\(\\lambda_i_0\\) 使得 \\(|\\lambda_i_0-z_0|>r\\),则幂级数 \\(\\sum\\limits_k=0^\\infty a_k(A-z_0I)^k\\) 发散
幂级数与解析函数的关系


利用 Jordan 分解计算矩阵函数


定理:设 \\(f(z)=\\sum\\limits^\\infty_k=0a_kz^k\\) 是收敛半径为 r 的幂级数,J 是特征值为 \\(\\lambda\\) 的 n 阶 Jordan 块阵,且 \\(|\\lambda|<r\\),则
定理:设 \\(f(z)=\\sum\\limits^\\infty_k=0a_k(z-z_0)^k\\) 是收敛半径为 r 的幂级数,J 是特征值为 \\(\\lambda\\) 的 n 阶 Jordan 块阵,且 \\(|\\lambda-z_0|<r\\),则
定理:设 \\(f(z)=\\sum\\limits^\\infty_k=0a_kz^k\\) 是收敛半径为 r 的幂级数,J 是特征值为 \\(\\lambda\\) 的 n 阶 Jordan 块阵,且 \\(|t\\lambda|<r\\),则
定理(利用矩阵的 Jordan 分解求矩阵函数 f(A) 的具体表达式):设 \\(f(z)=\\sum\\limits^\\infty_k=0a_k(z-z_0)^k\\) 为收敛半径为 r 的幂级数,A 为 n 阶方阵,\\(A=TJT^-1\\) 为其 Jordan 分解, \\(J=\\mathrmdiag(J_1,J_2,\\cdots,J_s)\\);当 A 的特征值均落在收敛圆内时,即 \\(|\\lambda-z_0|<r\\),其中 \\(\\lambda\\) 为 A 的任意特征值,则矩阵幂级数 \\(\\sum\\limits^\\infty_k=0a_k(z-z_0)^k\\) 绝对收敛,并且和矩阵为:
其中 \\(f(J_i)\\) 的定义如前表达式。
注意,若 A 的特征值为 \\(\\lambda_1,\\lambda_2,\\cdots,\\lambda_n\\),则 f(A) 的特征值应为 \\(f(\\lambda_1),f(\\lambda_2),\\cdots,f(\\lambda_n)\\)
计算矩阵函数值的基本步骤:
- 计算 Jordan 分解 \\(A=TJT^-1=T\\mathrmdiag(J_1,\\cdots,J_s)T^-1\\)
- 求 \\(f(A)=T\\mathrmdiag(f(J_1),\\cdots,f(J_s))T^-1\\)
例题

已知 \\(J_i=\\beginpmatrix-1&1&&\\\\ &-1&1\\\\&&-1&1\\\\&&&-1\\endpmatrix\\),求 \\(e^J_i,\\;e^tJ_i\\)
解:
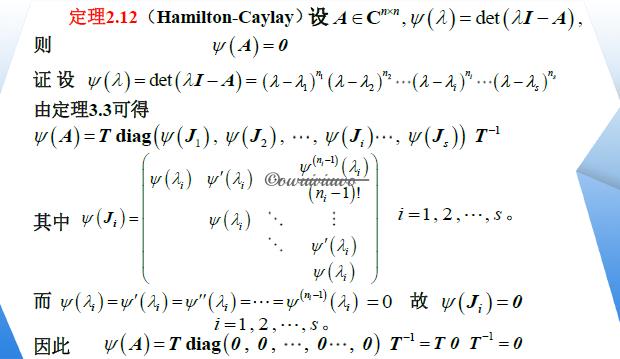
求 sinA,sinAt,其中


有限待定系数法
问题:给定函数 f(x),计算 f(Ax)
挑战:为避免计算矩阵的 Jordan 分解
\\(\\psi(\\lambda)\\) 为特征多项式,\\(q(\\lambda,t)\\) 为次数不超过 n-1 的含参多项式
有 Hamilton-Catley 定理可知 \\(\\psi(A)=0\\),从而
关键:确定含参系数 \\(b_n-1(t),\\cdots,b_1(t),b_0(t)\\)
显然,A 的特征多项式
故将 \\(f(\\lambda t)=p(\\lambda,t)\\psi(\\lambda)+q(\\lambda,t)\\) 两端对 \\(\\lambda\\) 求导,得到
n 个方程,n 个变量的线性方程组
待定系数法的步骤:
-
计算 A 的特征多项式 \\(\\psi(\\lambda)=\\det(A-\\lambda I)\\)
-
定义 \\(q(\\lambda,t)=b_n-1(t)\\lambda^n-1+\\cdots+b_1(t)\\lambda+b_0(t)\\)
利用(可假设 t=1)
\\[\\left . \\frac\\mathrmd^j\\mathrmd\\lambda^jf(\\lambda t)\\right|_\\lambda=\\lambda_i=\\left . \\frac\\mathrmd^j\\mathrmd\\lambda^jq(\\lambda,t)\\right|_\\lambda=\\lambda_i \\quad或\\quad \\left . t^j\\frac\\mathrmd^j\\mathrmdu^jf(u)\\right|_u=\\lambda_it=\\left . \\frac\\mathrmd^j\\mathrmd\\lambda^jq(\\lambda,t)\\right|_\\lambda=\\lambda_i \\]确定含参系数 \\(b_n-1(t),\\cdots,b_1(t),b_0(t)\\)
-
计算(假设 t=1,f(A)=q(A)) \\(f(At)=q(A,t)\\)
例题


矩阵函数等式
若 \\(\\forall A \\in C^n\\times n\\),总有:
- \\(\\sin(-A)=-\\sin A,\\cos(-A)=\\cos A\\)
- \\(e^iA=\\cos A+i\\sin A,\\, \\cos A=\\frac12(e^iA+e^-iA),\\,\\sin A=\\frac12i(e^iA-e^-iA)\\)
若 \\(A,B\\in C^n\\times n\\),且 AB=BA,则
- \\(e^Ae^B=e^Be^A=e^A+B\\)
- \\(\\sin(A+B)=\\sin A\\cos B+\\cos A\\sin B\\)
- \\(\\cos(A+B)=\\cos A\\cos B-\\sin A\\sin B\\)
若 A=B,则 \\(cos2A=\\cos^2A-\\sin^2A,\\,\\sin2A=2\\sin A\\cos A\\)
对任何 n 阶方阵 A,\\(e^A\\) 总是可逆矩阵
sinA 和 cosA 不一定可逆,例如:
其他若干结论:
- \\(f(A^T)=f(A)^T\\)
- \\(\\det(e^A)=e^trA\\)
- \\((e^A)^-1=e^-A\\)
- \\(||e^A||\\leq e^||A||\\)
- 若 A 为 Hermite 阵,则 \\(e^iA\\) 是酉阵
例题

3.3 矩阵的微积分
含参矩阵微分
元素为函数的矩阵微分:如果矩阵 \\(A(t)=(a_ij(t))_m\\times n\\) 的每一个元素 \\(a_ij(t),i=1,2,\\cdots,m;j=1,2,\\cdots,n\\),在[a,b] 上均为变量 t 的可微函数,则称 A(t) 可微,且导数定义为(也就是针对每个矩阵元素对 t 求导):
求导法则:
设 A(t), B(t) 是可进行运算的两个可微矩阵,则
- \\((A(t)+B(t))\'=A\'(t)+B\'(t)\\)
- \\((A(t)B(t))\'=A\'(t)B(t)+A(t)B\'(t)\\)
- \\((\\alpha A(t))\'=\\alpha\\cdot A\'(t)\\),其中 \\(\\alpha\\) 为任意常数
- 当 \\(A^-1(t)\\) 为可微矩阵时,有 \\((A^-1(t))\'=-A^-1(t)A\'(t)A^-1(t)\\)
- 当 \\(u=f(t)\\) 关于 t 可微时,有 \\((A(u))\'=f\'(t)\\fracdduA(u)\\)
函数矩阵的高阶导数定义为:
注:\\((A^m(t))\'=mA^m-1(t)(A(t))\'\\) 不一定成立, \\(A(t)(A(t))\'\\neq(A(t))\'A(t)\\), 事实上 \\((A^2(t))\'=(A(t)A(t))\'=A\'(t)A(t)+A(t)A\'(t)\\neq2A\'(t)A(t)\\)
特殊矩阵函数导数
设 n 阶方阵 A 与 t 无关,则有:
- \\((e^tA)\'=Ae^tA=e^tAA\\)
- \\((\\sin(tA))\'=A\\cdot\\cos(tA)=\\cos(tA)\\cdot A\\)
- \\((\\cos(tA))\'=-A\\cdot\\sin(tA)=-\\sin(tA)\\cdot A\\)
重要的例题
可利用特殊点的导数值求相应矩阵

例题
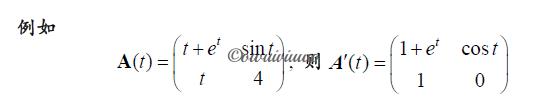

矩阵函数积分
如果矩阵 \\(A(t)=(a_ij(t))_m\\times n\\) 的每一个元素 \\(a_ij(t)\\) 都是区间 \\([t_0,t_1]\\) 上的可积函数,则定义 A(t) 在区间 \\([t_0,t_1]\\) 上的积分为(对矩阵积分也就是对矩阵中每个元素积分):
性质(与函数的积分类似)
-
\\(\\int^t_1_t_0(\\alpha A(t)+\\beta B(t))dt=\\alpha\\int^t_1_t_0A(t)dt+\\beta\\int^t_1_t_0 B(t))dt,\\;\\forall\\alpha,\\beta\\in C\\)
-
\\(\\int^t_1_t_0(A(t)B)dt=\\int^t_1_t_0A(t)dtB\\) 其中 B 为常数矩阵
\\(\\int^t_1_t_0(AB(t))dt=A\\int^t_1_t_0B(t)dt\\) 其中 A 为常数矩阵
-
当 A(t) 在 [a,b] 上连续可微时,对任意 \\(t\\in(a,b)\\) ,有 \\(\\fracddt(\\int^t_aA(\\tau)d\\tau)=A(t)\\)
-
当 A(t) 在 [a,b] 上连续可微时,对任意 \\(t\\in(a,b)\\) ,有 \\(\\int^b_a\\fracdA(t)dtdt=A(b)-A(a)\\)
* 相对于矩阵变量的微分
应该不会考
python与数据分析Numpy数值计算基础——补充
目录
二、矩阵生成与常用操作
1.生成矩阵
>>> import numpy as np >>> x=np.matrix([[1,2,3],[4,5,6]]) >>> y=np.matrix([1,2,3,4,5,6]) >>> print(x) [[1 2 3] [4 5 6]] >>> print(y) [[1 2 3 4 5 6]] >>> x[1] #注意,对矩阵来说,X[1,1]和X[1][1]的含义不一样,后者异常 matrix([[4, 5, 6]]) >>> x[1,1] #X[1,1]返回行下标和列下标都为1的元素 5 >>> y[0] matrix([[1, 2, 3, 4, 5, 6]]) >>> y[0,1] 22.矩阵转置
>>> x matrix([[1, 2, 3], [4, 5, 6]]) >>> y matrix([[1, 2, 3, 4, 5, 6]]) >>> print(x.T,y.T,sep='\\n\\n') [[1 4] [2 5] [3 6]] [[1] [2] [3] [4] [5] [6]] >>> x.T matrix([[1, 4], [2, 5], [3, 6]])3.查看矩阵特征
>>> x=np.matrix([[1,2,3],[4,5,6]]) >>> print(x.mean(),end='\\n====\\n') #所有元素平均值 3.5 ==== >>> print(x.mean(axis=0),end='\\n===\\n') #纵向平均值 [[2.5 3.5 4.5]] === >>> print(x.mean(axis=0).shape,end='\\n====\\n') (1, 3) ==== >>> print(x.mean(axis=1),end='\\n====\\n') #横向平均值 [[2.] [5.]] ==== >>> print(x.sum(),end='\\n====\\n') #所有元素之和 21 ==== >>> print(x.max(axis=1)) #横向最大值 [[3] [6]] >>> print(x.argmax(axis=1)) #横向最大值的下标 [[2] [2]] >>> print(x.max(axis=0),end='\\n====\\n') #纵向最大值 [[4 5 6]] ==== >>> print(x.diagonal(),end='\\n====\\n') #对角线元素 [[1 5]] ==== >>> print(x.nonzero()) #非零元素下标,分别返回行下标和列下标 (array([0, 0, 0, 1, 1, 1], dtype=int64), array([0, 1, 2, 0, 1, 2], dtype=int64))4.矩阵乘法
>>> A=np.matrix([[1,2,3],[4,5,6]]) >>> print(A) [[1 2 3] [4 5 6]] >>> B=np.matrix([[1,2],[3,4],[5,6]]) >>> print(B) [[1 2] [3 4] [5 6]] >>> C=A*B >>> print(C) [[22 28] [49 64]] >>> A.shape,B.shape,C.shape ((2, 3), (3, 2), (2, 2))5.计算相关系数矩阵
- 相关系数矩阵是一个对称矩阵,其中对角线上的元素都是1,表示自相关系数
- 非对角线元素表示互相关系数,每个元素的绝对值都小于等于1,反应变量变化趋势的相似程度
- 例如,如果相关系数矩阵中非对角线元素大于0,表示两个信号正相关,其中一个信号变大时另一个信号也变大,变化方向一致,或者说一个信号的变化对另一个信号的影响是正面或者积极的
- 相关系数的绝对值越大,表示两个信号互相影响的程度越大
>>> print(np.corrcoef([1,2,3,4],[4,3,2,1])) #负相关,变化方向相反 [[ 1. -1.] [-1. 1.]] >>> print(np.corrcoef([1,2,3,4],[8,3,2,1])) #负相关,变化方向相反 [[ 1. -0.91350028] [-0.91350028 1. ]] >>> print(np.corrcoef([1,2,3,4],[1,2,3,4])) #正相关,变化方向一致 [[1. 1.] [1. 1.]] >>> print(np.corrcoef([1,2,3,4],[1,2,3,40])) #正相关,变化趋势接近 [[1. 0.8010362] [0.8010362 1. ]]6.计算方差、协方差、标准差
>>> print(np.cov([1,1,1,1,1])) #方差(自身协方差) 0.0 >>> print(np.std([1,1,1,1,1])) #标准差 0.0 >>> print(np.cov([1,2,1,4,1])) 1.7000000000000002 >>> print(np.std([1,2,1,4,1])) 1.1661903789690602 >>> x=[-2.1,-1,4.3] >>> y=[3,1.1,0.12] >>> X=np.vstack((x,y)) #垂直堆叠矩阵 >>> print(X) [[-2.1 -1. 4.3 ] [ 3. 1.1 0.12]] >>> print(np.cov(X)) #协方差 [[11.71 -4.286 ] [-4.286 2.14413333]] >>> print(np.cov(x,y)) [[11.71 -4.286 ] [-4.286 2.14413333]] >>> print(np.cov(x)) 11.709999999999999 >>> print(np.cov(y)) 2.1441333333333334 >>> print(np.std(x)) #标准差 2.794041278626117 >>> print(np.std(x+y)) #同x标准差 2.2071223094538484 >>> print(np.std(X,axis=1)) #横向标准差,相当于x,y标准差 [2.79404128 1.19558447] >>> print(np.std(x)) #x标准差方差 2.794041278626117 >>> print(np.std(X,axis=0)) [2.55 1.05 2.09]7.行列扩展
>>>data=np.matrix([np.random.randint(1,10,5) for _ in range(6)]) >>>newcols=np.matrix([np.random.randint(1,10,2) for _ in range(6)]) >>>newrows=np.matrix([np.random.randint(1,10,5) for _ in range(3)]) >>>data matrix([[4, 5, 8, 1, 1], [1, 5, 2, 1, 5], [5, 1, 2, 1, 9], [6, 1, 6, 6, 7], [1, 1, 5, 9, 1], [8, 8, 6, 2, 4]]) >>>newcols matrix([[4, 2], [7, 3], [6, 1], [1, 1], [3, 8], [8, 9]]) >>>newrows matrix([[4, 1, 3, 5, 7], [9, 3, 9, 8, 9], [8, 7, 5, 8, 5]]) >>>np.c_[data,newcols] #在data的右侧(列)加入newcols matrix([[4, 5, 8, 1, 1, 4, 2], [1, 5, 2, 1, 5, 7, 3], [5, 1, 2, 1, 9, 6, 1], [6, 1, 6, 6, 7, 1, 1], [1, 1, 5, 9, 1, 3, 8], [8, 8, 6, 2, 4, 8, 9]]) >>>np.c_[newcols,data] #在data左侧(列)加入newcols matrix([[4, 2, 4, 5, 8, 1, 1], [7, 3, 1, 5, 2, 1, 5], [6, 1, 5, 1, 2, 1, 9], [1, 1, 6, 1, 6, 6, 7], [3, 8, 1, 1, 5, 9, 1], [8, 9, 8, 8, 6, 2, 4]]) >>>np.r_[data,newrows] #在data的下面(行)加入newrows matrix([[4, 5, 8, 1, 1], [1, 5, 2, 1, 5], [5, 1, 2, 1, 9], [6, 1, 6, 6, 7], [1, 1, 5, 9, 1], [8, 8, 6, 2, 4], [4, 1, 3, 5, 7], [9, 3, 9, 8, 9], [8, 7, 5, 8, 5]]) >>>np.r_[newrows,data] #在data的上面(行)加入newrows matrix([[4, 1, 3, 5, 7], [9, 3, 9, 8, 9], [8, 7, 5, 8, 5], [4, 5, 8, 1, 1], [1, 5, 2, 1, 5], [5, 1, 2, 1, 9], [6, 1, 6, 6, 7], [1, 1, 5, 9, 1], [8, 8, 6, 2, 4]]) >>>np.r_[data,newrows,newrows] matrix([[4, 5, 8, 1, 1], [1, 5, 2, 1, 5], [5, 1, 2, 1, 9], [6, 1, 6, 6, 7], [1, 1, 5, 9, 1], [8, 8, 6, 2, 4], [4, 1, 3, 5, 7], [9, 3, 9, 8, 9], [8, 7, 5, 8, 5], [4, 1, 3, 5, 7], [9, 3, 9, 8, 9], [8, 7, 5, 8, 5]]) >>> np.insert(data,0,newrows,axis=0) #在data的第0行插入newrows matrix([[4, 1, 3, 5, 7], [9, 3, 9, 8, 9], [8, 7, 5, 8, 5], [4, 5, 8, 1, 1], [1, 5, 2, 1, 5], [5, 1, 2, 1, 9], [6, 1, 6, 6, 7], [1, 1, 5, 9, 1], [8, 8, 6, 2, 4]]) >>> np.insert(data,3,newrows,axis=0) #在data的第三行插入newrows matrix([[4, 5, 8, 1, 1], [1, 5, 2, 1, 5], [5, 1, 2, 1, 9], [4, 1, 3, 5, 7], [9, 3, 9, 8, 9], [8, 7, 5, 8, 5], [6, 1, 6, 6, 7], [1, 1, 5, 9, 1], [8, 8, 6, 2, 4]]) >>> np.insert(data,4,newcols.T,axis=1) #在data的第四列插入newcols matrix([[4, 5, 8, 1, 4, 2, 1], [1, 5, 2, 1, 7, 3, 5], [5, 1, 2, 1, 6, 1, 9], [6, 1, 6, 6, 1, 1, 7], [1, 1, 5, 9, 3, 8, 1], [8, 8, 6, 2, 8, 9, 4]]) >>> np.insert(data,1,newcols.T,axis=1) #在data的第一列插入newcols matrix([[4, 4, 2, 5, 8, 1, 1], [1, 7, 3, 5, 2, 1, 5], [5, 6, 1, 1, 2, 1, 9], [6, 1, 1, 1, 6, 6, 7], [1, 3, 8, 1, 5, 9, 1], [8, 8, 9, 8, 6, 2, 4]]) >>> np.row_stack((data,newrows)) #垂直(行)堆叠矩阵,与np.vstack((data,newrows)) matrix([[4, 5, 8, 1, 1], [1, 5, 2, 1, 5], [5, 1, 2, 1, 9], [6, 1, 6, 6, 7], [1, 1, 5, 9, 1], [8, 8, 6, 2, 4], [4, 1, 3, 5, 7], [9, 3, 9, 8, 9], [8, 7, 5, 8, 5]]) >>> np.column_stack((data,newcols)) #横着(列)堆叠矩阵 matrix([[4, 5, 8, 1, 1, 4, 2], [1, 5, 2, 1, 5, 7, 3], [5, 1, 2, 1, 9, 6, 1], [6, 1, 6, 6, 7, 1, 1], [1, 1, 5, 9, 1, 3, 8], [8, 8, 6, 2, 4, 8, 9]])8.常用变量
>>> np.Inf #正无穷大 inf >>> np.NAN #非数字 nan >>> np.Infinity inf >>> np.MAXDIMS 32 >>> np.NINF #负无穷大 -inf >>> np.NaN nan >>> np.NZERO #负0 -0.09.矩阵在不同维度上的计算
>>> x=np.matrix(np.arange(0,10).reshape(2,5)) #二维矩阵 >>> x matrix([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]) >>> x.sum() #所有元素之和 45 >>> x.sum(axis=0) #纵向求和 matrix([[ 5, 7, 9, 11, 13]]) >>> x.sum(axis=1) #横向求和 matrix([[10], [35]]) >>> x.mean() #平均值 4.5 >>> x.mean(axis=1) matrix([[2.], [7.]]) >>> x.mean(axis=0) matrix([[2.5, 3.5, 4.5, 5.5, 6.5]]) >>> weight=[0.3,0.7] #权重 >>> np.average(x,axis=0,weights=weight) matrix([[3.5, 4.5, 5.5, 6.5, 7.5]]) >>> x.max() #所有元素最大值 9 >>> x.max(axis=0) #纵向最大值 matrix([[5, 6, 7, 8, 9]]) >>> x.max(axis=1) #横向最大值 matrix([[4], [9]]) >>> x=np.matrix(np.random.randint(0,10,size=(3,3))) >>> x matrix([[3, 7, 7], [7, 0, 9], [4, 0, 8]]) >>> x.std() #标准差 3.197221015541813 >>> x.std(axis=1) #横向标准差 matrix([[1.88561808], [3.8586123 ], [3.26598632]]) >>> x.std(axis=0) #纵向标准差 matrix([[1.69967317, 3.29983165, 0.81649658]]) >>> x.var(axis=0) #纵向方差 matrix([[ 2.88888889, 10.88888889, 0.66666667]]) >>> x.sort(axis=0) #纵向排序 >>> x matrix([[3, 0, 7], [4, 0, 8], [7, 7, 9]]) >>> x.sort(axis=1) #横向排序 >>> x matrix([[0, 3, 7], [0, 4, 8], [7, 7, 9]])10.应用
(1)使用蒙特·卡罗方法估计圆周率的值
>>> def numpyPI(times): ... x=np.random.rand(times) ... y=np.random.rand(times) ... hits=np.sum(x**2+y**2<=1) ... pi=hits/times*4 ... return pi ... >>> numpyPI(1000000) 3.143172(2)复利计算公式
>>> import numpy_financial as npf >>> round(npf.fv(0.05,39,-14000,-14000))#每年固定存入14000元,年利率固定为5%,40年后的余额 1691197三、计算特征值与正特征向量
- 对于n*n方阵A,如果存在标量λ和n维非0向量x,使得
成立,哪个称λ是方阵A的一个特征值,x为对应λ的特征向量
- 从几何意义来讲,矩阵乘以一个向量,是对这个向量进行了一个变换,从一个坐标系变换到另一个坐标系。在变换过程中,向量主要发生旋转和缩放这两种变化。如果矩阵乘以一个向量之后,向量只发生了缩放变化而没有进行旋转,那么这个向量就是该矩阵的特征向量,缩放的比例就是特征值。或者说,特征向量是对数据进行旋转之后理想的坐标轴之一,而特征值则是该坐标轴上的投影或者贡献。特征值越大,表示这个坐标轴对原向量的表达越重要,原向量在这个个坐标轴上的投影越大。一个矩阵的所有特征向量组成了该矩阵的一组基,也就是新坐标中的轴。有个特征值和特征向量之后,向量就可以在另一个坐标系中进行表示。
>>> A=np.array([[1,-3,3],[3,-5,3],[6,-6,4]]) >>> print(A) [[ 1 -3 3] [ 3 -5 3] [ 6 -6 4]] >>> e,v=np.linalg.eig(A) #特征值与特征向量 >>> print(e) [ 4.+0.00000000e+00j -2.+1.10465796e-15j -2.-1.10465796e-15j] >>> print(v) [[-0.40824829+0.j 0.24400118-0.40702229j 0.24400118+0.40702229j] [-0.40824829+0.j -0.41621909-0.40702229j -0.41621909+0.40702229j] [-0.81649658+0.j -0.66022027+0.j -0.66022027-0.j ]] >>> print(np.linalg.eig) <function eig at 0x0000027435CD67A0> >>> print(np.linalg.eigvals(A)) [ 4.+0.00000000e+00j -2.+1.10465796e-15j -2.-1.10465796e-15j] >>> print(e*v) #特征值与特征向量的乘积 [[-1.63299316+0.00000000e+00j -0.48800237+8.14044580e-01j -0.48800237-8.14044580e-01j] [-1.63299316+0.00000000e+00j 0.83243817+8.14044580e-01j 0.83243817-8.14044580e-01j] [-3.26598632+0.00000000e+00j 1.32044054-7.29317578e-16j 1.32044054+7.29317578e-16j]] >>> print(np.isclose(np.dot(A,v),e*v)) #检验二者是否相等 [[ True True True] [ True True True] [ True True True]] >>> print(np.linalg.det(A-np.eye(3,3)*e)) #行列式|A-λE|的值应为0 5.965152994198125e-14j四、计算逆矩阵
>>> x=np.matrix([[1,2,3],[4,5,6],[7,8,0]]) >>> y=np.linalg.inv(x) #计算x逆矩阵 >>> print(y) [[-1.77777778 0.88888889 -0.11111111] [ 1.55555556 -0.77777778 0.22222222] [-0.11111111 0.22222222 -0.11111111]] >>> print(x*y) #对角元素为1,其他元素为0或者近似为0 [[ 1.00000000e+00 5.55111512e-17 1.38777878e-17] [ 5.55111512e-17 1.00000000e+00 2.77555756e-17] [ 1.77635684e-15 -8.88178420e-16 1.00000000e+00]] >>> print(np.round(y*x)) [[ 1. -0. 0.] [ 0. 1. 0.] [ 0. 0. 1.]]五、求解线性方程组
- 线性方程组
>>> a=np.array([[3,1],[1,2]]) #系数矩阵 >>> b=np.array([9,8]) >>> x=np.linalg.solve(a,b) #求解 >>> print(x) [2. 3.] >>> print(np.dot(a,x)) #验证 [9. 8.] >>> print(np.linalg.lstsq(a,b)) #最小二乘解(返回解、余项、a的秩、a的奇异值) Warning (from warnings module): File "<pyshell#81>", line 1 FutureWarning: `rcond` parameter will change to the default of machine precision times ``max(M, N)`` where M and N are the input matrix dimensions. To use the future default and silence this warning we advise to pass `rcond=None`, to keep using the old, explicitly pass `rcond=-1`. (array([2., 3.]), array([], dtype=float64), 2, array([3.61803399, 1.38196601])) >>> print(np.linalg.matrix_rank(a)) #a的秩 2 >>> U,sv,V=np.linalg.svd(a,full_matrices=False) #奇异值分解 >>> print(sv) #a的奇异值 [3.61803399 1.38196601] >>> print(U) [[-0.85065081 -0.52573111] [-0.52573111 0.85065081]] >>> print(V) [[-0.85065081 -0.52573111] [-0.52573111 0.85065081]]六、计算向量和矩阵的范数
>>> x=np.matrix([[1,2],[3,-4]]) >>> np.linalg.norm(x) #F范数=(1**2+2**2+3**2+(-4)**2)**0.5 5.477225575051661 >>> np.linalg.norm(x,-2) #smallest singular value 1.9543950758485487 >>> np.linalg.norm(x,-1) #min(sum(abs(x),axis=0)) 4.0 >>> np.linalg.norm(x,1) #max(sum(abs(x),axis=0)) 6.0 >>> np.linalg.norm(np.array([1,2,3,4]),3) 4.641588833612778七、计算矩阵的幂,矩阵自乘
>>> np.linalg.matrix_power([[1,2],[3,4]],2) #自乘2次 array([[ 7, 10], [15, 22]]) >>> np.linalg.matrix_power([[1,2],[3,4]],5) #自乘5次 array([[1069, 1558], [2337, 3406]]) >>> x=np.matrix([[1,2],[3,4]]) >>> x**2 #也可以直接使用运算符** matrix([[ 7, 10], [15, 22]]) >>> x**5 matrix([[1069, 1558], [2337, 3406]])八、矩阵奇异值分解
- 其中,A,U都是正交阵,Σ是对角阵
>>> a=np.arange(60).reshape(5,-1) >>> a array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35], [36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47], [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59]]) >>> U,s,V=np.linalg.svd(a,full_matrices=False) >>> np.dot(U,np.dot(np.diag(s),V)) array([[2.32096525e-15, 1.00000000e+00, 2.00000000e+00, 3.00000000e+00, 4.00000000e+00, 5.00000000e+00, 6.00000000e+00, 7.00000000e+00, 8.00000000e+00, 9.00000000e+00, 1.00000000e+01, 1.10000000e+01], [1.20000000e+01, 1.30000000e+01, 1.40000000e+01, 1.50000000e+01, 1.60000000e+01, 1.70000000e+01, 1.80000000e+01, 1.90000000e+01, 2.00000000e+01, 2.10000000e+01, 2.20000000e+01, 2.30000000e+01], [2.40000000e+01, 2.50000000e+01, 2.60000000e+01, 2.70000000e+01, 2.80000000e+01, 2.90000000e+01, 3.00000000e+01, 3.10000000e+01, 3.20000000e+01, 3.30000000e+01, 3.40000000e+01, 3.50000000e+01], [3.60000000e+01, 3.70000000e+01, 3.80000000e+01, 3.90000000e+01, 4.00000000e+01, 4.10000000e+01, 4.20000000e+01, 4.30000000e+01, 4.40000000e+01, 4.50000000e+01, 4.60000000e+01, 4.70000000e+01], [4.80000000e+01, 4.90000000e+01, 5.00000000e+01, 5.10000000e+01, 5.20000000e+01, 5.30000000e+01, 5.40000000e+01, 5.50000000e+01, 5.60000000e+01, 5.70000000e+01, 5.80000000e+01, 5.90000000e+01]]) >>> np.allclose(a,np.dot(U,np.dot(np.diag(s),V))) True九、计算数组或矩阵的行列式
>>> a=[[1,2],[3,4]] >>> np.linalg.det(a) -2.0000000000000004 >>> a=np.array([[[1,2],[3,4]],[[1,2],[2,1]],[[1,3],[3,1]]]) >>> np.linalg.det(a) array([-2., -3., -8.])十、矩阵QR分解
- 如果实(复)非奇异矩阵A能够化成正交(酉)矩阵Q与实(复)非奇异上三角矩阵R的乘积,即A=QR,则称其为A的QR分解
>>> a=np.matrix([[1,2,3],[4,5,6]]) >>> q,r=np.linalg.qr(a) >>> print(q,r,sep='\\n\\n') [[-0.24253563 -0.9701425 ] [-0.9701425 0.24253563]] [[-4.12310563 -5.33578375 -6.54846188] [ 0. -0.72760688 -1.45521375]] >>> np.dot(1,r) matrix([[-4.12310563, -5.33578375, -6.54846188], [ 0. , -0.72760688, -1.45521375]])十一、读写文件
numpy文件读写主要有二进制的文件读写和文件列表形式的数据读写两种形式
- save函数是以二进制的格式保存数据。
np.save("../tmp/save_arr",arr)
- load函数是从二进制的文件中读取数据
np.load("../tmp/save_arr.npy")
- savez函数可以将多个数组保存到一个文件中
np.savez('../tmp/savez_arr',arr1,arr2)
- 存储时可以省略扩展名,但读取时不能省略扩展名
读取文本格式的数据
- savetxt函数是将数组写到某种分隔符隔开的文本文件中
np.savetxt("../tmp/arr.txt",arr,fmt="%d",delimiter=",")
- loadtxt函数执行的是把文件加载到一个二维数组中
np.loadtxt("../tmp/arr.txt",delimiter=",")
- genfromtxt函数面向的是结构化数组和缺失数据
np.genfromtxt("../tmp/arr.txt",delimiter=",")
>>> x=np.random.rand(4,10) >>> np.save('data.npy',x) >>> y=np.load('data.npy') >>> y array([[0.41902235, 0.69427069, 0.37598648, 0.73763434, 0.37021849, 0.22994088, 0.89334764, 0.04995869, 0.18538797, 0.84465261], [0.97907058, 0.27427357, 0.11774563, 0.90859496, 0.86412135, 0.643867 , 0.09459659, 0.1766268 , 0.2050061 , 0.82050625], [0.89201862, 0.64940355, 0.50761076, 0.79521352, 0.52232466, 0.85287866, 0.91648536, 0.75976614, 0.2113207 , 0.07295113], [0.41439073, 0.07900488, 0.52060863, 0.92372387, 0.88509664, 0.50123086, 0.8048252 , 0.38571732, 0.01780673, 0.87969947]]) >>> x=np.matrix([[1,2,3],[4,5,6]]) >>> x matrix([[1, 2, 3], [4, 5, 6]]) >>> np.savetxt('x.txt',x) >>> np.loadtxt('x.txt') array([[1., 2., 3.], [4., 5., 6.]]) >>> with open('x.txt') as fp: ... print(fp.read()) ... ... 1.000000000000000000e+00 2.000000000000000000e+00 3.000000000000000000e+00 4.000000000000000000e+00 5.000000000000000000e+00 6.000000000000000000e+00 >>> a_mat=np.matrix([3,5,7]) >>> a_mat.tostring() Warning (from warnings module): File "<pyshell#126>", line 1 DeprecationWarning: tostring() is deprecated. Use tobytes() instead. b'\\x03\\x00\\x00\\x00\\x05\\x00\\x00\\x00\\x07\\x00\\x00\\x00' >>> a_mat.dumps() #dumps()方法用于将数据进行序列化 b'\\x80\\x02cnumpy.core.multiarray\\n_reconstruct\\nq\\x00cnumpy\\nmatrix\\nq\\x01K\\x00\\x85q\\x02c_codecs\\nencode\\nq\\x03X\\x01\\x00\\x00\\x00bq\\x04X\\x06\\x00\\x00\\x00latin1q\\x05\\x86q\\x06Rq\\x07\\x87q\\x08Rq\\t(K\\x01K\\x01K\\x03\\x86q\\ncnumpy\\ndtype\\nq\\x0bX\\x02\\x00\\x00\\x00i4q\\x0c\\x89\\x88\\x87q\\rRq\\x0e(K\\x03X\\x01\\x00\\x00\\x00<q\\x0fNNNJ\\xff\\xff\\xff\\xffJ\\xff\\xff\\xff\\xffK\\x00tq\\x10b\\x89h\\x03X\\x0c\\x00\\x00\\x00\\x03\\x00\\x00\\x00\\x05\\x00\\x00\\x00\\x07\\x00\\x00\\x00q\\x11h\\x05\\x86q\\x12Rq\\x13tq\\x14b.' >>> np.loads(_) #loads()方法用于反序列化,还原为原来的信息 Traceback (most recent call last): File "<pyshell#128>", line 1, in <module> np.loads(_) File "E:\\python 3.7\\lib\\site-packages\\numpy\\__init__.py", line 311, in __getattr__ raise AttributeError("module !r has no attribute " AttributeError: module 'numpy' has no attribute 'loads'. Did you mean: 'load'? >>> a_mat.dump('x.dat') >>> np.load('x.dat') Traceback (most recent call last): File "<pyshell#133>", line 1, in <module> np.load('x.dat') File "E:\\python 3.7\\lib\\site-packages\\numpy\\lib\\npyio.py", line 418, in load raise ValueError("Cannot load file containing pickled data " ValueError: Cannot load file containing pickled data when allow_pickle=False
以上是关于2022-2023 春学期 矩阵与数值分析 C3 矩阵分析基础的主要内容,如果未能解决你的问题,请参考以下文章