python爬虫之Requests库
Posted 唯你如我心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫之Requests库相关的知识,希望对你有一定的参考价值。
requests功能展示 :
import requests response = requests.get("https://www.baidu.com") print(type(response)) print(response.status_code) print(type(response.text)) print(response.text) print(response.cookies) print(response.content) print(response.content.decode("utf-8"))
很多情况下的网站直接使用response.text可能会出现乱码的问题, 所以就需要使用response.content, 此方法返回的数据格式其实是二进制格式,然后通过decode()转换为utf-8, 这样就解决了通过response.text直接返回显示乱码的问题
请求发出后, requests会基于HTTP头部响应的编码做出有根据的推测. 当你访问response.text之时, requests会使用其推测的文本编码. 你可以找出requests使用了什么编码, 并且能够使用response.encoding属性来改变它,
response =requests.get("http://www.baidu.com") response.encoding="utf-8" print(response.text)
不管是通过response.content.decode("utf-8")的方式还是通过resposne.encoding="utf-8"的方式都可以避免乱码问题的发生.
各种请求方式 :
requests里提供各种请求方式:
import requests requests.post("http://httpbin.org/post") requests.put("http://httpbin.org/put") requests.delete("http://httpbin.org/delete") requests.head("http://httpbin.org/get") requests.options("http://httpbin.org/get")
基本get请求:
import requests response = requests.get(\'http://httpbin.org/get\') print(response.text)
带参数的get请求:
import requests response = requests.get("http://httpbin.org/get?name=xxx&age=18") print(response.text)
如果想要在url查询字符串传递数据, 通常会通过key=value的方式传递. requests模块允许使用params关键字传递参数, 以一个字典来传递这些参数, 举个栗子:
import requests data = { "name":"xxx", "age":18 } response = requests.get("http://httpbin.org/get",params=data) print(response.url) print(response.text)
上述两种的结果是相同的, 通过params参数传递一个字典内容, 从而直接构造url
但是第二种方式通过字典的方式传递参数时, 如果字典中的参数为None则不会添加到url上.
基本POST请求:
通过发送post请求时添加一个data参数, 这个data参数可以通过字典构造出来
这样对于发送post请求就非常方便
import requests data = { "name":"xxx", "age":18 } response = requests.post("http://httpbin.org/post",data=data) print(response.text)
同样在发送post请求的时候也可以和发送get请求一样通过headers参数传递一个字典的数据
解析json :
import requests import json response = requests.get("http://httpbin.org/get") print(type(response.text)) print(response.json()) print(json.loads(response.text)) print(type(response.json()))
可以看出requests里面集成的json其实就是执行了json.loads()方法, 两者的结果是一样的
获取二进制数据 :
使用response.content获取的数据就是二进制数据, 同样的这个方法也可以用于下载图片以及视频资源.
添加headers :
requests请求时可以定制headers的信息的, 当我们直接通过requests请求知乎网站的时候, 默认是无法访问的, 因为大多数网站都具有反爬机制, 所以我们需要在requests之前添加headers头部信息.
import requests headers = { "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" } response =requests.get("https://www.zhihu.com",headers=headers) print(response.text)
这样就可以正常访问知乎了
requests高级用法
文件上传 :
实现方法和其他参数类似, 也是构造一个字典然后files参数传递
import requests files= {"files":open("git.jpeg","rb")} response = requests.post("http://httpbin.org/post",files=files) print(response.text)
获取cookie :
import requests response = requests.get("http://www.baidu.com") print(response.cookies) for key,value in response.cookies.items(): print(key+"="+value)
会话维持 :
cookie的一个作用就是可以用于模拟登录, 做会话维持
import requests s = requests.Session() s.get("http://httpbin.org/cookies/set/number/123456") response = s.get("http://httpbin.org/cookies") print(response.text)
而下面写法则是错误的:
import requests requests.get("http://httpbin.org/cookies/set/number/123456") response = requests.get("http://httpbin.org/cookies") print(response.text)
因为这种方式是两次请求之间都是独立的, 而第一次则是通过创建一个session对象, 两次请求都是通过这个对象访问的
证书验证 :
现在的很多网站都是https的方式访问, 所以这个时候就设计到证书的问题
import requests response = requests.get("https:/www.12306.cn") print(response.status_code)
默认的12306网站的证书是不合法的, 这样就会提示如下错误:
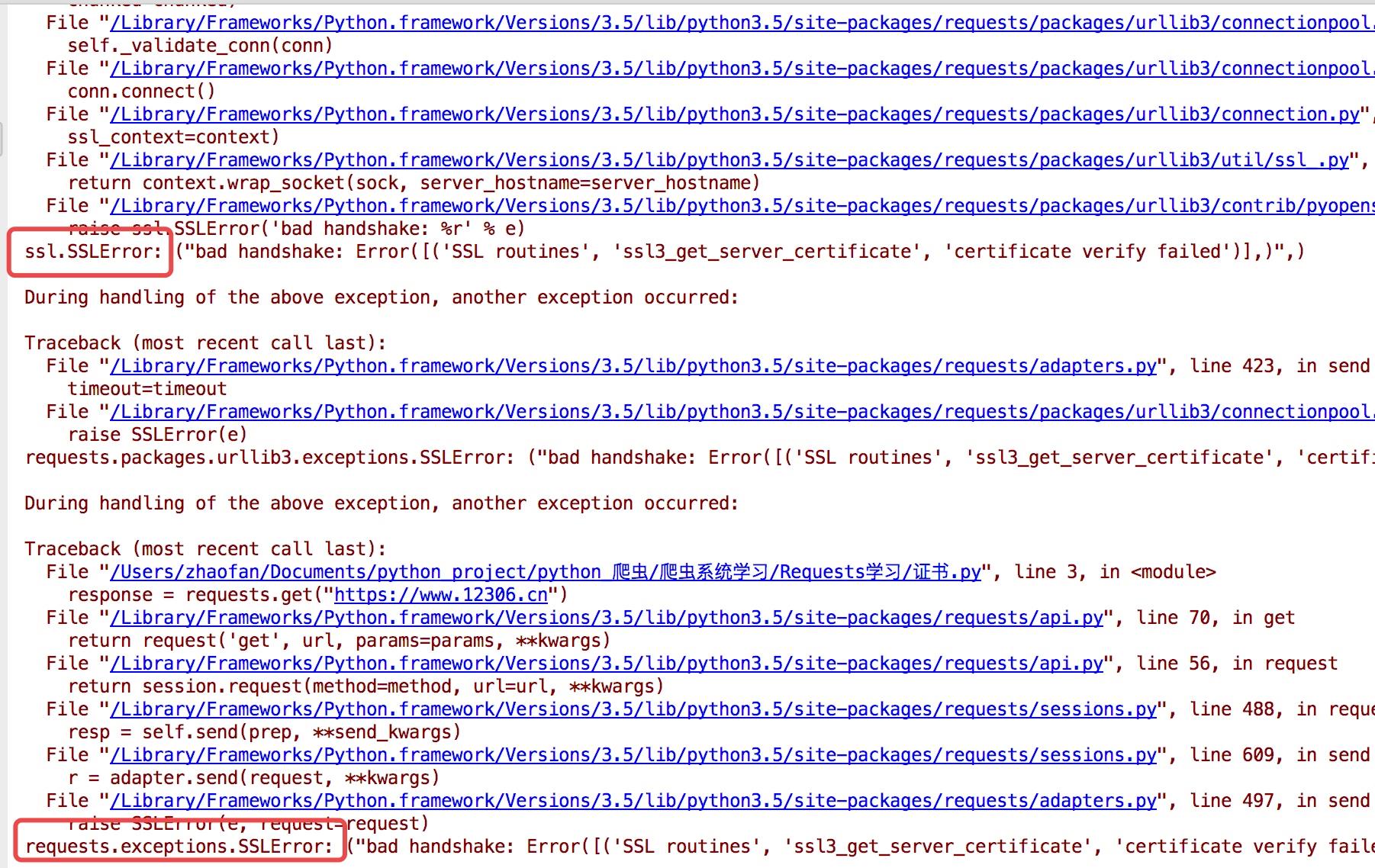
为了避免这种情况的发生可以通过verify=False
这样是可以访问到页面的, 但是会提示:
InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning)
解决方法为:
import requests from requests.packages import urllib3 urllib3.disable_warnings() response = requests.get("https://www.12306.cn",verify=False) print(response.status_code)
这样就不会提示警告信息, 当然也可以通过cert参数放入证书路径.
代理设置 :
import requests proxies= { "http":"http://127.0.0.1:9999", "https":"http://127.0.0.1:8888" } response = requests.get("https://www.baidu.com",proxies=proxies) print(response.text)
如果代理需要设置账户名和密码, 只需要将会字典更改为如下 :
proxies = {
"http": "http://user:password@127.0.0.1:9999"
}
如果你的代理是通过sokces这种方式需要pip install "requests[socks]"
proxies = {
"http": "socks5://127.0.0.1:9999",
"https": "sockes5://127.0.0.1:8888"
}
超时设置 :
通过timeout参数可以设置超时的时间
认证设置 :
如果碰到需要认证网站可以通过requests.auth模块实现
import requests from requests.auth import HTTPBasicAuth response = requests.get("http://120.27.34.24:9001/",auth=HTTPBasicAuth("user","123")) print(response.status_code)
当然还有一种方式
import requests response = requests.get("http://120.27.34.24:9001/",auth=("user","123")) print(response.status_code)
以上是关于python爬虫之Requests库的主要内容,如果未能解决你的问题,请参考以下文章