实验4 函数与异常处理编程
Posted ciallo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验4 函数与异常处理编程相关的知识,希望对你有一定的参考价值。
1.实验任务1
print(sum) sum = 42 print(sum) def inc(n): sum = n + 1 print(sum) return sum sum = inc(7) + inc(7) print(sum)
问题:不是。line1中的sum是指Python的内置函数;line3中的sum指的是line2中的全局变量sum;line7中的sum指的是inc函数中的局部变量;line11中的sum指的是line10的全局变量
2.实验任务2
task1
def func1(a, b, c, d, e, f): \'\'\' 返回参数a,b,c,d,e,f构成的列表 默认,参数按位置传递; 也支持关键字传递 \'\'\' return [a,b,c,d,e,f] def func2(a, b, c,*, d, e, f): \'\'\' 返回参数a,b,c,d,e,f构成的列表 *后面的参数只能按关键字传递 \'\'\' return [a,b,c,d,e,f] def func3(a, b, c, /, d, e, f): \'\'\' 返回参数a,b,c,d,e,f构成的列表 /前面的参数只能按位置传递 \'\'\' return [a,b,c,d,e,f] # func1调用:按位置传递、按参数传递都可以 print( func1(1,9,2,0,5,3) ) print( func1(a=1, b=9, c=2, d=0, e=5, f=3) ) print( func1(1,9,2, f=3, d=0, e=5)) # func2调用:d,e,f必须按关键字传递 print( func2(11, 99, 22, d=0, e=55, f=33) ) print( func2(a=11, b=99, c=22, d=0, e=55, f=33) ) # func3调用:a,b,c必须按位置传递 print( func3(111, 999, 222, 0, 555, 333)) print( func3(111, 999, 222, d=0, e=555, f=333) )
运行结果如图:

增加print( func2(11, 99, 22, 0, 55, 33))后:

增加print(func3(a=111, b=999, c=222, 0, 555, 333))后:
task2_2
list1 = [1, 9, 8, 4] print( sorted(list1) ) print( sorted(list1, reverse=True) ) print( sorted(list1, True) )
运行结果如图:

task2_2所示情况中,必须使用关键字传递reversse
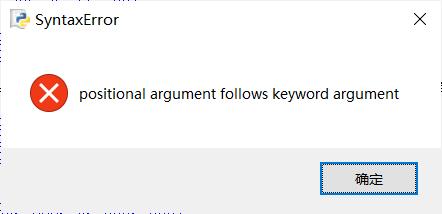
task2_3
def func(a, b, c, /, *, d, e, f): return( [a,b,c,d,e,f] ) print(func(1,2,3,d = 4,e = 5,f = 6))
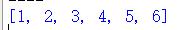
3.实验任务3
def solve(a, b, c): \'\'\' 求解一元二次方程, 返回方程的两个根 :para: a,b,c: float 方程系数 :return: tuple \'\'\' delta = b*b - 4*a*c delta_sqrt = abs(delta)**0.5 p1 = -b/2/a p2 = delta_sqrt/2/a if delta >= 0: root1 = p1 + p2 root2 = p1 - p2 else: root1 = complex(p1, p2) root2 = complex(p1, -p2) return root1, root2 while True: try: t = input(\'输入一元二次方程系数a b c, 或者,输入#结束: \') if t == \'#\': print(\'结束计算,退出\') break a, b, c = map(float, t.split()) if a == 0: raise ValueError(\'a = 0, 不是一元二次方程\') except ValueError as e: print(repr(e)) print() except: print(\'有其它错误发生\\n\') else: root1, root2 = solve(a, b, c) print(f\'root1 = root1:.2f, root2 = root2:.2f\') print()
运行结果如图:

加了print(solve.__doc__)后:

4.实验任务4
def list_generator(start,end,step=1): lst = [] while start <= end: lst.append(start) start = start + step print(lst) list_generator(-5,5) list_generator(-5,5,2) list_generator(1,5,0.5)
运行结果如图:

5.实验任务5
def is_prime(n): for i in range(2,n+1): if n % i == 0 or n == 2: return False else: return True prime_list = [] for n in range(2,21): if is_prime(n) == True: prime_list.append(n) else: pass i = 2 while i <= 20: j = 0 while j < len(prime_list): k = 0 while k <len(prime_list): if prime_list[j] + prime_list[k] == i: print(f\'i = prime_list[j] + prime_list[k]\') else: pass k += 1 break # 找到后停止该循环 j += 1 i += 2
运行结果如图:

6.实验任务6
# 编码函数encoder()定义 def encoder(text): text_list = list(text) for i in range(len(text_list)): if ord(\'a\') <= ord(text_list[i]) <= ord(\'z\'): add5 = ord(text_list[i]) + 5 if add5 <= ord(\'z\'): text_list[i] = chr(add5) else: add5 = add5 % ord(\'z\') - 1 +ord(\'a\') text_list[i] = chr(add5) elif ord(\'A\') <= ord(text_list[i]) <= ord(\'Z\'): add5 = ord(text_list[i]) + 5 if add5 <= ord(\'z\'): text_list[i] = chr(add5) else: add5 = add5 % ord(\'Z\') - 1 +ord(\'A\') text_list[i] = chr(add5) else: pass return \'\'.join(text_list) # 解码函数decoder()定义 def decoder(text): text_list = list(text) for i in range(len(text_list)): if ord(\'a\') <= ord(text_list[i]) <= ord(\'z\'): red5 = ord(text_list[i]) - 5 if ord(\'a\') <= red5: text_list[i] = chr(red5) else: red5 = ord(\'z\') - (ord(\'a\') - red5 - 1) text_list[i] = chr(red5) elif ord(\'A\') <= ord(text_list[i]) <= ord(\'Z\'): red5 = ord(text_list[i]) - 5 if ord(\'A\') <= red5: text_list[i] = chr(red5) else: red5 = ord(\'Z\') - (ord(\'A\') - red5 - 1) text_list[i] = chr(red5) else: pass return \'\'.join(text_list) # 主体代码逻辑 text = input(\'输入英文文本: \') encoded_text = encoder(text) print(\'编码后的文本: \', encoded_text) decoded_text = decoder(encoded_text) print(\'对编码后的文本解码: \', decoded_text)
运行结果如图:

7.实验任务7
# collatz函数定义 def collatz(n): n_list.append(n) while True: if n % 2 == 0 and n != 0: collatz(n // 2) elif (n + 1) % 2 == 0 and n != 1: collatz(n * 3 + 1) elif n == 1: print(n_list) break # 自定义异常 class Error(Exception): def __init__(self,n): self.n = n def __str__(self): print(\'Error: must be a positive integer\') # 主题代码逻辑 try: n_list = [] n = input(\'输入一个正整数:\') if n.isdigit() == False: raise Error(n) elif int(n) <= 0: raise Error(n) else: collatz(int(n)) except Error: print(\'Error: must be a positive integer\')
8.实验任务8
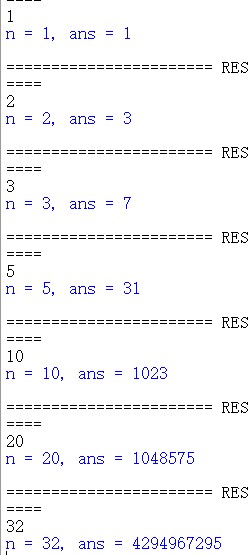
# 函数func()定义 def func(n): if n == 1: ans = 2 - 1 else: ans = 2 * func(n-1) +1 n -= 1 return ans # while True: x = input() if x == \'#\': print(\'计算结束\') break n = int(x) ans = func(n) print(f\'n = n, ans = ans\')
运行结果如图:
实验总结
作用域:LEGB(局部-嵌套-全句-内置)
参数: * 后面的只能按关键字传递
/前面的只能按位置传递
函数的异常和处理
嵌套:找出f(n)和f(n-1)的关系
函数式编程二 异常处理
基础
在java中用函数式的方式去做事情,Happy Path确实很好玩,但是编程中最不好玩的就是异常的情况。
通常函数式都是流式,然而通常不希望数据在流的过程中出现异常。于是出现了这么三种处理方式:
1.
F#中提出了Railway Oriented Programming[2] 特别有意思的一个想法。
2.
Try/Success/Failed 模式最早是在Twitter中提出的, 后被引入Scala的标准类库中。
3.
Option/Some/None模式是另一种处理模式。
2和3 在Scala文章中有详细的说明: FUNCTIONAL ERROR HANDLING IN SCALA[3]
强烈推荐去看一下,文章不长,也不枯燥。中间对比和2和3的优缺点,和使用场景。
了解了一番之后,回过头看Java的Optional弱鸡一个。
背景
1.
项目中用的是Java,然后处理数据是一批一批的处理,之后改成了函数式,并没有大动结构,只是用函数式给串了起来。
2.
由于传统面向对象思想的束缚,throw exception,在流中的操作原子中有出现。
3.
每个操作原子中可能会有副作用。
4。对业务代码无感知
1.能够给调用方返回数据
函数式编程最佳实「踩」践「坑」指南
函数式编程通常有这么一个原则:
所有在操作原子中主动抛异常的行为都是耍流氓。
标准的函数式异常处理模式有什么问题:无法携带异常数据。只能携带异常。
Java中有人实现了标准Scala的Try[4]。
有兴趣的可以看看,代码也很简单,一会就能看完。看完之后,自己手动实现java Optional就很轻松了。
Try的实现增强版
1.定义接口,用于承接数据
public interface IError<T> {T toSystemError();}
1.定义Try
// 定义承载数据类型为IN, 并且要实现IERROR// 定义异常类型为ERRORpublic final class Try<IN extends IError<ERROR>, ERROR> {// 流进来的数据private final IN value;// 承载的异常数据private final ERROR error;// 发生异常的现场private final Throwable exception;// success的构造函数private Try(IN IN) {this(IN, null, null);}// failed的构造函数private Try(IN IN, ERROR error, Throwable exception) {this.value = IN;this.error = error;this.exception = exception;}public boolean isSuccess() {return Objects.isNull(exception);}public boolean isFailed() {return !this.isSuccess();}public IN get() {return this.value;}// 流中数据类型的转化public <R extends IError<ERROR>> Try<R, ERROR> map(Function<IN, R> mapper) {return getData(mapper);}// 流中数据类型转化处理private <R extends IError<ERROR>> Try<R, ERROR> getData(Function<IN, R> mapper) {if (this.isFailed()) {return new Try<>(null, error, exception);}if (Objects.isNull(value)) {return new Try<>(null);}try {final R newValue = mapper.apply(value);return new Try<>(newValue);} catch (Exception e) {return new Try<>(null, value.toSystemError(), e);}}// 类似于flatMap,但是又不是。public <R> R transformTo(Function<IN, R> converter) {return converter.apply(value);}// 这里参照CompletableFuture的做法,并且参照了NodeJs的做法(error first)public void whenComplete(BiConsumer<Throwable, ERROR> afterFailed, Consumer<IN> afterSuccess) {if (this.isSuccess()) {afterSuccess.accept(value);} else {afterFailed.accept(exception, error);}}// 这里是Try的构造。public static <I extends IError<E>, R extends IError<E>, E> Try<R, E> apply(Supplier<R> supplier) {return new Try<>(supplier.get());}}
1.用法
class TryDemoTest {class TestClass implements TryDemo.IError<String> {private String id;public TestClass(String id) {this.id = id;}@Overridepublic String toSystemError() {return id;}}@Testvoid shouldExecNextStep() {final TestClass test =TryDemo.Try.apply(() -> new TestClass("start")).map(testClass -> new TestClass("1")).map(testClass -> new TestClass("2")).get();assertEquals("2", test.id);}@Testvoid shouldNotExecNextStep() {Function<TestClass, TestClass> exception = testClass -> {throw new NullPointerException();};TryDemo.Try.apply(() -> new TestClass("start")).map(testClass -> new TestClass("1")).map(exception).map(testClass -> new TestClass("3")).whenComplete((e, data) -> {// log ERROR and get Error dataassertTrue(true);assertEquals("1", data);}, successData -> {// handle success LogicassertFalse(true);});}}
总结
这里和原始的Try的不同在于原始的Try是一个抽象类,Success和Failed都是其具体的实现,没法同时持有success和failed,导致它没法持有异常数据。
References
[2] Railway Oriented Programming: https://fsharpforfunandprofit.com/rop/[3] FUNCTIONAL ERROR HANDLING IN SCALA: https://docs.scala-lang.org/overviews/scala-book/functional-error-handling.html[4] Try: https://github.com/lambdista/try
以上是关于实验4 函数与异常处理编程的主要内容,如果未能解决你的问题,请参考以下文章