软件工程快速入门(上)
Posted pythontesting
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软件工程快速入门(上)相关的知识,希望对你有一定的参考价值。
1什么是SDLC?

软件开发生命周期(SDLCSoftware Development Lifecycle)是构建软件的系统过程,可确保构建软件的质量和正确性。 SDLC流程旨在生产满足客户期望的高质量软件。软件开发应在预定义的时间范围和成本内完成。
SDLC包含详细的计划,解释如何规划,构建和维护特定的软件。 SDLC生命周期的每个阶段都有自己的流程和可交付成果,可以进入下一阶段。
为什么选择SDLC?
这里是SDLC对于开发软件系统非常重要的主要原因。
- 它为项目规划,调度和估算提供了基础
- 为一组标准活动和可交付成果提供框架
- 它是项目跟踪和控制的机制
- 提高项目规划对开发过程中所有相关利益相关者的可见性
- 增加并提高开发速度
- 改善客户关系
- 帮助您降低项目风险和项目管理计划开销
SDLC阶段
整个SDLC流程分为以下几个阶段:

- 阶段1:需求收集和分析
- 第2阶段:可行性研究:
- 第3阶段:设计:
- 阶段4:编码:
- 第5阶段:测试:
- 阶段6:安装/部署:
- 阶段7:维护:
阶段1:需求收集和分析:
该要求是SDLC流程的第一阶段。它由高级团队成员根据业内所有利益相关者和领域专家的意见进行。在此阶段还要规划质量保证要求并识别所涉及的风险。
此阶段更清晰地描述了整个项目的范围以及触发项目的预期问题,机会和指令。
要求收集阶段需要团队获得详细和精确的要求。这有助于公司完成必要的时间表,以完成该系统的工作。
第2阶段:可行性研究:
完成需求分析阶段后,下一步是定义和记录软件需求。此过程在“软件需求规范”文档的帮助下进行,该文档也称为“SRS”文档。它包括在项目生命周期中应设计和开发的所有内容。
主要有五种可行性检查:
- 经济:我们能否在预算范围内完成项目?
- 法律:我们能否将此项目作为网络法和其他监管框架/合规处理。
- 运营可行性:我们能否创建客户期望的运营?
- 技术:需要检查当前的计算机系统是否可以支持该软件
- 时间表:确定项目是否可以在给定的时间表内完成。
第3阶段:设计:
在第三阶段,系统和软件设计文档按照需求规范文档准备。这有助于定义整个系统架构。
该设计阶段作为模型下一阶段的输入。
在此阶段开发了两种设计文档:
高级设计(HLD)
- 每个模块的简要描述和名称
- 关于每个模块的功能的概述
- 模块之间的接口关系和依赖关系
- 识别数据库表及其关键元素
- 完整的架构图以及技术细节
详细设计(LLD)
- 模块的功能逻辑
- 数据库表,包括类型和大小
- 界面的完整细节
- 解决所有类型的依赖性问题
- 错误消息列表
- 为每个模块完成输入和输出
阶段4:编码:
一旦系统设计阶段结束,下一阶段就是编码。在此阶段,开发人员通过使用所选编程语言编写代码来开始构建整个系统。在编码阶段,任务分为单元或模块,并分配给各种开发人员。这是软件开发生命周期过程中最长的阶段。
在此阶段,开发人员需要遵循某些预定义的编码指南。他们还需要使用编译器,解释器,调试器等编程工具来生成和实现代码。
第5阶段:测试:
软件完成后,将其部署在测试环境中。测试团队开始测试整个系统的功能。这样做是为了验证整个应用程序是否符合客户要求。
在此阶段,QA和测试团队可能会发现一些与开发人员沟通的错误/缺陷。开发团队修复了该错误并将其发送回QA进行重新测试。此过程一直持续到软件无错误,稳定并根据该系统的业务需求工作。
阶段6:安装/部署:
一旦软件测试阶段结束并且系统中没有任何错误或错误,则开始最终部署过程。根据项目经理提供的反馈,最终软件将被发布并检查是否存在部署问题。
阶段7:维护:
部署系统后,客户开始使用已开发的系统,发生以下3项活动
- 错误修复 - 由于某些未完全测试的情况而报告错误
- 升级 - 将应用程序升级到较新版本的软件
- 增强功能 - 在现有软件中添加一些新功能
SDLC阶段的主要重点是确保继续满足需求,并确保系统继续按照第一阶段提到的规范执行。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
流行的SDLC模型
这里是SDLC生命周期的一些最重要的阶段:
- 瀑布模型
瀑布是一种广泛接受的SDLC模型。在这种方法中,软件开发的整个过程分为不同的阶段。在该SDLC模型中,一个阶段的结果充当下一阶段的输入。
该SDLC模型是文档密集型的,早期阶段记录了后续阶段需要执行的操作。
- 增量方法
增量模型不是单独的模型。它本质上是一系列瀑布循环。这些要求在项目开始时分为几组。对于每个组,遵循SDLC模型来开发软件。重复SDLC过程,每个版本都添加更多功能,直到满足所有要求。在此方法中,每个循环都充当先前软件版本的维护阶段。对增量模型的修改允许开发周期重叠。之后的循环可以在前一循环完成之前开始。
- V模型
在这种类型的SDLC模型测试和开发中,阶段是并行计划的。因此,侧面有验证阶段,另一侧有验证阶段。 V-Model通过编码阶段加入。
- 敏捷模型
敏捷方法是一种在任何项目的SDLC过程中促进开发和测试的持续交互的实践。在Agile方法中,整个项目分为小型增量构建。所有这些构建都是在迭代中提供的,每次迭代持续一到三周。
- 螺旋模型
螺旋模型是风险驱动的过程模型。此SDLC模型可帮助团队采用一个或多个流程模型的元素,如瀑布,增量,瀑布等。
该模型采用了原型模型和瀑布模型的最佳特征。螺旋方法是设计和开发活动中快速原型设计和并发性的结合。
- 大爆炸模型
Big bang模型专注于软件开发和编码中的所有类型的资源,没有或很少计划。这些要求在它们到来时就被理解和实施。
此模型最适合与较小规模开发团队合作的小型项目。它对学术软件开发项目也很有用。这是一个理想的模型,其中要求是未知的或未给出最终发布日期。
小结
结论
- SDLC是一个用于构建软件的系统过程,可确保所构建软件的质量和正确性
- SDLC流程为标准的一系列活动和可交付成果提供了框架
- 七个不同的SDLC阶段1)需求收集和分析2)可行性研究:3)设计4)编码5)测试:6)安装/部署和7)维护
高级团队成员进行需求分析阶段 - 可行性研究阶段包括在项目生命周期中应设计和开发的所有内容
- 在设计阶段,系统和软件设计文档是根据需求规范文档准备的
- 在编码阶段,开发人员通过使用所选编程语言编写代码来开始构建整个系统
- 测试是下一阶段,用于验证整个应用程序是否按照客户要求运行。
- 当软件测试阶段结束时,安装和部署面开始,并且系统中没有任何错误或错误
- 维护面中涉及的错误修复,升级和参与操作
- 瀑布,增量,敏捷,V型,螺旋,大爆炸是一些流行的SDLC模型
- SDLC包含详细的计划,解释如何规划,构建和维护特定的软件
2瀑布模型
什么是瀑布模型?
瀑布模型是一种将软件开发划分为不同阶段的顺序模型。 每个阶段都设计用于在SDLC阶段执行特定活动。 它由Winston Royce于1970年推出。

软件工程中瀑布模型的不同阶段
| 阶段 | 活动 |
|---|---|
| 需求收集阶段 | 从客户收集要开发的软件系统的详细要求 |
| 设计阶段 | 规划编程语言、数据库或者项目的其他高级技术细节 |
| 编码 | 在设计阶段之后,它是建立阶段,这只是编码软件 |
| 测试阶段 | 测试软件以验证它是否按照客户端提供的规范构建。 |
| 部署阶段 | 在相应的环境中部署应用程序 |
| 维护阶段 | 可能需要根据客户要求更改代码 |
何时使用SDLC瀑布模型
可以使用瀑布模型
- 需求不经常变化
- 应用并不复杂和庞大
- 项目很短
- 要求很明确
- 环境稳定
- 使用的技术和工具不是动态的,而且是稳定的
- 资源可用并经过培训
瀑布模型的利弊
| 好处 | 缺点 |
|---|---|
| 在下一个开发阶段之前,必须完成上一阶段 | 只能在阶段期间修复错误 |
| 适用于需求定义明确的小型项目 | 对于需求经常变化的复杂项目,这是不可取的 |
| 应该在完成每个阶段之前执行质量保证测试(验证和验证) | 测试介入很晚 |
| 精心编写的文档 | 文档占用了开发人员和测试人员的大量时间 |
| 项目完全依赖项目团队,客户干预最少 | 客户的宝贵反馈不能包含在正在进行的开发阶段 |
| 软件的任何变化都是在开发过程中进行的 | 完成的软件中出现的微小变化或错误可能会导致很多问题 |
3增量模型
什么是增量模型?
增量模型是一个软件开发过程,其中需求被分解为软件开发周期的多个独立模块。从分析设计,实施,测试/验证,维护开始逐步进行增量开发。

每次迭代都要经过需求,设计,编码和测试阶段。并且系统的每个后续版本都会将功能添加到先前版本,直到实现了所有设计的功能。

系统在交付第一个增量时投入生产。第一个增量通常是解决基本要求的核心产品,并在下一个增量中添加补充功能。一旦客户分析了核心产品,就会有下一个增量的计划开发。
增量模块的特征包括
- 系统开发分解为许多小型开发项目
- 部分系统相继构建以产生最终的总系统
- 首先解决最高优先级要求
- 一旦制定了要求,就会冻结对该增量的要求
需求分析:收集软件的要求和规格
设计: 在此阶段设计了一些高端功能
编码:在此阶段完成软件编码
测试:部署系统后,它将进入测试阶段
何时使用增量模型?
- 清楚地理解系统的要求
- 当产品的早期发布需求出现时
- 当软件工程团队不熟练或训练有素时
- 当涉及高风险特征和目标时
- 这种方法更多地用于Web应用程序和基于产品的公司
优点:
- 软件将在软件生命周期中快速生成
- 更改要求和范围更灵活,成本更低
- 发展阶段的变化可以做到
- 与其他模型相比,该模型的成本更低
- 客户可以回复每个版本
- 错误很容易识别
缺点:
- 它需要一个良好的规划设计
- 问题可能是由于系统架构导致的,因此并非所有需求都在整个软件生命周期中预先收集
- 每个迭代阶段都是刚性的,并且彼此不重叠
- 在一个单元中纠正问题需要在所有单元中进行校正并且消耗大量时间
4螺旋模型
什么是螺旋模型?
螺旋模型是瀑布模型和迭代模型的组合。螺旋模型中的每个阶段都以设计目标开始,最后由客户审查进度。 Barry Boehm在1986年的论文中首次提到螺旋模型。
Spiral-SDLC模型的开发团队从一小部分需求开始,并针对这些需求进行每个开发阶段。软件工程团队在每个不断增加的螺旋中增加了额外需求的功能,直到应用程序为生产阶段做好准备。

螺旋模型阶段
- 计划
它包括估算迭代的成本,进度和资源。它还涉及了解系统分析员与客户之间持续通信的系统要求
-
风险分析
在规划和最终确定风险缓解策略的同时,确定潜在风险 -
工程
它包括在客户现场测试,编码和部署软件 -
评估
由客户评估软件。此外,还包括识别和监控诸如进度滑点和成本超支等风险
什么时候使用螺旋方法?
- 当项目很大时
- 需要频繁发布
- 创建原型时适用
- 风险和成本评估很重要时
- 适用于中高风险项目
- 当要求不清楚和复杂时
- 随时可能需要更改
- 由于经济优先事项的变化,长期项目承诺不可行
螺旋模型的优缺点
好处
- 其他功能或更改可在稍后阶段完成
- 由于原型建筑是以小碎片完成的,因此成本估算变得容易
- 持续或重复的开发有助于风险管理
- 开发速度快,功能以系统的方式添加
- 始终存在客户反馈的空间
缺点
- 不符合时间表或预算的风险
- 它最适合大型项目,也需要风险评估专业知识
- 为了顺利运行,需要严格遵循螺旋模型协议
- 文档更多,因为具有中间阶段
- 对于较小的项目,这是不可取的,它可能会花费很多
5RAD快速应用程序开发模型
什么是RAD(快速应用程序开发)模型?
RAD或Rapid Application Development流程采用瀑布模型;它的目标是在短时间内开发软件。
SDLC RAD模型具有以下阶段
- 业务建模
- 数据建模
- 流程建模
- 应用程序生成
- 测试和Turnover

它侧重于信息的输入输出源和目的地。它强调以小块形式提供项目;较大的项目分为一系列较小的项目。 RAD模型的主要特点是它专注于模板,工具,流程和代码的重用。

RAD模型的阶段
- 业务建模:根据各种业务渠道之间的信息流动和分配,设计产品
- 数据建模:从业务建模收集的信息被细化为一组对业务有重要意义的数据对象
- 流程建模:转换在数据建模阶段声明的数据对象,以实现实现业务功能所需的信息流
- 应用程序生成:自动化工具用于构建软件,将过程和数据模型转换为原型
- 测试和Turnover:由于原型在每次迭代期间都经过单独测试,因此RAD的整体测试时间会缩短。
何时使用RAD Methodology?
- 当需要在短时间内(2-3个月)生产系统时
- 当要求已知时
- 当用户将参与整个生命周期
- 当技术风险较小时
- 当有必要创建一个可以在2-3个月内模块化的系统
- 当预算足够高时,可以为设计人员提供建模以及代码生成的自动化工具的成本
SDLC RAD模型的优缺点
好处
- 灵活且适应变化
- 当您必须降低整体项目风险时,它非常有用
- 它具有适应性和灵活性
- 以脚本,高级抽象和中间代码的形式传输可交付物更容易
- 由于代码生成器和代码重用,减少了手动编码
- 由于本质上的原型设计,可能存在较少的缺陷
- RAD的每个阶段都为客户提供最高优先级的功能
人员越少,生产力就能在短时间内增加
缺点
- 它不能用于较小的项目
- 并非所有应用程序都与RAD兼容
- 当技术风险很高时,它是不合适的
- 如果开发人员不致力于按时交付软件,RAD项目可能会失败
- 由于时间装箱而减少的功能,其中功能被推送到更高版本以在短时间内完成发布
- 由于RAD开发的应用程序作为原型开始并演变为完成的应用程序,因此降低了可伸缩性
- 习惯性的进步和问题难以跟踪,因此没有文件证明已经完成的工作
- 需要高技能的设计师或开发人员
| 模型 | 瀑布 | 增量模型 | 螺旋模型 | Rad模型 |
|---|---|---|---|---|
| 早期规划 | 是 | 是 | 是 | 没有 |
| 回到早期阶段 | 没有 | 是 | 是 | 是 |
| 处理大型项目 | 不适当 | 不适当 | 适当 | 不适当 |
| 详细文档 | 必要 | 会,但不多 | 是 | 有限 |
| 成本 | 低 | 低 | 昂贵 | 低 |
| 需求规格 | 开始 | 开始 | 开始 | 时间盒发布 |
| 灵活变革 | 难 | 简单 | 简单 | 简单 |
| 用户参与 | 只在开始时 | 中间 | 高 | 只在一开始 |
| 维护性 | 最小 | 促进可维护性 | 典型 | 易于维护 |
| 持续时间 | 长 | 很长 | 长 | 短 |
| 风险 | 高 | 低 | 中到高风险 | 低 |
| 框架类型 | 线性 | 线性+迭代 | 线性+迭代 | 线性 |
| 测试 | 编码阶段完成后 | 每次迭代后 | 在工程阶段结束时 | 编码完成后 |
| 迭代 | 没有 | 是(因为并行开发) | 没有 | 是 |
| 可重用性 | 最少可能 | 在某种程度上 | 在某种程度上 | 是 |
| 大体时间 | 很长 | 长 | 长 | 短 |
| 工作软件可用性 | 在生命周期结束时 | 在每次迭代结束时 | 在每次迭代结束时 | 在生命周期结束时 |
| 目的 | 高保证 | 快速发展 | 高保证 | 快速发展 |
| 团队规模 | 大团队 | 不是大团队 | 大团队 | 小团队 |
| 客户控制 | 非常低 | 是 | 是 | 是 |
6原型模型
什么是软件原型模型?
原型方法被定义为软件开发模型,其中构建原型,测试,然后在需要时重新加工,直到实现可接受的原型。 它还创建了生成最终系统的基础。
软件原型模型在项目要求未知的情况下效果最佳。 它是一种在开发人员和客户端之间进行的迭代,试验和错误方法。
原型模型阶段

原型模型遵循以下六个SDLC阶段:
- 第1步:需求收集和分析
原型模型从需求分析开始。 在此阶段,详细定义了系统的要求。 在此过程中,对系统的用户进行访谈,以了解他们对系统的期望。
- 第2步:快速设计
第二阶段是初步设计或快速设计。 在这个阶段,创建了一个简单的系统设计。 但是,它不是一个完整的设计。 它向用户简要介绍了系统。 快速设计有助于开发原型。
- 第3步:构建原型
在此阶段,基于从快速设计收集的信息设计实际原型。 它是所需系统的小型工作模型。
- 第4步:初始用户评估
在此阶段,建议的系统将提交给客户进行初步评估。 它有助于找出工作模型的优缺点。 评论和建议从客户收集并提供给开发人员。
- 第5步:精炼原型
如果用户对当前原型不满意,您需要根据用户的反馈和建议优化原型。
在满足用户指定的所有要求之前,此阶段不会结束。 一旦用户对开发的原型感到满意,就会根据批准的最终原型开发最终系统。
- 第6步:实施产品和维护
一旦最终系统基于最终原型开发,它就会经过全面测试并部署到生产中。 该系统进行日常维护,以最大限度地减少停机时间并防止大规模故障。
原型模型的类型
四种原型模型是:
- 原型
- 进化原型
- 增量原型
- 极端原型
- 快速原型
快速一次性是基于初步要求。 它很快就被开发出来以显示需求在视觉上的外观。 客户的反馈有助于推动对需求的更改,并再次创建原型,直到需求基线为止。
在这种方法中,开发的原型将被丢弃,并且不会成为最终接受的原型的一部分。 该技术对于探索想法和获得客户需求的即时反馈非常有用。
- 进化原型
在这里,开发的原型根据客户的反馈逐步完善,直到最终被接受为止。 它可以帮助您节省时间和精力。 这是因为从头开始为过程的每次互动开发原型有时会非常令人沮丧。
该模型对于使用未被充分理解的新技术的项目很有帮助。 它还用于复杂项目,其中必须检查每个功能一次。 当要求不稳定或在初始阶段不清楚时,这是有帮助的。
- 增量原型
在增量型原型设计中,最终产品被抽取为不同的小型原型并单独开发。 最终,不同的原型被合并为一个产品。 此方法有助于缩短用户与应用程序开发团队之间的反馈时间。
- 极端原型:
极端原型方法主要用于Web开发。 它由三个连续阶段组成。
- 所有现有页面的基本原型都以HTML格式显示。
- 您可以使用原型服务层模拟数据流程。
- 这些服务已实施并整合到最终原型中。
原型设计的最佳实践
在这里,您需要在原型制作过程中注意以下几点:
- 当要求不清楚时,您应该使用原型
- 执行计划和控制的原型设计非常重要。
- 定期会议对于保持项目准时并避免代价高昂的延误至关重要。
- 用户和设计人员应该了解原型设计问题和陷阱。
- 在很早的阶段,您需要批准原型,然后才允许团队进入下一步。
- 在软件原型设计方法中,如果需要部署新的想法,就不应该害怕改变先前的决策。
- 您应该为每个版本选择适当的步长。
- 尽早实施重要功能,以便在用完时,您仍然拥有一个有价值的系统
原型模型的优点
在这里,使用Prototyping模型是重要的优点/好处:
- 用户积极参与开发。 因此,可以在软件开发过程的初始阶段检测错误。
- 可以识别缺失的功能,这有助于降低故障风险,因为原型设计也被视为降低风险的活动。
- 帮助团队成员有效沟通
- 客户满意度的存在是因为客户可以在很早的阶段就能感受到产品。
- 几乎没有软件拒绝的可能性。
- 更快的用户反馈可帮助您实现更好的软件开发解决方案。
- 允许客户端比较软件代码是否与软件规范匹配。
- 它可以帮助您找出系统中缺少的功能。
- 它还确定了复杂或困难的功能。
- 鼓励创新和灵活的设计。
- 这是一个简单的模型,因此很容易理解。
- 无需专业专家来构建模型
- 原型作为推导系统规范的基础。
- 原型有助于更好地了解客户的需求。
- 原型可以改变甚至丢弃。
- 原型也可作为操作规范的基础。
- 原型可以为软件系统的未来用户提供早期培训。
原型模型的缺点
这里是原型设计模型的重要缺点:
- 原型设计是一个缓慢且耗时的过程。
- 由于原型最终被丢弃,开发原型的成本完全是浪费。
- 原型设计可能会鼓励过多的变更请求。
- 有时,客户可能不愿意在更长的持续时间内参与迭代周期。
- 每次客户评估原型时,软件需求可能会有太多变化。
- 文档很差,因为客户的要求正在发生变化。
- 软件开发人员很难适应客户要求的所有变更。
- 在看到早期的原型模型后,客户可能会认为实际的产品很快会交付给他。
- 当客户对初始原型不满意时,客户可能会对最终产品失去兴趣。
- 想要快速构建原型的开发人员最终可能会构建不合标准的开发解决方案。
摘要
- 在软件工程中,Prototype方法是一种软件开发模型,其中构建原型,测试然后在需要时重新工作直到获得可接受的原型。
- 1)需求收集和分析,2)快速设计,3)构建原型,4)初始用户评估,5)精炼原型,6)实施产品和维护; 是原型制作过程的6个步骤
- 原型模型的类型是1)Rapid Throwaway原型2)进化原型3)增量原型4)极端原型
- 定期会议对于保持项目准时并避免原型制作方法出现代价高昂的延误至关重要。
- 可以识别缺失的功能,这有助于降低故障风险,因为原型设计也被视为SDLC中的风险降低活动。
- 原型设计可能会鼓励过多的变更请求。
能力成熟度模型CMM
什么是CMM?
能力成熟度模型(Capability Maturity Model)用作衡量组织软件过程成熟度的基准。
CMM是在80年代后期在软件工程研究所开发的。 它是由美国空军资助的一项研究的结果,作为评估分包商工作的一种方式。 后来基于1991年创建的CMM-SW模型来评估软件开发的成熟度,其他多个模型与CMM-I集成在一起

什么是能力成熟度模型(CMM)级别?
- 初始
- 重复/管理
- 定义
- 量化管理
- 优化
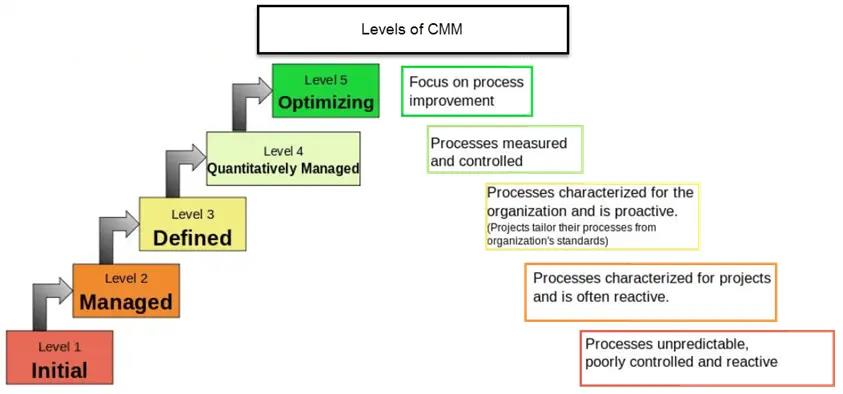
不同级别的CMM会发生什么?
| 水平 | 活动 | 优点 |
|---|---|---|
| 1级初始 | 在第1级,该过程通常是混乱和临时的;能力的特征是基于个人而非组织; 未衡量进展;开发的产品通常是计划和超出预算;计划,成本,功能和质量目标的差异很大 | 没有 |
| 2级管理 | 需求管理; 估算项目参数,如成本,进度和功能;衡量实际进度;制定计划和流程; 定义了软件项目标准;识别和控制产品,问题报告的变化等;项目之间的流程可能不同 | 流程变得更容易理解;管理人员和团队成员花费更少的时间来解释事情的完成方式以及执行事务的时间;项目得到更好的估计,更好的计划和更灵活;质量已融入项目中;成本可能最初很高,但加班时间会下降;更多文书工作和文件 |
| Level-3定义 | 澄清客户要求;解决设计要求,制定实施流程;确保产品符合要求和预期用途;系统地分析决策\'纠正和控制潜在的问题 | 流程改进成为标准;解决方案从“编码”发展到“工程化”;在整个项目工作中出现质量门,整个团队参与该过程;风险得到缓解,不会让团队感到意外 |
| 4级定量管理 | 统计管理项目的流程和子流程;了解流程绩效,定量管理组织的项目; | 优化整个组织的流程绩效;促进组织中的定量项目管理。 |
| 5级优化 | 及早发现并消除缺陷的原因;确定并部署新工具和流程改进,以满足需求和业务目标 | 促进组织创新和部署;推动因果分析和解决方案 |
下图给出了在不同CMM级别发生的情况的图示
和CMM级别:傻瓜指南")
实施CMM需要多长时间?
CMM是维护任何软件开发公司产品质量的最理想的流程,但其实施所需的时间比预期的要长。
-
CMM实施不会在一夜之间发生
-
这不仅仅是一个“文书工作”。
-
典型的实施时间是
- 3-6个月- >准备
- 6-12个月- >实施
- 3个月- >进行评估准备
- 12个月-每个新级别> b
CMM的内部结构
CMM中的每个级别都定义为关键过程域或KPA (key process area) ,级别1除外。 每个KPA都定义了一组相关活动,这些活动在共同执行时实现了一组对提高软件能力至关重要的目标
对于不同的CMM级别,有一组KPA,例如对于CMM模型-2,KPA是
- REQM-需求管理
- PP-项目规划
- PMC-项目监测和控制
- SAM-供应商协议管理
- PPQA-流程和质量保证
- CM配置管理
同样,对于其他CMM模型,您有特定的KPA。 要了解KPA的实施是否有效,持久和可重复,它将根据以下基础进行绘图
- 承诺执行
- 能够执行
- 活动执行
- 测量和分析
- 验证实施
CMM模型的局限性
- CMM确定流程应该解决的问题,而不是如何实施
- 它没有解释软件过程改进的所有可能性
- 它专注于软件问题,但不考虑战略业务规划,采用技术,建立产品线和管理人力资源
- 它没有说明组织应该从事什么样的业务
- CMM在目前正面临危机的项目中没有用处
为何使用CMM?
今天,CMM充当软件行业的“批准印章”。 它有助于以各种方式提高软件质量。
- 它指导可重复的标准流程,从而缩短了如何完成工作的学习时间
- 实践CMM意味着实践标准协议进行开发,这意味着它不仅可以帮助团队节省时间,还可以清楚地了解要做什么和期望什么
- 质量活动与项目完美结合,而不是单独的事件
- 它充当项目和团队之间的通勤者
- CMM的努力始终是为了改进流程
摘要
CMM于80年代末首次在美国空军引入,用于评估分包商的工作。 后来,通过改进版本,它被实现为跟踪软件开发系统的质量。
整个CMM级别分为五个级别。
- 1级 (初始):系统的要求通常是不确定的,误解和不受控制的。 这个过程通常是混乱和临时的。
- 2级 (管理):估算项目成本,进度和功能。 软件标准已定义
- 3级 (定义):确保产品符合要求和预期用途
- 4级 (定量管理):统计管理项目的流程和子流程
- 5级 (成熟度):识别和部署新工具和流程改进,以满足需求和业务目标
8多层架构
什么是N-Tier?
N层应用程序是分布在分布式网络中的三个或更多个单独计算机之间的程序。
最常见的n层形式是3层应用程序,它分为三类。
- 用户计算机中的用户界面编程
- 更集中的计算机中的业务逻辑,和
- 管理数据库的计算机中的必需数据。
此体系结构模型为软件开发人员提供了最大灵活性的可重用应用程序/系统。
在N层中,“N”指的是正在使用的层数或层数,如 - 2层,3层或4层等 。 它也被称为“ 多层 架构”。
n层架构是经过行业验证的软件架构模型。 它通过提供可伸缩性,安全性,容错性,可重用性和可维护性的解决方案,适合支持企业级客户端 - 服务器应用程序。 它可以帮助开发人员创建灵活且可重用的应用程序。
N层架构
此处描述了n层系统的图形表示 - 表示层,应用程序层和数据库层。

根据要求,这三层可以进一步细分为不同的子层。
一些应用这种架构的热门网站是
- MakeMyTrip.com
- Sales Force企业应用程序
- 印度铁路 - IRCTC
- 亚马逊等
要记住一些常用术语,以便更清楚地理解概念。
-
分布式网络:它是一种网络体系结构,位于网络计算机上的组件仅通过传递消息来协调和传递其操作。 它是位于不同节点的多个系统的集合,但在用户看来是单个系统。
- 它提供单个数据通信网络,可以由不同的网络单独管理。
- 分布式网络的一个示例 - 其中不同的客户端在一侧的LAN架构内连接,另一侧连接到高速交换机以及包含服务节点的服务器机架。
-
客户端 - 服务器体系结构:它是一种体系结构模型,其中客户端(一个程序)从服务器(另一个程序)请求服务, 即它是通过因特网或通过内联网提供的请求 - 响应服务。
在此模型中, 客户端将作为一组程序/代码,通过网络执行一组操作。 另一方面, Server是一组另一个程序,它根据请求将结果集发送到客户端系统。
- 在此,客户端计算机向终端用户提供从服务器请求服务或资源的接口,另一方面服务器然后处理该请求并将结果显示给最终用户。
- 客户端 - 服务器模型的一个例子 - ATM机。 银行是用于在大客户数据库内处理应用程序的服务器,并且ATM机器是具有用户界面的客户端,具有一些简单的应用程序处理。
-
平台:在计算机科学或软件行业中,平台是应用程序可以运行的系统。 它由硬件和软件组合而成,具有内置指令,供处理器/微处理器执行特定操作。
- 换句话说,平台是一个系统或基础,任何应用程序都可以运行和执行以获得特定任务。
- 平台示例 - 装有ubuntu或Mac OS X的个人计算机,作为2个不同平台的示例。
-
数据库:它是一种有组织的信息集合,因此可以轻松访问,管理和更新。
- 数据库的例子 - mongoDB, MySQL,postgresql和Oracle数据库是一些常见的Db。
N层架构的类型
有不同类型的N层体系结构,如3层体系结构,2层体系结构和1层体系结构。
首先,我们将看到3层架构,这非常重要。
3层架构
通过查看下图,您可以轻松识别3层架构有三个不同的层。
- 表示层
- 业务逻辑层
- 数据库层
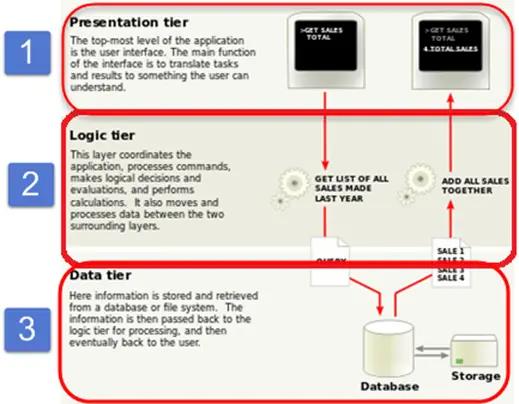
在这里,我们采用了一个简单的学生形式示例来理解所有这三个层次。 它包含有关学生的信息 - 姓名,地址,电子邮件和图片。
用户界面层或表示层

private void DataGrid1_SelectedIndexChanged(object sender, System.EventArgs e)
// Object of the Property layer
clsStudent objproperty=new clsStudent();
// Object of the business layer
clsStudentInfo objbs=new clsStudentInfo();
// Object of the dataset in which we receive the data sent by the business layer
DataSet ds=new DataSet();
// here we are placing the value in the property using the object of the
//property layer
objproperty.id=int.Parse(DataGridl.SelectedItem.Cells[1].Text.ToString());
// In this following code we are calling a function from the business layer and
// passing the object of the property layer which will carry the ID till the database.
ds=objbs.GetAllStudentBsIDWise(objproperty);
// What ever the data has been returned by the above function into the dataset
//is being populate through the presentation laye.
txtId.Text=ds.Tables[0].Rows[0][0].ToString();
txtFname.Text=ds.Tables[0].Rows[0][1].ToString();
txtAddress.Text=ds.Tables[0].Rows[0][2].ToString();
txtemail.Text=ds.Tables[0].Rows[0][3].ToString();
业务访问层 -
这是业务层的功能,它接受来自应用层的数据并将其传递给数据层。
- 业务逻辑充当客户端层和数据访问层之间的接口
- 所有业务逻辑 - 如数据验证,计算,数据插入/修改都是在业务逻- 辑层下编写的。
- 它使客户端和数据层之间的通信更快捷,更容易
- 定义完成任务所需的正确工作流活动。
// this is the function of the business layer which accepts the data from the
//application layer and passes it to the data layer.
public class clsStudentInfo
public DataSet GetAllStudentBsIDWise(clsStudent obj)
DataSet ds=new DataSet();
ds=objdt.getdata_dtIDWise(obj);// Calling of Data layer function
return ds;
数据访问层
这是数据层功能,它从业务层接收数据并对数据库执行必要的操作。
// this is the datalayer function which is receiving the data from the business
//layer and performing the required operation into the database
public class clsStudentData // Data layer class
// object of property layer class
public DataSet getdata_dtIDUise(clsStudent obj)
DataSet ds;
string sql;
sql="select * from student where Studentld=" +obj.id+ "order by Studentld;
ds=new DataSet();
//this is the datalayer function which accepts the sql query and performs the
//corresponding operation
ds=objdt.ExecuteSql(sql);
return ds;
单层或单层架构:
它是最简单的一个,因为它等同于在个人计算机上运行应用程序。 运行应用程序所需的所有组件都在单个应用程序或服务器上。
表示层,业务逻辑层和数据层都位于一台机器上。
多层体系结构的优缺点
好处
- 可扩展性
- 数据的完整性
- 可重用性
- 更容易分布式
- 提高安全性
- 提高可用性
缺点
- 增加工作量
- 增加复杂性
N层架构技巧与发展
考虑到软件专业人员必须完全控制架构的所有层,有关n层架构的提示如下
- 尝试使用soap XML等技术尽可能地将图层与其他图层分离。
- 使用一些自动化工具生成业务逻辑层和关系数据库层(数据层)之间的映射。 可以帮助建模这些映射技术的工具是 - Entity Framework和Hibernate for .Net等。
- 在客户端演示者层中,尽可能将所有客户端的公共代码放在单独的库中。 这将最大化所有类型客户端的代码可重用性。
- 可以将缓存层添加到现有层中以加速性能。
小结:
- N层体系结构有助于在一个屋檐下管理应用程序的所有组件(业务层,表示层和数据库层)。
-在局域网上使用少量用户的应用程序可以受益于n层架构。
-这种架构设计确定了在因特网上有效地维护,扩展和部署应用程序。
Ngnix快速入门
Nginx快速入门
[TOC]
Nginx基本概述
如果听说过或使用过Apache软件,那么很快就会熟悉Nginx软件,与Apache软件类似,Nginx(“engine x”)是一个开源的,支持高性能.高并发的www服务器和代理软件。它是由俄罗斯人lgor Sysoev开发的,最初被应用在俄罗斯的大型网站www.rambler.ru 上。后来作者将源代码以类BSD许可证的形式开源出来供全球使用
Nginx因具有高并发(特别是静态资源)占用系统资源少等特性,因为功能越来越多逐渐流行起来。
在功能方面,Nginx不但是一个优秀的Web服务软件,还具有反向代理,负载均衡和缓存服务功能在反向代理和负载均衡方面,类似于大名鼎鼎的LVS负载均衡及Haproxy等专业代理软件,但是Nginx部署起来更加简单且方便。 在缓存方面,又类似于Squid等专业软件,但是最常用的缓存软件是memcache 它的功能比Nginx的缓存更加强大
Nginx近两年也逐渐被越来越多的中小型网站所用。比较流行的Web架构是LNMP或LEMP LEMP取自(engine x) 目前LNMT架构更为强大
Nginx的官方介绍 http://nginx.org/en/
常见的 HTTP Web服务
Httpd 由Apache基金会
IIS 微软服务器版
GWS Google开发
Openrestry 基于nginx+lua
Tengline 淘宝基于Nginx开发Nginx的重要特点
支持高并发:能支持几万并发连接 (特捏死静态小文件业务环境)
资源消耗少:在3万并发连接下,开启10个Nginx线程消耗的内存不到200MB
可以做HTTP反向代理及加速缓存 即负载均衡功能,内置·对RS节点服务器健康检查功能,这相当于专业的Haproxy软件或Lvs的功能
具备Squid等专业缓存软件的缓存功能
支持异步网络I/O事件模型 epoll(linux 2.6+)为什么选择 Nginx
1.Nginx非常轻量
1.功能模块少(源代码仅保留http与核心模块代码,其余不够核心代码会作为插件来安装)
2.代码模块化(易读,便于二次开发,对于开发人员是非常友好)
2.互联网公司都选择Nginx
1.技术成熟, 大公司都选择Nginx
2.统一技术选型工具, 降低维护成本,减少故障几率。
3.Nginx涉足场景较多,技术更新成本低。
3.Nginx采用Epool网络模型, Apache采用Select模型。
Select: 当用户发起一次请求,select模型就会进行一次遍历扫描,从而导致性能低下。
Epoll: 当用户发起请求,epool模型会直接进行处理,效率高效,并无连接限制。Nginx 应用场景
静态处理(mp4|html|png|jpg) -> 服务端存放的是什么,客户端浏览器就展示什么
反向代理
负载均衡
代理缓存
访问限制 (tcp连接数、http请求数)
访问认证 (用户和密码、来源IP)
安全防护 (waf防火墙,使用lua实现的,花钱买服务,花钱买经验)Nginx快速安装
1.epel仓库=>Nginx(1.版本低 2.配置文件不一样)
2.源码编译=>Nginx(1.复杂 2.企业不使用)
3.官方仓库=>Nginx)(√1.版本较新 2.安装简单 3.配置不复杂)
1.配置Nginx官方的仓库
[[email protected] ~]# vim /etc/yum.repos.d/nginx.repo
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
enabled=1
2.安装Nginx【一定确认是通过官方的仓库安装上】
[[email protected] ~]# yum install nginx -y
3.检查版本【1.14.0】
[[email protected] ~]# nginx -v
nginx version: nginx/1.14.04.查看nginx编译的参数
nginx -V
5.编译参数越多越好,还是越少越好?
源码编译好了,做成的rpm包
越少:功能少,后期可维护性差
越多:功能全,覆盖广,可维护性强Nginx安装目录
为了让大家更清晰的了解Nginx软件的全貌,有必要介绍下Nginx安装后整体的目录结构及文件功能。
[[email protected] ~]# rpm -ql nginx如下表格对Nginx安装目录做详细概述
路径 类型 作用
/etc/nginx
/etc/nginx/nginx.conf
/etc/nginx/conf.d
/etc/nginx/conf.d/default.conf 配置文件 Nginx主配置文件
/etc/nginx/fastcgi_params
/etc/nginx/scgi_params
/etc/nginx/uwsgi_params 配置文件 Cgi、Fastcgi、Uwcgi配置文件
/etc/nginx/win-utf
/etc/nginx/koi-utf
/etc/nginx/koi-win 配置文件 Nginx编码转换映射文件
/etc/nginx/mime.types 配置文件 http协议的Content-Type与扩展名
/usr/lib/systemd/system/nginx.service 配置文件 配置系统守护进程管理器
/etc/logrotate.d/nginx 配置文件 Nginx日志轮询,日志切割
/usr/sbin/nginx
/usr/sbin/nginx-debug 命令 Nginx终端管理命令
/etc/nginx/modules
/usr/lib64/nginx
/usr/lib64/nginx/modules 目录 Nginx模块目录
/usr/share/nginx
/usr/share/nginx/html
/usr/share/nginx/html/50x.html
/usr/share/nginx/html/index.html 目录 Nginx默认站点目录
/usr/share/doc/nginx-1.12.2
/usr/share/man/man8/nginx.8.gz 目录 Nginx的帮助手册
/var/cache/nginx 目录 Nginx的缓存目录
/var/log/nginx 目录 Nginx的日志目录Nginx编译参数
查看Nginx编译参数
[[email protected] ~]# nginx -V下表展示了Nginx编译参数选项以及作用
编译选项 作用
--prefix=/etc/nginx
--sbin-path=/usr/sbin/nginx
--modules-path=/usr/lib64/nginx/modules
--conf-path=/etc/nginx/nginx.conf
--error-log-path=/var/log/nginx/error.log
--http-log-path=/var/log/nginx/access.log
--pid-path=/var/run/nginx.pid
--lock-path=/var/run/nginx.lock 程序安装目录和路径
--http-client-body-temp-path=/var/cache/nginx/client_tem
--http-proxy-temp-path=/var/cache/nginx/proxy_temp
--http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp
--http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp
--http-scgi-temp-path=/var/cache/nginx/scgi_temp 临时缓存文件?
--user=nginx
--group=nginx 设定Nginx进程启动用户和组(安全)
--with-cc-opt 设置额外的参数将被添加到CFLAGS变量
--with-ld-opt 设置附加的参数, 链接系统库
?
Nginx配置文件
Nginx主配置文件/etc/nginx/nginx.conf是一个纯文本类型的文件,整个配置文件是以区块的形式组织的。一般,每个区块以一对大括号{}来表示开始与结束。
1.CoreModule 核心模块
2.EventModule 事件驱动模块
3.HttpCoreModule http内核模块需了解扩展项
CoreModule层下可以有Event、HTTP
HTTP模块层允许有多个Server层, Server主要用于配置多个网站
Server层又允许有多个Location, Location主要用于定义网站访问路径CoreModule 核心模块
user www; #Nginx进程所使用的用户
worker_processes 1; #运行的进程数量
error_log /log/nginx/error.log #错误日志
pid /var/run/nginx.pid #Nginx服务启动后产生的pid进程号events事件模块
events {
worker_connections //每个worker进程支持的最大连接
use epool; //事件使用的模型(默认epool)
} //事件模块结束http内核模块
http { # http开始
include /etc/nginx/mime.types; # 包含
default_type application/octet-stream; #
# 定义日志的格式
log_format main ‘$remote_addr - $remote_user [$time_local] "$request" ‘
‘$status $body_bytes_sent "$http_referer" ‘
‘"$http_user_agent" "$http_x_forwarded_for"‘;
# 访问日志存放的路径【main是日志的格式】
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65; # 长连接
#gzip on; # 压缩
include /etc/nginx/conf.d/*.conf; # 所有的conf结尾的文件都被包含起来
server { # 我要定义一个网站【博客】
listen 80; # 监听80端口
server_name localhost; # 对应的域名
location / { # 用户请求域名时,默认匹配的规则
root /usr/share/nginx/html; # 网站根目录
index index.html index.htm; # 访问的默认页面
}
error_page 500 502 503 504 /50x.html; # 定义错误页面的
}}
部署一个站点
1.对应的nginx配置文件
[[email protected] conf.d]# cat /etc/nginx/conf.d/oldboy_game.conf
server {
listen 80;
server_name game.oldboy.com;
location / {
root /oldboy_code;
index index.html;
}
}2.对应的源代码文件【手动-太low】 就是代码上线
[[email protected] conf.d]# mkdir /oldboy_code
[[email protected] conf.d]# cd /oldboy_code/
[[email protected] oldboy_code]# rz html5.zip
[[email protected] oldboy_code]# unzip html5.zip
[[email protected] oldboy_code]# pwd
/oldboy_code
[[email protected] oldboy_code]# ls
ceshi game html5.zip img index.html readme.txt3.检查nginx的语法
[[email protected] oldboy_code]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful4.重载Nginx【reload|restart】
[[email protected] oldboy_code]# #nginx -s reload
[[email protected] oldboy_code]# systemctl reload nginx5.如何访问:
1.通过服务器的IP直接访问:10.0.0.7
2.通过域名方式访问
Windows: C:WindowsSystem32driversetchosts 文件
Mac: sudo vim /etc/hosts
10.0.0.7 game.oldboy.com
3.使用ping命令测试域名解析是否正常以上是关于软件工程快速入门(上)的主要内容,如果未能解决你的问题,请参考以下文章