吴裕雄 python 机器学习-KNN算法
Posted 天生自然
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴裕雄 python 机器学习-KNN算法相关的知识,希望对你有一定的参考价值。
import numpy as np
import operator as op
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=op.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createDataSet():
group = np.array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = [\'A\',\'A\',\'B\',\'B\']
return group, labels
data,labels = createDataSet()
print(data)
print(labels)
test = np.array([[0,0.5]])
result = classify0(test,data,labels,3)
print(result)

import numpy as np import operator as op from os import listdir def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = np.tile(inX, (dataSetSize,1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 sortedClassCount = sorted(classCount.items(), key=op.itemgetter(1), reverse=True) return sortedClassCount[0][0] def file2matrix(filename): fr = open(filename) returnMat = [] classLabelVector = [] #prepare labels return for line in fr.readlines(): line = line.strip() listFromLine = line.split(\'\\t\') returnMat.append([float(listFromLine[0]),float(listFromLine[1]),float(listFromLine[2])]) classLabelVector.append(int(listFromLine[-1])) return np.array(returnMat),np.array(classLabelVector) trainData,trainLabel = file2matrix("D:\\\\LearningResource\\\\machinelearninginaction\\\\Ch02\\\\datingTestSet2.txt") print(trainData[0:4]) print(trainLabel[0:4]) def autoNorm(dataSet): minVals = dataSet.min(0) maxVals = dataSet.max(0) ranges = maxVals - minVals normDataSet = np.zeros(np.shape(dataSet)) m = dataSet.shape[0] normDataSet = dataSet - np.tile(minVals, (m,1)) normDataSet = normDataSet/np.tile(ranges, (m,1)) #element wise divide return normDataSet, ranges, minVals normDataSet, ranges, minVals = autoNorm(trainData) print(ranges) print(minVals) print(normDataSet[0:4]) print(trainLabel[0:4]) testData = np.array([[0.5,0.3,0.5]]) result = classify0(testData, normDataSet, trainLabel, 5) print(result)

import numpy as np import operator as op from os import listdir def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = np.tile(inX, (dataSetSize,1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 sortedClassCount = sorted(classCount.items(), key=op.itemgetter(1), reverse=True) return sortedClassCount[0][0] def file2matrix(filename): fr = open(filename) returnMat = [] classLabelVector = [] #prepare labels return for line in fr.readlines(): line = line.strip() listFromLine = line.split(\'\\t\') returnMat.append([float(listFromLine[0]),float(listFromLine[1]),float(listFromLine[2])]) classLabelVector.append(listFromLine[-1]) return np.array(returnMat),np.array(classLabelVector) def autoNorm(dataSet): minVals = dataSet.min(0) maxVals = dataSet.max(0) ranges = maxVals - minVals normDataSet = np.zeros(np.shape(dataSet)) m = dataSet.shape[0] normDataSet = dataSet - np.tile(minVals, (m,1)) normDataSet = normDataSet/np.tile(ranges, (m,1)) #element wise divide return normDataSet, ranges, minVals normDataSet, ranges, minVals = autoNorm(trainData) def datingClassTest(): hoRatio = 0.10 #hold out 10% datingDataMat,datingLabels = file2matrix("D:\\\\LearningResource\\\\machinelearninginaction\\\\Ch02\\\\datingTestSet.txt") normMat, ranges, minVals = autoNorm(datingDataMat) m = normMat.shape[0] numTestVecs = int(m*hoRatio) errorCount = 0.0 for i in range(numTestVecs): classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) print((\'the classifier came back with: %s, the real answer is: %s\') % (classifierResult, datingLabels[i])) if (classifierResult != datingLabels[i]): errorCount += 1.0 print((\'the total error rate is: %f\') % (errorCount/float(numTestVecs))) print(errorCount) datingClassTest()
import numpy as np import operator as op from os import listdir def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = np.tile(inX, (dataSetSize,1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 sortedClassCount = sorted(classCount.items(), key=op.itemgetter(1), reverse=True) return sortedClassCount[0][0] def file2matrix(filename): fr = open(filename) returnMat = [] classLabelVector = [] #prepare labels return for line in fr.readlines(): line = line.strip() listFromLine = line.split(\'\\t\') returnMat.append([float(listFromLine[0]),float(listFromLine[1]),float(listFromLine[2])]) classLabelVector.append(listFromLine[-1]) return np.array(returnMat),np.array(classLabelVector) def autoNorm(dataSet): minVals = dataSet.min(0) maxVals = dataSet.max(0) ranges = maxVals - minVals normDataSet = np.zeros(np.shape(dataSet)) m = dataSet.shape[0] normDataSet = dataSet - np.tile(minVals, (m,1)) normDataSet = normDataSet/np.tile(ranges, (m,1)) #element wise divide return normDataSet, ranges, minVals normDataSet, ranges, minVals = autoNorm(trainData) def datingClassTest(): hoRatio = 0.10 #hold out 10% datingDataMat,datingLabels = file2matrix("D:\\\\LearningResource\\\\machinelearninginaction\\\\Ch02\\\\datingTestSet.txt") normMat, ranges, minVals = autoNorm(datingDataMat) m = normMat.shape[0] numTestVecs = int(m*hoRatio) errorCount = 0.0 for i in range(numTestVecs): classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) print((\'the classifier came back with: %s, the real answer is: %s\') % (classifierResult, datingLabels[i])) if (classifierResult != datingLabels[i]): errorCount += 1.0 print((\'the total error rate is: %f\') % (errorCount/float(numTestVecs))) print(errorCount) datingClassTest()

................................................

import numpy as np import operator as op from os import listdir def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = np.tile(inX, (dataSetSize,1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 sortedClassCount = sorted(classCount.items(), key=op.itemgetter(1), reverse=True) return sortedClassCount[0][0] def file2matrix(filename): fr = open(filename) returnMat = [] classLabelVector = [] #prepare labels return for line in fr.readlines(): line = line.strip() listFromLine = line.split(\'\\t\') returnMat.append([float(listFromLine[0]),float(listFromLine[1]),float(listFromLine[2])]) classLabelVector.append(int(listFromLine[-1])) return np.array(returnMat),np.array(classLabelVector) def autoNorm(dataSet): minVals = dataSet.min(0) maxVals = dataSet.max(0) ranges = maxVals - minVals normDataSet = np.zeros(np.shape(dataSet)) m = dataSet.shape[0] normDataSet = dataSet - np.tile(minVals, (m,1)) normDataSet = normDataSet/np.tile(ranges, (m,1)) #element wise divide return normDataSet, ranges, minVals def classifyPerson(): resultList = ["not at all", "in samll doses", "in large doses"] percentTats = float(input("percentage of time spent playing video game?")) ffMiles = float(input("frequent flier miles earned per year?")) iceCream = float(input("liters of ice cream consumed per year?")) testData = np.array([percentTats,ffMiles,iceCream]) trainData,trainLabel = file2matrix("D:\\\\LearningResource\\\\machinelearninginaction\\\\Ch02\\\\datingTestSet2.txt") normDataSet, ranges, minVals = autoNorm(trainData) result = classify0((testData-minVals)/ranges, normDataSet, trainLabel, 3) print("You will probably like this person: ",resultList[result-1]) classifyPerson()
import numpy as np import operator as op from os import listdir def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = np.tile(inX, (dataSetSize,1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 sortedClassCount = sorted(classCount.items(), key=op.itemgetter(1), reverse=True) return sortedClassCount[0][0] def file2matrix(filename): fr = open(filename) returnMat = [] classLabelVector = [] #prepare labels return for line in fr.readlines(): line = line.strip() listFromLine = line.split(\'\\t\') returnMat.append([float(listFromLine[0]),float(listFromLine[1]),float(listFromLine[2])]) classLabelVector.append(int(listFromLine[-1])) return np.array(returnMat),np.array(classLabelVector) def autoNorm(dataSet): minVals = dataSet.min(0) maxVals = dataSet.max(0) ranges = maxVals - minVals normDataSet = np.zeros(np.shape(dataSet)) m = dataSet.shape[0] normDataSet = dataSet - np.tile(minVals, (m,1)) normDataSet = normDataSet/np.tile(ranges, (m,1)) #element wise divide return normDataSet, ranges, minVals def classifyPerson(): resultList = ["not at all", "in samll doses", "in large doses"] percentTats = float(input("percentage of time spent playing video game?")) ffMiles = float(input("frequent flier miles earned per year?")) iceCream = float(input("liters of ice cream consumed per year?")) testData = np.array([percentTats,ffMiles,iceCream]) trainData,trainLabel = file2matrix("D:\\\\LearningResource\\\\machinelearninginaction\\\\Ch02\\\\datingTestSet2.txt") normDataSet, ranges, minVals = autoNorm(trainData) result = classify0((testData-minVals)/ranges, normDataSet, trainLabel, 3) print("You will probably like this person: ",resultList[result-1]) classifyPerson()
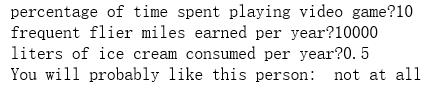
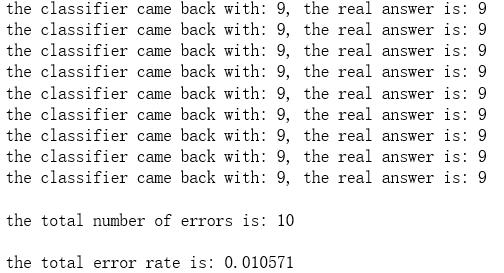
import numpy as np import operator as op from os import listdir def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = np.tile(inX, (dataSetSize,1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 sortedClassCount = sorted(classCount.items(), key=op.itemgetter(1), reverse=True) return sortedClassCount[0][0] def img2vector(filename): returnVect = [] fr = open(filename) for i in range(32): lineStr = fr.readline() for j in range(32): returnVect.append(int(lineStr[j])) return np.array([returnVect]) def handwritingClassTest(): hwLabels = [] trainingFileList = listdir(\'D:\\\\LearningResource\\\\machinelearninginaction\\\\Ch02\\\\trainingDigits\') #load the training set m = len(trainingFileList) trainingMat = np.zeros((m,1024)) for i in range(m): fileNameStr = trainingFileList[i] fileStr = fileNameStr.split(\'.\')[0] #take off .txt classNumStr = int(fileStr.split(\'_\')[0]) hwLabels.append(classNumStr) trainingMat[i,:] = img2vector(\'D:\\\\LearningResource\\\\machinelearninginaction\\\\Ch02\\\\trainingDigits\\\\%s\' % fileNameStr) testFileList = listdir(\'D:\\\\LearningResource\\\\machinelearninginaction\\\\Ch02\\\\testDigits\') #iterate through the test set mTest = len(testFileList) errorCount = 0.0 for i in range(mTest): fileNameStr = testFileList[i] fileStr = fileNameStr.split(\'.\')[0] #take off .txt classNumStr = int(fileStr.split(\'_\')[0]) vectorUnderTest = img2vector(\'D:\\\\LearningResource\\\\machinelearninginaction\\\\Ch02\\\\testDigits\\\\%s\' % fileNameStr) classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3) print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)) if (classifierResult != classNumStr): errorCount += 1.0 print("\\nthe total number of errors is: %d" % errorCount) print("\\nthe total error rate is: %f" % (errorCount/float(mTest))) handwritingClassTest()

.......................................
以上是关于吴裕雄 python 机器学习-KNN算法的主要内容,如果未能解决你的问题,请参考以下文章
吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
吴裕雄 python 机器学习——人工神经网络感知机学习算法的应用