Python基础第14天
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础第14天相关的知识,希望对你有一定的参考价值。
常见模块(1)
一:time模块
import time #--------------------------我们先以当前时间为准,让大家快速认识三种形式的时间 print(time.time()) # 时间戳:1487130156.419527 print(time.strftime("%Y-%m-%d %X")) #格式化的时间字符串:‘2017-02-15 11:40:53‘ print(time.localtime()) #本地时区的struct_time print(time.gmtime()) #UTC时区的struct_time
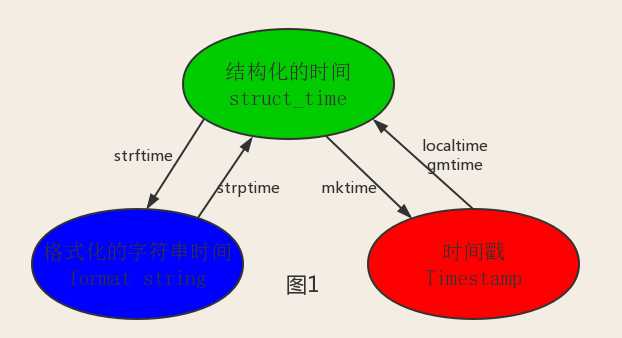
#---将结构化时间转换成时间戳 print(time.mktime(time.localtime())) #--将结构化时间转换成字符串时间 print(time.strftime(‘%Y-%m-%d %X‘,time.localtime())) #--将字符串时间转换成结构化时间 print(time.strptime(‘2016:12:24:17:50:36‘,‘%Y:%m:%d:%X‘))
二:random模块
import random ret=random.random() #(0,1)----float print(ret) print(random.randint(1,3)) #[1,3] print(random.randrange(1,3)) #[1,3) print(random.choice([1,‘23,[4,5]‘])) print(random.sample([1,‘23‘,[4,5]],2)) print(random.uniform(1,3)) item=[1,3,4,7,9] random.shuffle(item) print(item)
例子:随机验证码
#验证码 import random def v_code(): ret=‘‘ for i in range(5): num=random.randint(0,9) alf=chr(random.randint(65,122)) s=str(random.choice([num,alf])) ret+=s return ret print(v_code())
三:os模块 os模块是与操作系统交互的一个接口


import os print(os.getcwd()) #获取当前工作目录,即当前python脚本工作的目录路径 os.chdir(‘test1‘) #改变当前脚本工作目录;相当于shell下cd print(os.getcwd()) print(os.chdir(‘..‘)) #返回上一层 print(os.getcwd()) os.curdir os.pardir print(os.getcwd()) os.makedirs(‘test1/test2‘) os.removedirs(‘test1/test2‘) os.mkdir(‘test11‘) os.rmdir(‘test11‘) # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname print(os.listdir(‘test1‘)) os.remove(‘XXX‘) os.rename(‘test1‘,‘test2‘) print(os.stat(‘test2‘)) print(os.sep ) # 输出操作系统特定的路径分隔符,win下为"\\\\",Linux下为"/" print(os.linesep) #输出当前平台使用的行终止符,win下为"\\t\\n",Linux下为"\\n" print(os.pathsep) #输出用于分割文件路径的字符串 win下为;,Linux下为:(环境变量) print(os.name) #输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘ print(os.system(‘dir‘)) print(os.environ) print(os.path.split(‘test2‘)) #将path分割成目录和文件名二元组返回 print(os.path.dirname(‘test2‘)) #返回path的目录 print(os.path.basename(‘test2‘)) # 返回path最后的文件名 print(os.path.dirname(‘rE:\\python\\python3\\python_x\\day22\\test2‘)) os.path.exists(path) #如果path存在,返回True;如果path不存在,返回False a=‘E:\\python\\python3\\python_x‘ b=‘day22\\test2‘ print(os.path.join(a,b)) #路径拼接
print(os.stat(‘test2‘))

四:sys模块
1 sys.argv 命令行参数List,第一个元素是程序本身路径 2 sys.exit(n) 退出程序,正常退出时exit(0) 3 sys.version 获取Python解释程序的版本信息 4 sys.maxint 最大的Int值 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 sys.platform 返回操作系统平台名称
进度条例子:
#进度条 import sys,time for i in range(10): sys.stdout.write(‘#‘) #在屏幕显示相应内容 sys.stdout.flush() time.sleep(0.1)
五:json模块 --- 重要
首先,和eval区别。eval:通常用来执行一个字符串表达式,并返回表达式的值。可以把list tuple dict string相互转换,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了。
其次,注意点。json 不认单引号,一律识别为双引号
import json dic={‘name‘:‘alex‘} #{“name”:“alex”} # i=7 # ‘7‘ # s=‘hello‘ #‘“hello”‘ # l=[11,22] #"[11,22]" data=json.dumps(dic) # i=json.dumps(i) # print(i) print(data) #{“name”:“alex”} print(type(data)) #<class ‘str‘>
采用json.dumps json.loads 方法写入数据并读取数据
import json dic={"name":"alex"} dic_str=json.dumps(dic) f=open(‘new_hello‘,‘w‘) f.write(dic_str) f_read=open(‘new_hello‘,‘r‘) data=json.loads(f_read.read()) print(data) print(type(data))
两个加不加s的区别:
import json dic={"name":"alex"} f=open(‘new_hello‘,‘w‘) # # json.dump(dic,f) data=json.dumps(dic) f.write(dic) f_read=open(‘new_hello‘,‘r‘) data=json.loads(f_read.read()) # data=json.load(f_read)
只要符合json规范(双引号),就可以拿处理。json.dumps的功能就是讲其类型转换成json规范处理,所以:
#json_test {"name":"alevx"} #json&pickle.py import json with open("json_test","r")as f: data=f.read() data=json.loads(data) print(data[‘name‘]) #alevx
六:pickle模块
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
import pickle dic = {‘name‘:‘alex‘,‘age‘:23,‘sex‘:‘male‘} print(type(dic)) j = pickle.dumps(dic) print(type(j)) #<class ‘bytes‘> f=open(‘序列化对象_pickle‘,‘wb‘) f.write(j) #等价于pickle.dump(dic,f)
import pickle
f=open(‘序列化对象_pickle‘,‘rb‘)
data=pickle.loads(f.read()) #等价于data=pickle.load(f)
print(data[‘age‘])
七:xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
标签语言分为:自闭合标签、非自闭合标签
对于标签的遍历 for i n root:
print(i.tag) 对象遍历
print(i.attrib) 属性遍历
print(i.text)文本遍历
xml的格式如下,就是通过<>节点来区别数据结构的,遍历xml文档,对文档的增删改查
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() print(root.tag) #遍历xml文档 for child in root: print(child.tag, child.attrib) for i in child: print(i.tag,i.text) #只遍历year 节点 for node in root.iter(‘year‘): print(node.tag,node.text) #--------------------------------------- import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #修改 for node in root.iter(‘year‘): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes") tree.write("xmltest.xml") #删除node for country in root.findall(‘country‘): rank = int(country.find(‘rank‘).text) if rank > 50: root.remove(country) tree.write(‘output.xml‘)
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() print(root.tag) #遍历xml文档 for child in root: print(child.tag, child.attrib) for i in child: print(i.tag,i.text) #只遍历year 节点 for node in root.iter(‘year‘): print(node.tag,node.text) #--------------------------------------- import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #修改 for node in root.iter(‘year‘): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes") tree.write("xmltest.xml") #删除node for country in root.findall(‘country‘): rank = int(country.find(‘rank‘).text) if rank > 50: root.remove(country) tree.write(‘output.xml‘)
以上是关于Python基础第14天的主要内容,如果未能解决你的问题,请参考以下文章
代码随想录算法训练营第14天 | ● 理论基础 ● 递归遍历 ● 迭代遍历 ● 统一迭代